







我们在进行zynq开发过程中往往无法避免pl与ps端的互联问题,AXI_DMA在pl与ps端高速数据传输中很常用。由于其独特的AXI总线机制以及寄存器控制方式,我们在使用AXI_DMA进行多路数据传输的过程中耗费了较多时间精力。为了让同行们在遇到此类问题时少走弯路,我们将在这篇文章中简单介绍AXI_DMA的简单模式使用方法,在ps端有查询(poll)和中断两种控制方法,本文采用的是查询模式。
- AXI_DMA控制原理介绍
在正式进行过程介绍前,我们首先需要了解AXI_DMA的一些基本原理,最详细最原始的资料肯定是赛灵思官方的手册。这里简单以我自己的了解做个概述:
首先我们要指导它是通过什么控制的,又是通过什么来传输数据的,下图是官方给的结构图
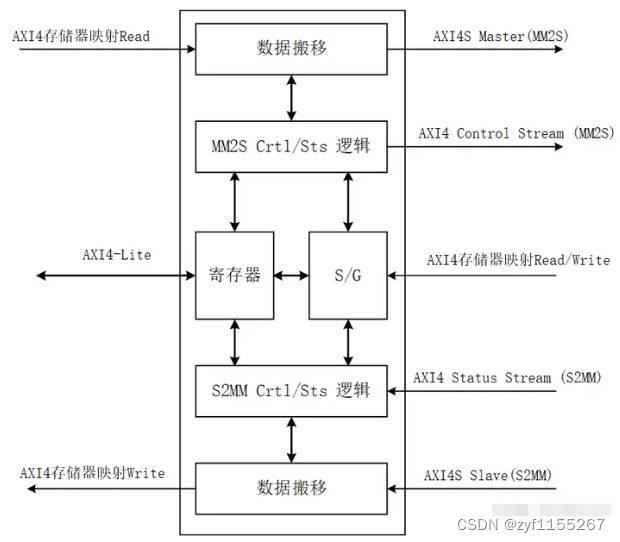
上图可以看出DMA就是通过AXI4总线来进行数据搬移,分为两个方向S2MM和MM2S,也就是数据流到内存以及内存到数据流。重点是如何控制的,图中也可以看到实际是PS端通过AXI4-Lite轻量型总线来读写内部寄存器控制的。
实际上AXI_DMA分为控制CR寄存器以及状态SR寄存器,简而言之就是一个你主动往里面写控制命令,一个是通过读取其中寄存器地址的值知道DMA的工作状态。
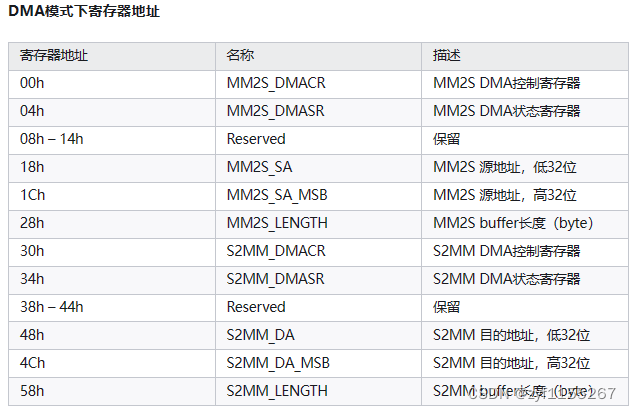
有哪些寄存器地址,这些寄存器地址的值又代表什么意义呢?
