






LeNet学习笔记一
视频地址:【Pytorch框架与经典卷积神经网络与实战】 https://www.bilibili.com/video/BV1e34y1M7wR/?p=51&share_source=copy_web&vd_source=7d0117001ba4a138b2924a4a9803d9f5
第一步:搭建模型
文件名称:model.py
import torch # 导入pytorch,是深度学习模型框架
from torch import nn # torch 包中导入 nn 模块。nn 模块是 PyTorch 中用于构建神经网络的核心模块之一
from torchsummary import summary # torchsummary是一个用于查看模型结构的工具
class LeNet(nn.Module): # 定义了一个名为LeNet的类,这是我们自定义的神经网络模型。它继承自nn.Module,这是PyTorch中所有神经网络模型的基类
def __init__(self):
super(LeNet,self).__init__()
# 在类的初始化函数中,调用了父类(nn.Module)的初始化函数。
self.c1 = nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5,padding=2) # self.c1: 第一个卷积层,输入通道数为1,输出通道数为6,卷积核大小为5x5,padding为2
self.s2 = nn.AvgPool2d(kernel_size=2,stride=2) # self.s2: 第一个平均池化层,池化核大小为2x2,步幅为2
self.c3 = nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5) # self.c3: 第二个卷积层,输入通道数为6,输出通道数为16,卷积核大小为5x5
self.s4 = nn.AvgPool2d(kernel_size=2,stride=2) # self.s4: 第二个平均池化层,池化核大小为2x2,步幅为2
self.sig = nn.Sigmoid() # 激活函数将线性变成非线性。
# 全连接层
self.flatten = nn.Flatten()
self.f5 = nn.Linear(in_features=400,out_features=120) # 全连接层,输入特征400,输出特征120
self.f6 = nn.Linear(in_features=120,out_features=84) # 全连接层,上一层的输出是这一层的输入也就是120,输出84,是下一个全连接层的输入
self.f7 = nn.Linear(in_features=84,out_features=10) # 全连接层,输入特征84,输出10,也就是10个分类。
def forward(self,x): # 前向传播,依次经过我们上面的卷积层,池化层等
x=self.sig(self.c1(x)) # 进入卷积层之后要进激活函数
# print(x.shape) #查看输入的x,这里是图片的shape
x=self.s2(x)
x=self.sig(self.c3(x))
x=self.s4(x)
x=self.flatten(x)
x=self.f5(x)
x=self.f6(x)
x=self.f7(x)
return x # 返回值 x
if __name__== "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 判断当前运行环境是CPU还是GPU
print(device)
model = LeNet().to(device) # 实例化LeNet模型,并将其移动到相应的设备上
print(summary(model,input_size=(1,28,28))) # 使用torchsummary库中的summary函数打印出模型的结构信息,包括各层的参数数量等
第二步:训练模板代码
文件名称:model_train.py
import copy
import time
import pandas as pd
import torch
from torchvision.datasets import FashionMNIST
from torchvision import transforms #用来处理数据集
import torch.utils.data as Data
import numpy as np
import matplotlib.pyplot as plt #画图
from model import LeNet # 从上一个创建好的模型文件model.py里面导入 LeNet ,注意,model.py和train_model.py要放在一个文件夹下面,方便使用。
import torch.nn as nn
#加载数据集函数
# train_val_data_process() 函数用于加载并预处理 FashionMNIST 数据集,并将其划分为训练集和验证集。然后创建 DataLoader 对象用于批量加载数据
def train_val_data_process():
train_data = FashionMNIST(root='./data',
train=True,
transform=transforms.Compose([transforms.Resize(size=28), # 将图片的大小调整为28*28
transforms.ToTensor()]), # 将图像转换为 PyTorch 的张量类型,方便后面的应用
download=True) #有数据就不再次下载,没有数据就会下载
train_data, val_data = Data.random_split(train_data, [round(0.8*len(train_data)), round(0.2*len(train_data))])
train_dataloader = Data.DataLoader(dataset=train_data,
batch_size=128,
shuffle=True,
num_workers=4) #4线程
val_dataloader = Data.DataLoader(dataset=val_data,
batch_size=128, #batch_size 就是用来指定每个批次中包含的样本数量的参数
shuffle=True, #随机打乱
num_workers=4) #4线程
return train_dataloader, val_dataloader
##模型训练的函数,train_model_process() 函数用于训练模型。在函数内部,首先进行一些初始化操作,包括定义优化器、损失函数、将模型加载到设备等
