







之前分享过一次我在学习Python的笔记,Python笔记【一】,最近有些新的收获,分享一下;
个人博客:https://blog.csdn.net/zyooooxie
random.sample() 随机不重复的数
工作中,有时候是需要在数据库手动去造些数据的,有些字段类似 order_id ,一般都是不重复的(在不考虑有退款等其他异常的情况下),若要造超多数量、不重复的order_id,该如何来做?
推荐使用random.sample();实际 在遇到生成随机整数的时候,我第一反应就是random.randint(),我们对比下:

循环random.randint(),实际会有重复的元素,而使用 range() + random.sample() 不会重复
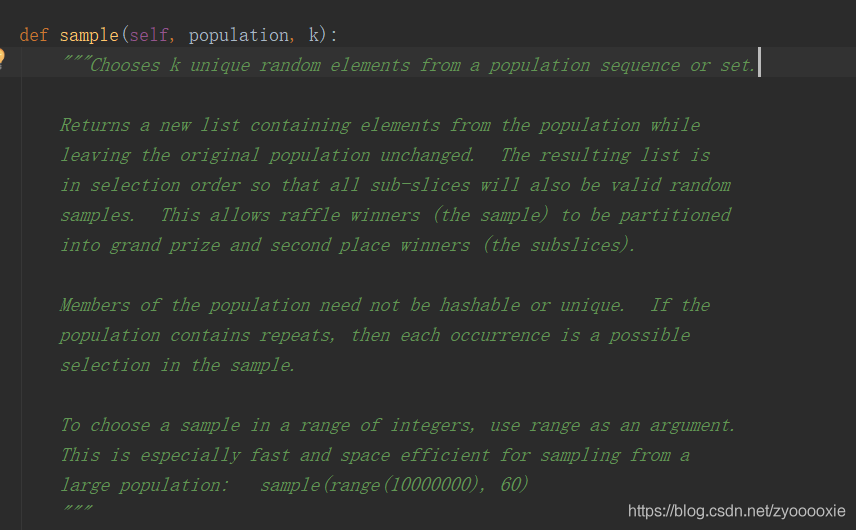
【请注意:这个用法 sample(range(10000000), 60) 是本身就给了一个没有重复元素的range】
【若给了一个有重复元素的population,实际筛选出来的元素还是 会重复的】
a = [1, 1, 1, 1, 23, 213, 1322, 41, 111, 'zyoo1111ooxie', 'zyooooxie', 213, 1323, 213, 'zyooooxie', 'zyooooxie', 'zyooooxie', 1322, 41, 111, 'csdn', 'zyooooxie']
print(a)
print(random.sample(a, 7))
print({(ele, a.count(ele))for ele in a})
执行结果如下:

实际有set 后有10个,我就单单取7个,可结果是有3个相同的1;
rfind() 从右边开始查找 第一次出现的位置

说2个好笑的: 1. 上图我标注的 Return the highest index in S where substring sub is found。 看到 有地方介绍 rfind()是 会返回某字符串最后一次出现的位置,我的第一想法:从右边开始 最后一次,那不就是 从左边 首次出现吗?好像不对呀。 然后才明白:那儿的意思是 从左边最后一次,不正是我想的从右边 first嘛 【和注释也对得上】。 2. 既然有rfind() ,是不是也有lfind() ,为啥没有啊? = =
字符串find() != -1
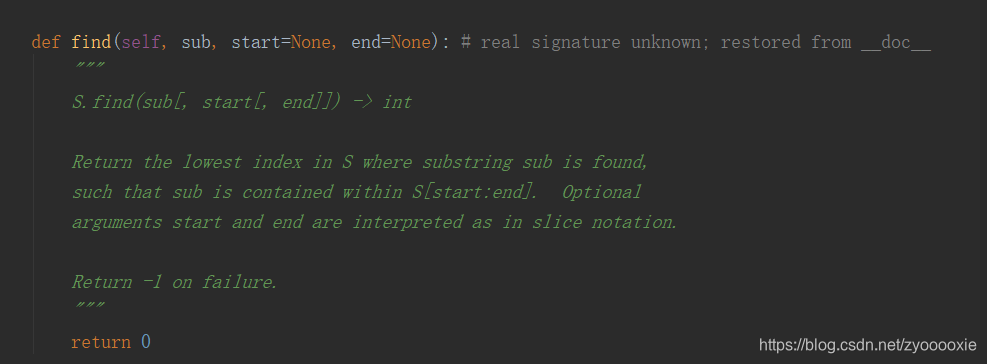
find() 检测字符串中是否包含子字符串 sub,如果指定 start 和 end 范围,则在指定范围内 检查是否包含。不传start 和end,是从最开始-左侧开始find, 这不正是lfind() ?
这儿主要是想说下 :Return -1 on failure
因为 我往往不能确定子字符串的index,反而使用 str_xx.find('xxxx) != -1 会更多。
if file_str.find(‘文件名’)【错误用法】
"""
@blog: https://blog.csdn.net/zyooooxie