这里只罗列直接模式下的寄存器说明
地址:
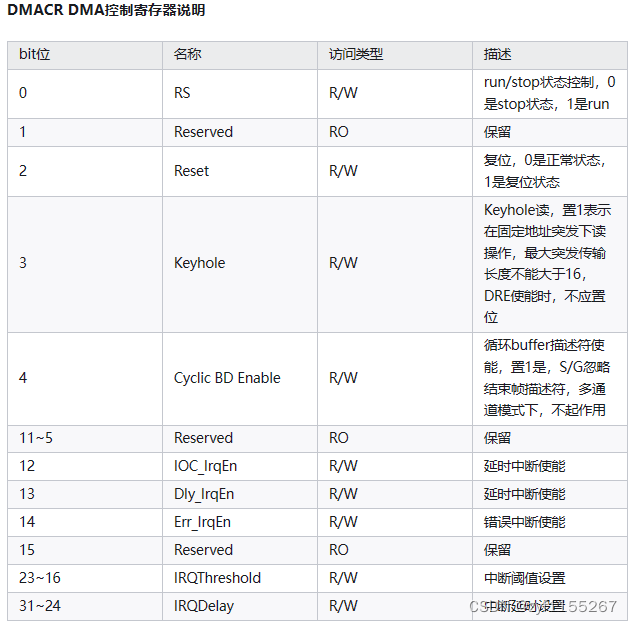
控制寄存器说明:
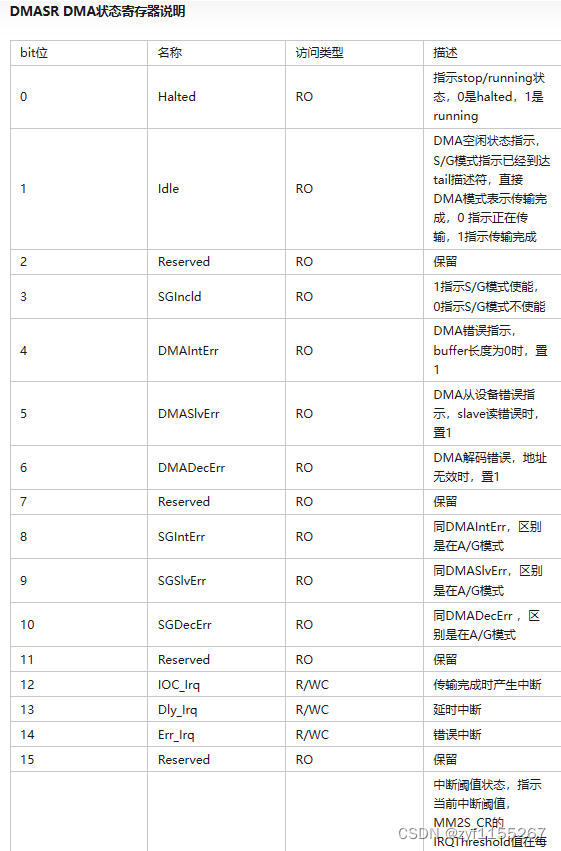
状态寄存器说明(往往用于调试):

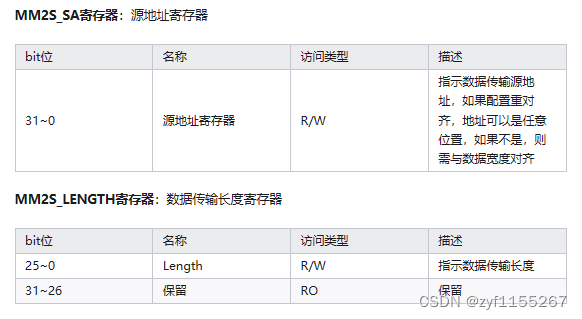
另外还有两个比较重要的就是源地址寄存器和数据传输长度寄存器,用来控制数据的传输地址以及传输长度:
2.PL端Block Design模块搭建以及IP设置
了解完基本控制原理后,相信大家更关注的还是具体实验方法。那么就以我们项目为例来介绍一下:
下图为AXI_DMA ip 核设置界面: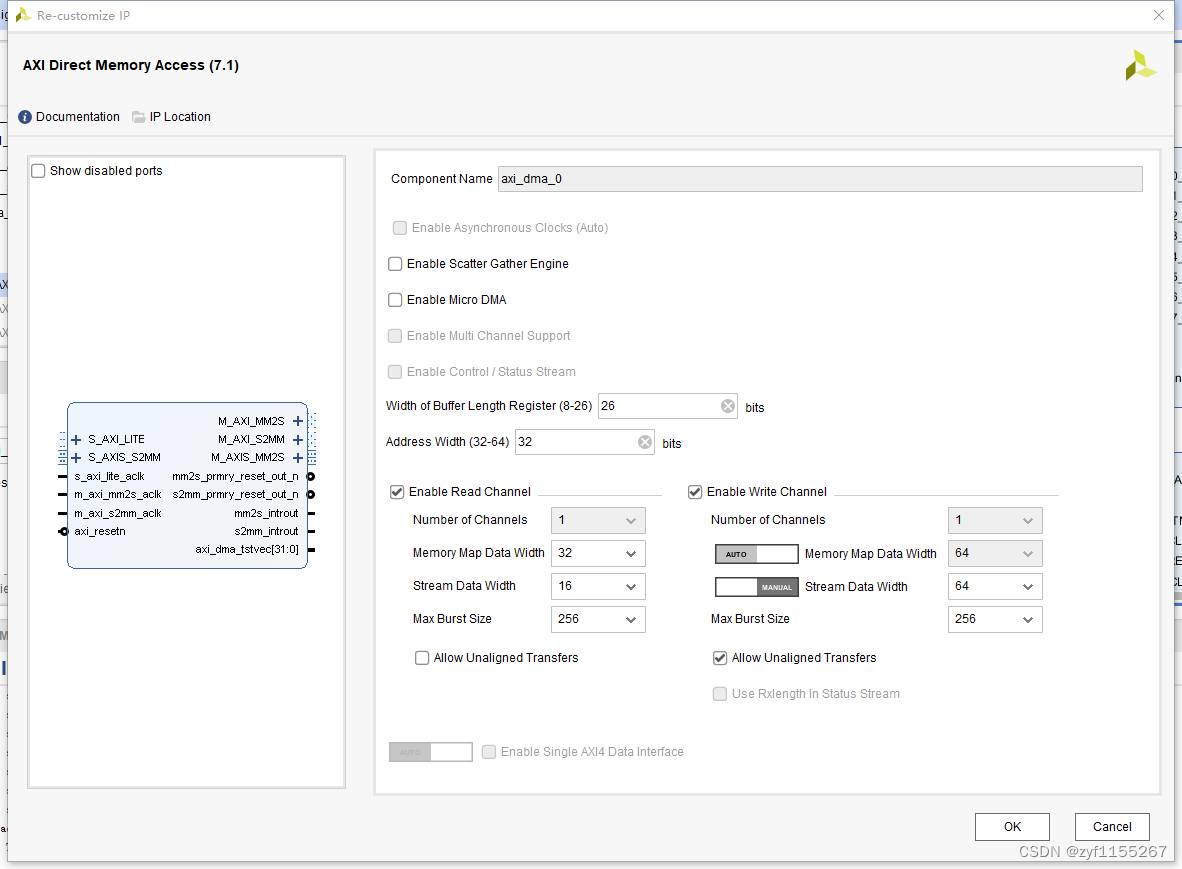
直接传输模式下设置较为简单,值得注意的是width of buffer length register是用来设置长度寄存器的位宽的,这个决定了一次传输最多传输的数据量,比如我这边设置成26,那么一次传输最多传2^26个字节。其他设置也就读写数据位宽还有突发长度等,这里不做过多介绍。
