







 本文介绍了一个基于隐马尔可夫模型(HMM)和条件随机场(CRF)的命名实体识别(NER)系统实现。该系统应用于简历数据集中的人名、组织等实体的识别,使用BIOES标注法并提供了详细的模型训练与评估步骤。
本文介绍了一个基于隐马尔可夫模型(HMM)和条件随机场(CRF)的命名实体识别(NER)系统实现。该系统应用于简历数据集中的人名、组织等实体的识别,使用BIOES标注法并提供了详细的模型训练与评估步骤。
基于HMM和CRF的命名实体识别
前段时间,上了机器学习课程,然后老师布置了个大作业,使用具体的模型应用到具体的任务
我写了一个基于HMM和CRF的命名实体识别代码。在此总结一下。
数据集
数据集是从网上获取的一个简历数据集,存储在/data目录中,分为三个文件,分别是train.char.bmes、test.char.bmes、dev.char.bmes文件。三个文件统一用BIOES标注方法标注。如下图所示,每一行为一个中文字符及其对应的标记标注,中文字符和标记用空格隔开。句子与句子之间用换行符分割。
train.char.bmes有将近10万个中文字符,test.char.bmes、dev.char.bmes分别有大约1.5万个中文字符。数据集中的实体类别包括NAME(名字)、CONT(国籍)、EDU(学历)、TITLE(头衔)、ORG(组织)、RACE(民族)、PRO(专业)、LOC(籍贯)。
命名实体识别的任务是同时准确识别命名实体的边界和类别

HMM
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐马尔可夫随机生成的状态的序列,称为状态序列;每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列。
特别注意:隐马尔可夫模型是生成模型,先生成状态序列,然后由状态序列生成观测序列。即是先P(Z),再P(O|Z),所以拟合的是P(O,Z),也就是联合概率分布。
具体的代码流程
-
极大似然估计,估计出隐马尔可夫模型的三个参数初始概率矩阵、发射概率矩阵、状态转移概率矩阵
-
维特比算法,维特比算法对输入的观测序列进行解码,得到状态序列(也就是我们要的标签序列)
-
结果评估, 调用seqeval库。
classification_report(real, predict, digits=6) #classification_report有三个参数 #第一个参数,是真实的序列标签(必须二维序列,即多个句子) #第二个参数,是预测出的序列标签(必须二维序列,即多个句子) #第三个参数,是输出的小数点位数
如果没学习过隐马尔可夫模型,建议认真阅读李航老师的统计学习方法
CRF
CRF的原理,参考李航老师的统计学习方法
具体代码流程(使用的是sklearn_crfsuite中的CRF库)
-
定义基本的模型
self.model = CRF(algorithm=algorithm, c1=c1, c2=c2, max_iterations=max_iterations, all_possible_transitions=all_possible_transitions) #algorithm是选择的梯度下降算法,可以选择lbfgs -
提取特征、进行训练
def word2features(sent, i): """抽取单个字的特征""" word = sent[i] prev_word = '<s>' if i == 0 else sent[i-1] next_word = '</s>' if i == (len(sent)-1) else sent[i+1] # 使用的特征: # 前一个词,当前词,后一个词, # 前一个词+当前词, 当前词+后一个词 features = { 'w': word, 'w-1': prev_word, 'w+1': next_word, 'w-1:w': prev_word+word, 'w:w+1': word+next_word, 'bias': 1 } return features def sent2features(sent): """抽取序列特征""" return [word2features(sent, i) for i in range(len(sent))] -
结果评估,同样调用的是seqeval库
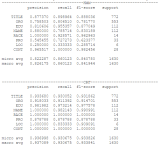
结果截图
运行方式,直接运行main.py, 可能需要装一些库

















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









