







摘要
这篇论文主要研究了2D人体姿态估计的高效架构设计。姿态估计在以人为中心的视觉应用中发挥着关键作用,但由于基于HRNet的先进姿态估计模型计算成本高昂(每帧超过150 GMACs),难以在资源受限的边缘设备上部署。因此,该论文提出了一个核心问题:在轻量模型上,高分辨率+多分支结构是否真正必要。为了解决这一问题,论文作者设计了一个渐进收缩实验,发现高分辨率分支对于低计算区域的模型是多余的。基于这一发现,他们提出了LitePose,这是一种用于自底向上姿态估计的高效架构。LitePose采用了单分支设计,并引入了两种技术来增强其容量,包括fusion deconv head和 large kernel conv。这种设计不仅降低了计算量,而且在实际应用中取得了良好的效果——在移动平台上,与之前的最先进的高效姿势估计模型相比,LitePose将延迟降低了多达5.0倍,而不会牺牲性能,推动了边缘实时多人姿势估计的前沿。
目录
1. Scale-Aware Multi-branch Architectures(尺度感知多分支架构)
2. Redundancy in High-Resolution Branches(高分辨率分支的冗余)
3. Fusion Deconv Head: Remove the Redundancy(冗余消除)
4. Mobile Backbone with Large Kernel Convs
5. Single Branch, High Efficiency(单分支节点,更高的效率)
四、Neural Architecture Search(NAS)——自动化机器学习技术
一、介绍
人体姿势估计旨在从图像中预测每个人的关键点位置。典型的人体姿势估计模型可以分为自顶向下和自底向上。自顶向下范式首先通过额外的人员检测器检测人员,然后对每个检测到的人员执行单人姿势估计。相比之下,自底向上范式首先预测无身份的关键点,然后将它们分组成人员。由于自底向上范式不涉及额外的人员检测器,并且不需要针对图像中的每个人重复运行姿势估计模型,因此它更适合于边缘实时多人姿势估计。
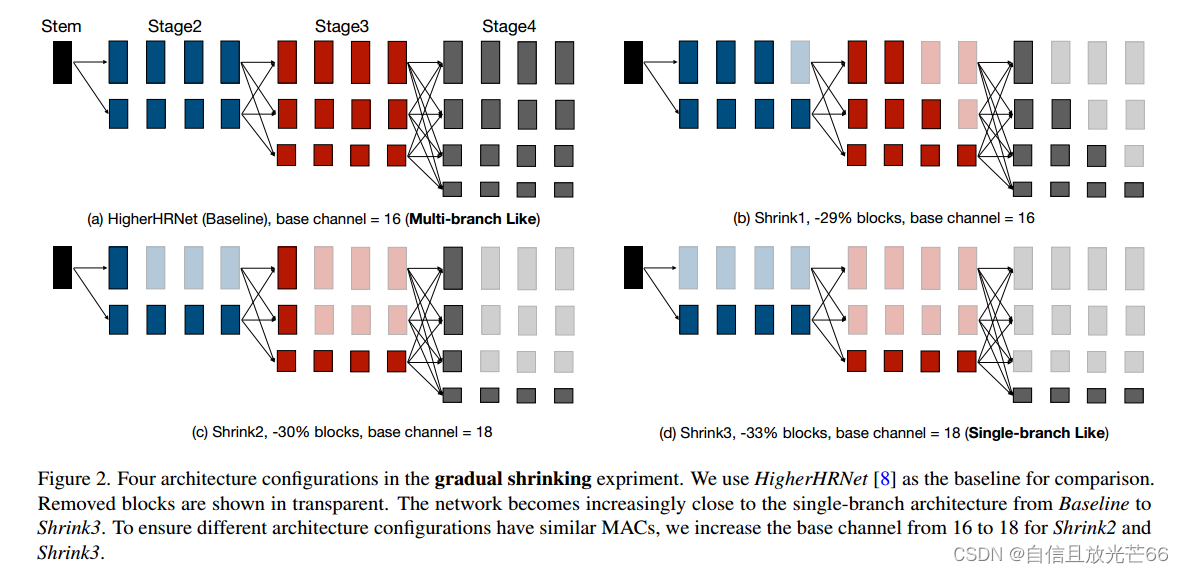
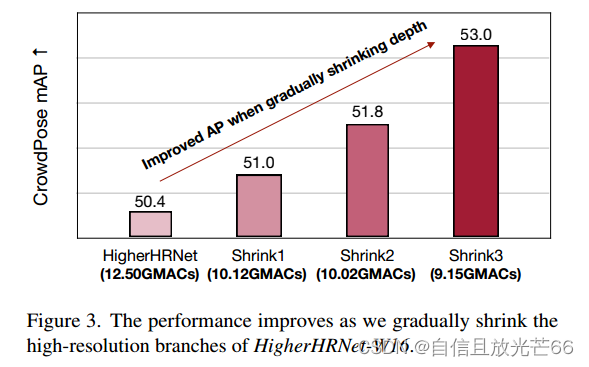
然而,现有的自底向上姿势估计模型主要集中在高计算区域。例如,HigherHRNet在CrowdPose数据集上取得了最佳性能,但其需要超过150GMACs的计算量,不适合于资源受限的边缘设备,设计低计算成本的模型同时保持良好性能至关重要。之前的研究表明,在高计算区域中,保持高分辨率表示对于获得良好的自底向上姿势估计性能至关重要。然而,目前尚不清楚这一结论是否适用于低计算区域的模型。为了回答这个问题,我们通过逐渐缩小高分辨率分支的深度,构建了一个“桥梁”来连接代表性的多分支架构HigherHRNet和单分支架构(见图2)。而后发现对于低计算区域中的模型,随着高分辨率分支深度的缩小,性能会提高(见图3)。受到这一启发,作者设计了一种用于高效自底向上姿势估计的单分支架构LitePose。在LitePose中,我们使用修改后的MobileNetV2[43]骨干网络,并进行了两项重要改进以有效处理单分支设计中的尺度变化问题:fusion deconv head和 large kernel conv。融合反卷积头去除了高分辨率分支中多余的细化操作,因此允许以单分支方式进行尺度感知多分辨率融合。与图像分类不同的是,作者发现large kernel conv在自底向上姿势估计中提供了明显更显著的改进。最后,作者应用神经架构搜索(NAS)来优化模型架构并选择适当的输入分辨率。