@qq: 153132336
@wechat: 153132336
"""
file_path = '一直会被删除的不存在.png'
if file_p.find('一直会被删除的') and os.path.exists(file_path):
os.remove(file_p)
当file_path =‘abc.png’,实际file_p.find() 结果是-1,bool(-1) 是True
if file_p.find('一直会被删除的') == 0 and os.path.exists(file_path):
os.remove(file_p)
if file_p.find('一直会被删除的') != -1 and os.path.exists(file_path):
os.remove(file_p)
字符串开头、结尾 startswith() \endwith()
有时候确定 某字符串是否以某子字符串为开头、结尾,就要用到startswith()、 endswith();
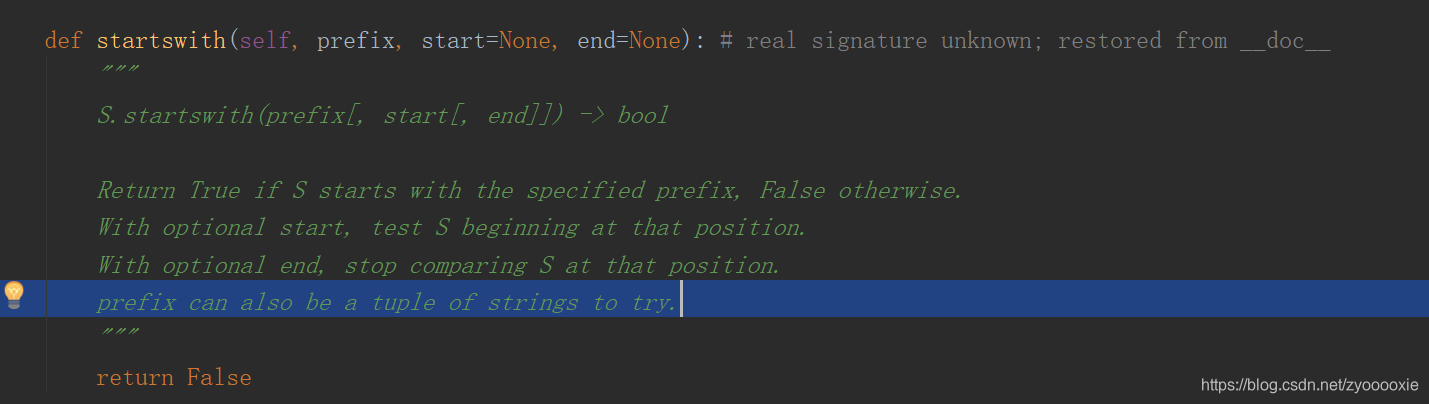
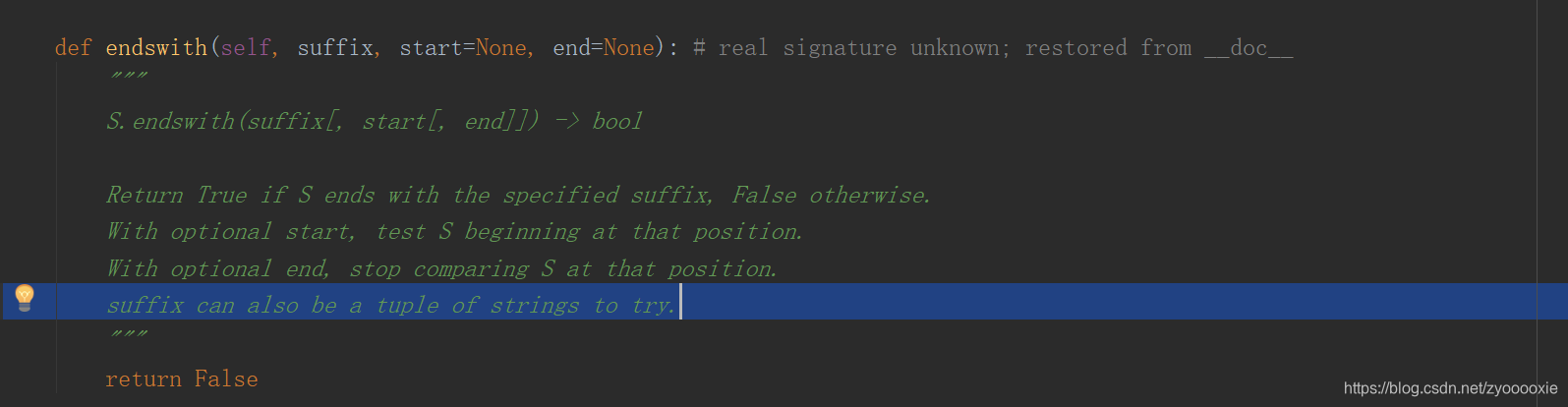
这儿要说的是上面2图 鼠标所在那行 prefix can also be a tuple of strings to try 。suffix传参一个 全都为str的tuple,可以用来判断N个元素。

