







Map所有人都不会陌生,在工作和学习中算是最常见的几种数据结构之一了,其中比较常用的应该说就是HashMap了。HashMap可以说是面试常客,几乎所有的面试官都会向你询问有关HashMap的问题,不过不知道大家有没有仔细问过自己一个问题,为什么HashMap的面试出镜率这么高?作为Map的一种实现方式,HashMap有什么过人之处吗?这也是我接下来希望和大家分享的关键点。
关于hashmap实在有太多可研究的内容,我也会写成许多篇文章和大家分享,今天这篇文章会先从最基本的名字开始说起,HashMap之所以用这个名字,其实就已经很清楚的给我们传递了信息,首先,这是一个map,其次,具体分类呢?是hash。看到这里首先各位自己首先思考一下,天天说hashmap,如果现在我问你,到底什么是hash?它在hashmap里有哪些用途?你是否能准确的说出来,有这样一种言论,说覆盖hashCode()的话也应该覆盖equals(),这句话适用于什么情况?
我们先来看一下,到底什么是hash。在百科上可以找到这样一段解释:
“就是把任意长度的输入通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。”
这段话可以简单理解为就是将一个输入通过hash算法进行输出,输出值就是hash值(hash翻译为散列,音译哈希),但是不同的输入可能得到相同的输出,所以hash值不能作为确定唯一性的条件。当然了有兴趣的同学可以去查一下hash值的计算方式,不过这就是另一方面的知识了,篇幅和能力有限,目前暂时不讨论这一点,但是我们现在已经清楚了,hash值就是一个将输入转化为某种固定输出值的算法。当然了,具体到java语言中,我们可以看到Object类中的hashCode()方法,而Object类是所有类的父类,那么也就意味着,所有类都可以调用hashCode方法,也就是说所有的对象,都可以在使用的过程中得到一个int型hash值。那么我们继续来讨论第二个问题,既然所有的对象都有一个hash值,那么在hashmap中我们究竟拿这个hash值来做什么?
查看hashmap的put方法可以看到调用了putVal()方法,该方法的第一个参数是hash(key),显然是对key对象取hashcode,计算方法是(h = key.hashCode()) ^ (h >>> 16),这个算法是什么意思呢?key.hashCode()很好理解,关键是在于这个h>>>16,在java中,>>>是代表无符号右移,^代表异或,也就是说这里将key的hashcode右移了十六位,然后与原来的hashcode异或运算。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}int型大小是四字节32位,也就是说无符号右移16位后,高16位全部补零,如下图所示,由于0和其他数异或依然是0,所以也就是说高16位的值并没有改变,低16位按位异或,得到新的hash值
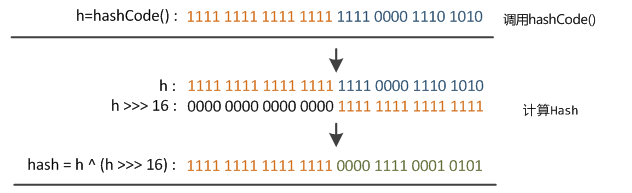
得到hash值后进入putVal()方法中,根据(n - 1) & hash计算该key在底层数组中的位置,n代表了当前数组的length,用 n - 1 的值与上面得到的hash值按位与操作。值得注意的是,当new出来一个hashmap的时候,并没有立刻初始化,而是等到第一次调用put方法时判断,如果当前map中的数组为空,则进行初始化,这里也是一个懒加载的思想,直到使用时才初始化,而不是从一开始就初始化好,而默认初始化的值可以很清楚的看到是16,为什么是16呢?因为把16转化为二进制的话就是10000,我们刚刚提到的计算key在数组中的位置时使用了(n - 1) & hash,此时 n - 1 = 15,转换为二进制就是1111,而任何数和 1 作与运算都得其本身,例如 1010 & 1111 = 1010,所以说这里的按位与其实和 % 取余运算是一样的,而位运算要比取余效率高一些,此时算出来的值就是当前key在底层数组中的位置下标,这样我们通过hash值就找到了这个key应该所在的位置。所以说hash值最大的作用就是帮助我们找到key应该在map中所在的位置。计算出位置就结束了吗?当然不是,前面也提到过,两个对象不管是否相同,有可能会产生相同的hash值,那么此时两个对象就会“挤”在同一个位置上,那么此时又该怎么处理呢?首先我们来看看putVal源码是怎么写的,其中暂时先删除了有关红黑树部分的代码:
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
}可以清晰的看到,计算出key所在位置 i 后得到了 i 位置上的元素 p,当p的hash值等于当前key的hash值时,也就是我们常说的hash冲突时,会通过 == 和 equals进行判断,有过map使用经验的同学都知道,先put(a,1),然后再put(a,2),那么此时get(a) = 2,回到这个判断上来说,p.key == key就是简单的判断两次key是否为同一个对象,这个比较好理解,那么后面的key.equals(k)到底又做了什么呢?