经过在 CrowdPose 和 COCO 数据集上的大量实验,LitePose 的有效性得到了充分验证。在CrowdPose 数据集上,LitePose 实现了2.8倍的MACs(乘加操作次数)减少和高达5.0倍的延迟减少,同时性能表现也很好。在COCO数据集上,与 EfficientHRNet 相比,LitePose 实现了2.9倍的延迟减少,并且提供了更好的性能表现。这些结果证明了LitePose在保持高性能的同时,显著降低了计算成本,使其在边缘设备上实现实时多人姿态估计成为可能。
本论文做出的贡献可以总结为以下几点:
1. 本研究通过设计渐进收缩实验,证明了高分辨率分支在低计算区域的模型中的非必要性
2. 本文提出了LitePose,这是一种高效的自下而上姿态估计架构。同时还引入了两种技术来增强LitePose的性能,包括fusion deconv head和 large kernel conv。
3. 在Microsoft COCO[28]和CrowdPose[26]这两个基准数据集上进行了大量实验,证明了该方法的有效性:与最先进的基于HRNet的模型相比,LitePose实现了高达2.8倍的MACs(乘加操作次数)减少,延迟减少高达5.0倍。
二、相关工作
2D Human Pose Estimation
二维人体姿态估计旨在确定人体的关键点和部位,主要有自上而下和自下而上两种框架。虽然基于HRNet的多分支架构在自下而上姿态估计中取得了先进的结果,但由于其计算量大,难以在边缘设备上部署。因此,本工作致力于提高自下而上框架的效率,故遵循最先进的基于HRNet的方法,并借鉴了关联嵌入技术进行关键点分组。
Model Acceleration.(模型加速)
除了直接设计高效的模型外,另一种模型加速的方法是压缩现有的大型模型。一些方法旨在去除连接和卷积滤波器中的冗余,同时,还有一些方法专注于网络的量化。此外,还提出了几种AutoML方法,实现自动化模型压缩和加速过程。最近,Yu等人设计了LiteHRNet用于自上而下姿态估计,而本文则专注于自下而上的范式研究。Neff等人提出了EfficientHRNet用于高效的自下而上姿态估计。他们将EfficientNet中的复合缩放思想应用于HigherHRNet,实现了1.5倍的MACs减少,然而,当严格约束计算时,该方法仍会面临性能急剧下降的问题。而本文将MACs减少率提高到5.1倍,并在移动平台上实现了比EfficientHRNet高达5.0倍的延迟减少。
Neural Architecture Search.(神经网络架构搜索)
NAS在图像分类任务中取得了成功,通过共享权重的一次性NAS方法可以提高搜索效率。后又尝试采用了一次性搜索所有(once-for-all)的方法,自动修剪通道内的冗余并选择适当的输入大小。总之,在本研究中,我们利用NAS方法进一步提升了LitePose的性能,实现了更高的MACs减少率和延迟减少,并显著提升了模型精度(搜索的模型实现了高达+3.6AP的显著改进。)。
三、重新思考设计高效模型
多分支网络在自底向上姿势估计任务中取得了巨大成功。它们的代表作HigherHRNet使用多分支架构来帮助融合多分辨率特征,从而显著缓解了尺度变化问题。由于这一特性,多分支架构优于单分支架构,并取得了最先进的结果。但是,大多数这些方法在高计算量条件下才能达到最佳性能,比如使用超过150GMACs。针对实际的边缘应用,研究低计算量下高效的人体姿势估计方法是非常重要的。在本节中,首先介绍了基于HRNet的多分支架构以及它们如何处理尺度变化问题。然后指出了在计算受限情况下高分辨率分支中的冗余问题,并通过逐步缩小来加以说明。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









