







 研究通过引入COT嵌入改进了大语言模型在社交媒体立场检测任务中的性能,解决了隐式立场混淆和立场标签幻觉问题,特别是在Tweet-Stance和Presidential-Stance数据集上实现了最先进的结果。
研究通过引入COT嵌入改进了大语言模型在社交媒体立场检测任务中的性能,解决了隐式立场混淆和立场标签幻觉问题,特别是在Tweet-Stance和Presidential-Stance数据集上实现了最先进的结果。

摘要
社交媒体上的立场检测对于大型语言模型(llm)来说是一个挑战,因为在线对话中出现的俚语和口语通常包含非常隐含的立场标签。思维链(COT)提示最近被证明可以提高立场检测任务的性能,从而缓解了这些问题。然而,COT 提示仍然难以解决隐式立场识别问题。这一挑战的出现是因为在模型熟悉俚语和与不同主题相关的不断发展的知识之前,许多样本最初很难理解,所有这些都需要通过训练数据获得。在本研究中,我们通过引入COT嵌入来解决这个问题,通过嵌入COT推理并将其集成到传统的基于roberta的立场检测管道中,提高了COT在立场检测任务中的性能。我们的分析表明,1) 文本编码器可以利用带有微小错误或幻觉的 COT 推理,否则会扭曲 COT 输出标签。 2) 当样本的预测严重依赖于特定领域的模式时,文本编码器可能会忽略误导性的 COT 推理。我们的模型在从社交媒体收集的多个姿态检测数据集上实现了 SOTA 性能。
1引言
检测文本相对于特定主题的立场对于许多 NLP 任务至关重要(Hardalov 等人,2022)。在 Twitter 等社交媒体平台上检测立场提出了独特的挑战,因为新兴知识和口语语言模式可能使得在没有额外上下文的情况下很难检测立场。例如,考虑图 1 中显示的顶部推文。该推文没有直接提及唐纳德·特朗普,因此在没有进一步背景的情况下很难进行分类,例如 Twitter 上的特朗普支持者如何广泛支持选民欺诈宣传。这些新兴知识对于具有知识界限的LLMs来说很难理解,只能通过观察训练集中类似标记的样本来辨别。
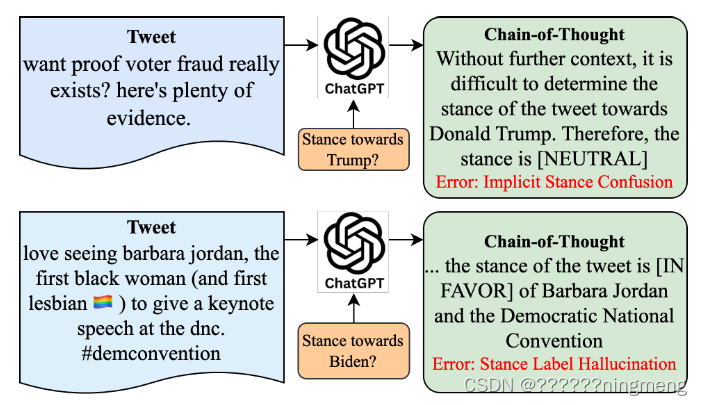

图1:思维链推理模型常犯的错误。隐式立场混淆是指大语言模型无法理解对立场主题的隐式引用。在上面的例子中,ChatGPT应该预测这条推文是支持特朗普的。在这种情况下,立场标签幻觉指的是大语言模型使用标签空间来争论错误观点的情况。在这个例子中,推理是正确的,但是ChatGPT对错误的主题使用了[In FAVOR]标签。
解决这个问题的一种方法是采用具有广泛世界知识的模型。例如,最近的研究表明,在立场检测中使用ChatGPT可以显著提高性能(Zhang等人,2023a,b)。不幸的是,大语言模型(例如,ChatGPT, Llama)在理解Twitter数据中复杂的立场关系方面仍然存在许多问题。在这项研究中,我们强调了最先进的思维链(COT)提示方法在立场检测中的两个问题。1)隐式立场混淆:如图1所示,即使采用COT推理等高级提示策略,大语言模型仍然难以理解隐式推文立场(Wei et al., 2023)。2)立场标签幻觉:大语言模型容易产生幻觉,这导致它们输出正确的推理,但对于错误的立场主题(参见图1示例)。即使大语言模型分析了正确的主题,他们也容易错误地使用提供的标签空间,产生准确但结构不良的输出。
在本研究中,我们通过引入思维链(COT)嵌入来
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