下图为BD图形化界面的连线:
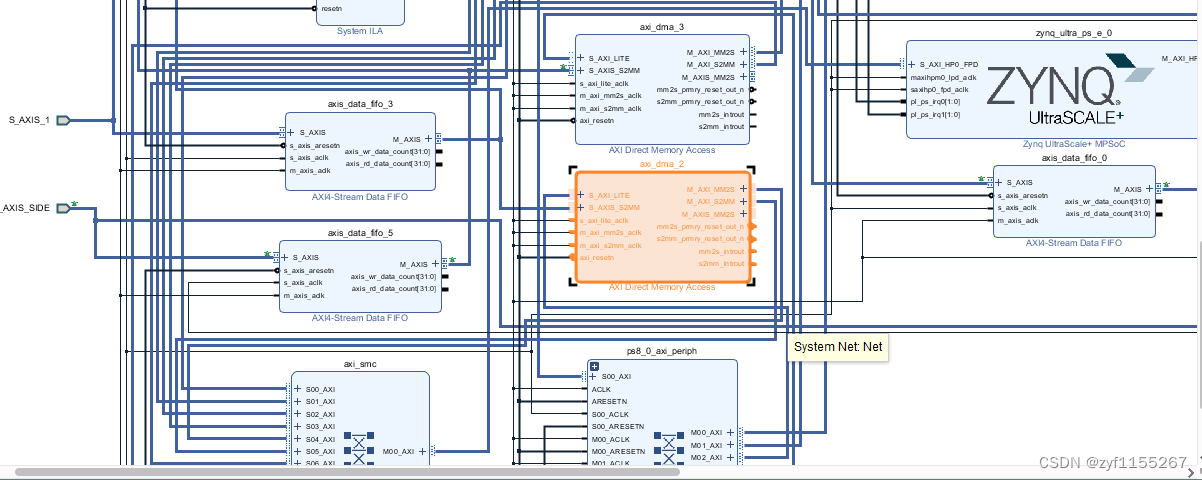
ZYNQ引出的一路128位的HP接口通过smartconnect ip核与四个DMA同时连接,此外ZYNQ还引出一条轻量型总线与DMA接口相连用于PS端读写控制寄存器。PL端数据通过axi4-stream data fifo转换成流数据连接到DMA的相应接口。
3.PS端控制
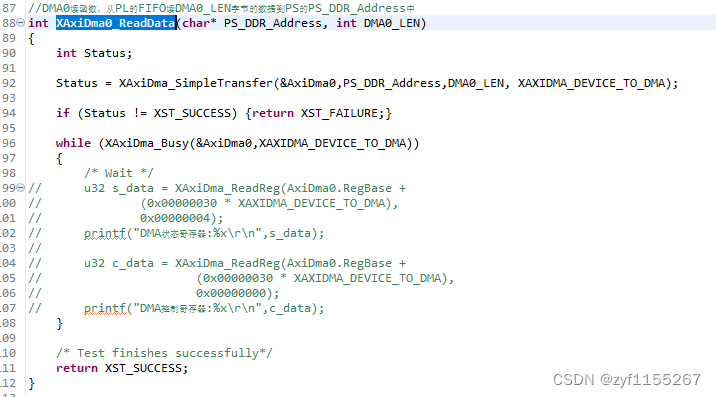
这是我们写的一个DMA传输函数,实际上很简单所用到的就仅仅是XAxiDma_SimpleTransfer这一函数,仅需要配置DMA设备号,传输目的地址,数据长度以及传输方向就够了。
XAxiDma_Busy这个函数纯属个坑,仅用于单个DMA单次传输时的调试(读写状态寄存器),在多路DMA连续传输过程中,加这个代码就会卡住,后面会讲原因。
4.多路数据传输问题及解决
在四路数据传输过程中,通过添加ila我们发现仅有一路数据正常传输,其余路的ready信号一直不拉高(仅当ready信号和tvalid信号同时为高的时候数据才会有效传输)。
我们一开始采用的方式是freertos系统多线程,每个线程给他配置一个DMA通路传输,发现四个DMA还是只有一路是通的,只不过由原来一直是DMA0通,变成了随机某个DMA通。
后来采用AMP多核处理,每个处理器分别配置一个DMA,想着这样总能同时配置了吧,结果不出所料,四路都通了,但有时候会出现系统不稳定的情况比如某个CPU一直不进去,这就很让人头疼了。
为了解决DMA多路传输的问题,本人查阅了大量相关资料
首先从为什么在四核分别配置四个DMA能够同时传输这一问题着手,通过博客:
基于AXI smartconnect的多主单从的DDR读写-CSDN博客 了解到,PL端BD图形化界面自动生成的AXI smartconnect ip核可以实现一个或多个主机通过AXI总线和一个或多个从机进行数据读写,并自动分配总线,内部支持缓存。这也就是为什么在一条总线的基础上可以实现四路数据传输。
既然PL端已经解决了总线竞争的问题,那么按道理来说一个cpu就可以实现四路DMA的配置,并且可以同时传输数据。那么为何在一个cpu中以多线程的方式同时配置四路DMA会出现问题呢?