字符串 replace() 可控替换次数
先看下源码: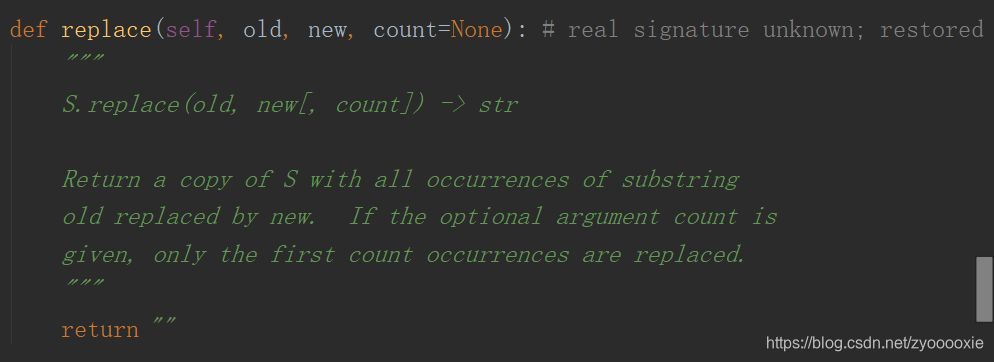
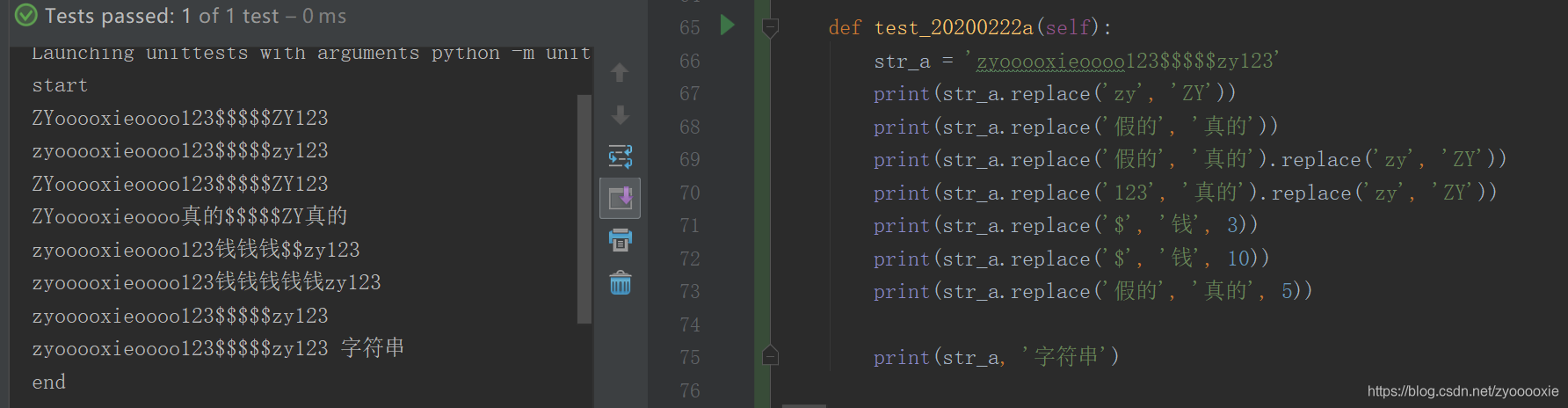
我是很喜欢用replace() 的,总结:
1.replace() 返回一个字符串的副本,其中出现的旧字符(old)被替换为新的(new),可选地将替换数count限制为最大值;
2.不传count,会把当前所有符合的old都替换为new ;
3.old的参数不存在,不报错,生成的新字符串和原 string 保持一致 ;
4.可以多次replace() ;
5.replace 不会改变原 string 的内容;
6.count 传超过 实际替换次数,也不会报错;
list.index() == -1 【错误用法】
标题是错误的(我在遇到第2次,才反应过来);
一直以来,访问列表的最后一个元素,我用的是list[-1],不知不觉就和list.index()用乱了。
list.index(obj):从列表中找出某个值第一个匹配项的索引位置
我之所以用list.index(obj) == -1, 是想当然认为 list的最后一个元素的索引是-1; 但实际索引是从0开始【大于等于0】;
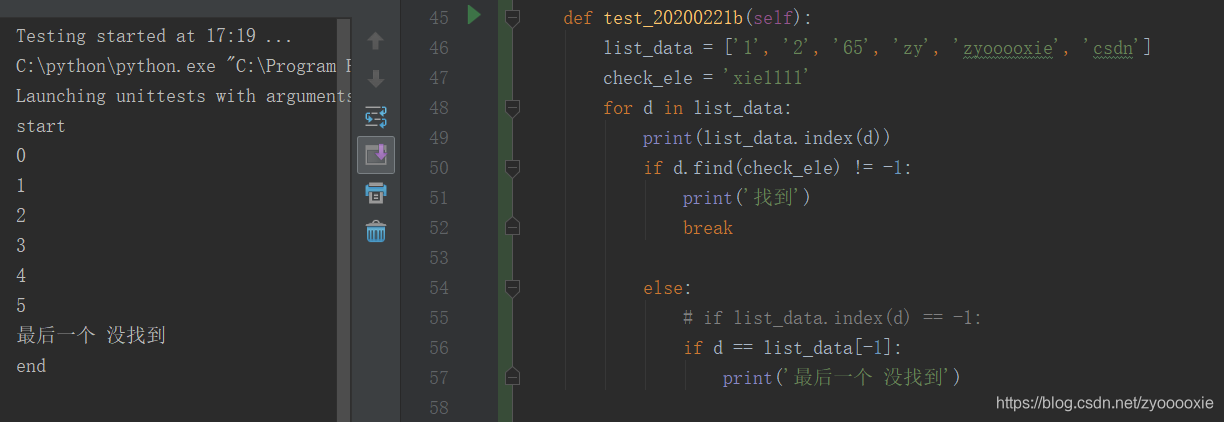
def test_20200221b(self):
list_data = ['1', '2', '65', 'zy', 'zyooooxie', 'csdn']
check_ele = 'xie1111'
for d in list_data:
print(list_data.index(d))
if d.find(check_ele) != -1:
print('找到')
break
else:
if list_data.index(d) == -1:
# if d == list_data[-1]:
print('最后一个 没找到')
拿这个用例来做个说明,想看下list_data下面哪个元素可以find(check_ele),如果找到就结束for循环;如果最后那个元素也不符合,就 print没找到;
实际执行结果:

为什么没有 print‘没找到’? 实际就是 else里面 if判断出了问题【列表的索引 不会等于 -1】;















 8997
8997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