其实在Object类中,equals()方法只不过是return (this == obj),所以说,如果key的类如果没有覆盖equals方法,那么就相当和 == 一样,所以说如果我们的类中不覆盖equals方法的话,那其实equals方法和 == 判断效果是一样的。提到了覆盖equals方法,那不知道各位同学有没有听过这样的说法:一般如果类覆盖了hashcode(),那么一般也要覆盖equals()方法。乍听起来好像hashCode()和equals()有关联,其实首先要澄清一点,这两个方法完全没有一点关系!就是两个毫不相干的方法,一个用于求hashcode,而另一个用于比较两个类。那么这种说法又是从何而来呢?这主要看这个类是否会被用于“创建类的散列表”,通俗一点讲就是这个类会不会被当作例如hashtable,hashmap等散列表中的key值。
public class Student {
private String name;
private int score;
public Student(String name, int score) {
super();
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
public int hashCode() {
return this.name.hashCode() + this.score;
}
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
if (this == obj) {
return true;
}
Student student = (Student) obj;
return this.name.equals(student.getName()) && this.score == student.getScore();
}
}
public class StudentHashTest {
public static void main(String[] args) {
Student s1 = new Student("a", 100);
Student s2 = new Student("a", 100);
Map<Student, String> map = new HashMap<>();
map.put(s1, "s1");
map.put(s2, "s2");
System.out.println(map.size());
}
}运行上面的代码输出结果应该是1,也就是说s1和s2作为key放入map中后被看作是相等的,根据前面的hashmap代码分析,可以知道这是因为s1和s2的hashCode()返回了一样的值造成了哈希冲突,再调用equals()方法也返回了true,所以并没有放入map两个key。而在Student类中,我们确实也覆盖了hashCode方法,返回值是name的hashcode + score,对s1和s2来说,name都是字符串a,score都是100,返回的hashcode肯定相同,同时我们也覆盖了equals方法,判断如果name和score都相等,那么就认为这两个student是相等的。如果注释掉hashcode和equals其中任何一个方法,再次运行代码的话输出结果都是2了,说明hashmap已经无法判断出s1和s2是相等的,理由和上面一样我就不再赘述了。这也就是所谓的如果类覆盖了hashcode(),那么一般也要覆盖equals()方法,并不是这两个方法有关系,而是因为在和hashcode有关的集合类中,是通过hashcode确定存储位置,然后通过equals去判断同位置上的元素是否相等,若想保证相等就要遵循:
1.如果两个对象相等,那么它们的hashCode()值一定相同。
2.如果两个对象hashCode()相等,它们并不一定相等。
说了这么多,也算是从我个人的角度上理解一下hashmap之所以名字中带有hash的含义,虽然平时我们经常使用它,但是仅仅是使用并不能完全理解,而且也会错过编程语言中很多美妙的东西,网上关于hashmap的文章数不胜数,但是希望我的文章能给大家带来一些不一样的感受,由于这是本人的第一篇技术博客,难免有瑕疵甚至是错误,如果有发现,欢迎各位的批评和指正。















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