结合之前出现的多线程有时部分线程进不去的问题,怀疑是DMA配置的线程部分没进去。既然多线程可能会出现问题,那么是否能够不采用多线程的方式进行配置呢?
通过查阅Zynq学习笔记-AXI DMA (Simple)简介和示例 – Dorapocket (lgyserver.top)
AXI DMA IP核使用说明 - 知乎 (zhihu.com)
Zynq-linux PL与PS通过DMA数据交互_zynq使用dma实现ps与pl端的数据交互-CSDN博客
等原理性博客, PS对AXI_DMA的控制实际都是读写寄存器,给它的寄存器里面配置完地址、长度等信息后就不需要再管了,DMA会直接跳过cpu与DDR进行读写。结合ps读写寄存器的时间应该很短,我们完全没必要搞多线程同时配置四个DMA,每次一帧数据过来的时候先后配置四个DMA应该是可行的。也就是把四次DMA配置从原先各自的线程改为都放到一个函数里面。
按照这个思路改了之后,通过ILA发现还是只有一个DMA传输
于是又观看了正点原子的一些相关视频:
SDK篇_67~71_ZYNQ中AXI DMA简介与使用【ZYNQ】+【DMA】+【Vivado】_哔哩哔哩_bilibili
发现正点原子里面与黑金的例程不同,仅一个simpletransfer函数就能传输,不需要判断是不是busy状态,也就是代码里的这部分在正点原子的视频里并没有用到:
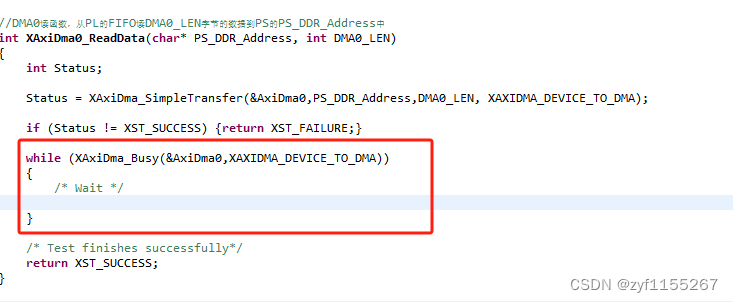
查看了这部分代码的实际意义后发现这部分的代码实际就是用来查看DMA状态的(通过读取DMA的状态寄存器),如果DMA在搬运,那么就会一直卡在这个循环里面不出来,也就不会进入到其他代码(比如配置DMA2)导致其他DMA无法启动配置。实际上,我们并不需要等到DMA空闲,一次传输结束与否是由PL端的tlast控制的,ps端只需要保证结束前一帧的数据后开始配置新的一次传输即可。Ready信号代表着PS端是否配置启动了DMA,拉高说明启动了,拉低没启动。就PL侧而言只有当ready和valid同时拉高才会传输数据。
删除这部分代码后,四路DMA同时正常运行。
感谢前人的努力和分享,想着看了这么多也得有点输出,因此写下这篇博客希望能对同行有所帮助。















 1306
1306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