def train_model_process(model,train_dataloader,val_dataloader,num_epochs):
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) #Adm优化器,学习率是0.001,梯度下降法
criterion = nn.CrossEntropyLoss() #分类用交叉熵损失函数
model = model.to(device) #将模型放到训练设备当中
best_model_wts = copy.deepcopy(model.state_dict()) #将最好的模型的参数保存下来
#初始化参数
#最高准确度
best_acc=0.0
train_loss_all = []#训练集损失函数列表
val_loss_all = [] # 验证集损失函数列表
train_acc_all = [] #训练集所有的准确度列表
val_acc_all = [] #验证集所有的准确度列表
#当前时间
since=time.time()
# 训练模型的核心循环,遍历每个 epoch 和每个 batch,进行前向传播、计算损失、反向传播、更新参数等操作,并计算训练集和验证集的损失和准确率
for epoch in range(num_epochs): #打印训练信息
print("Epoch {}/{}".format(epoch,num_epochs-1))
print("-"*10)
#初始化参数值
#训练集损失函数
train_loss = 0.0
train_corrects = 0 #训练集准确度
val_loss = 0.0 #验证集损失函数
val_corrects = 0#验证集准确度
train_num = 0#训练集样本数量
val_num = 0#验证集样本数量
for step,(b_x, b_y) in enumerate(train_dataloader):
#加载数据时为输入数据增加通道维度
b_x = b_x.to(device)
print(b_x.shape)
#print(type(b_y)) # 打印 b_y 的数据类型,发现是int类型
#print(b_y)
b_y = torch.LongTensor(b_y)
b_y = b_y.to(device)
print(b_y.shape)
model.train() #将模型设置为训练模式
#前向传播,输入为一个batch,输出为一个batch中对应的预测
output = model(b_x)
#查找每一行中对应的最大的行标
pre_lab = torch.argmax(output, dim=1)
loss = criterion(output, b_y)
#将梯度初始化为0,防止梯度累积
optimizer.zero_grad()
#反向传播计算
loss.backward()
#根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数的作用
optimizer.step()
#对损失函数进行累加
train_loss += loss.item() * b_x.size(0)
#如果预测正确,则准确度train_corrects+1
train_corrects += torch.sum(pre_lab == b_y.data)
#当前用于训练的样本数量
train_num += b_x.size(0)
for step,(b_x,b_y) in enumerate(val_dataloader):
#将特征放入到验证设备中
b_x=b_x.to(device)
#将标签放入到验证设备中
b_y = torch.LongTensor(b_y)
b_y = b_y.to(device)
#设置模型为评估模式
model.eval()
#前向传播过程,输入为一个batch,输出为一个batch中对应的预测
output = model(b_x)
#查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
#计算每一个batch的损失函数
loss = criterion(output, b_y)
#对损失函数进行累加
val_loss += loss.item()*b_x.size(0)
#如果预测正确,则准确度加1
val_corrects += torch.sum(pre_lab==b_y.data)
#当前用于验证的样本数量
val_num += b_x.size(0)
#计算并保存每一次迭代的loss值和准确率
#计算并保存训练集的loss值
train_loss_all.append(train_loss / train_num)
# 计算并保存训练集的准确率
train_acc_all.append(train_corrects.double().item() / train_num)
# 计算并保存验证集的loss值和准确度
val_loss_all.append(val_loss / val_num)
val_acc_all.append(val_corrects.double().item() / val_num)
print("{} train loss:{:.4f} train acc: {:.4f}".format(epoch,train_loss_all[-1],train_acc_all[-1]))
print("{} val loss:{:.4f} val acc: {:.4f}".format(epoch,val_loss_all[-1],val_acc_all[-1]))
#P50_训练模型代码_最优模型保存,视频地址:https://www.bilibili.com/video/BV1e34y1M7wR?p=50
#寻找最高准确度的权重
if val_acc_all[-1] > best_acc:
#保存当前最高的准确度
best_acc = val_acc_all[-1]
#保存当前最高准确度时模型的参数
best_model_wts = copy.deepcopy(model.state_dict())
#训练耗费时间
time_use = time.time() - since
print("训练和验证耗费的时间{:.0f}m{:.0f}s".format(time_use//60, time_use%60))
#选择最优参数,加载最高准确率下的模型参数
# model.load_state_dict(best_model_wts)
torch.save(best_model_wts, 'best_model.pt')
train_process = pd.DataFrame(data={"epoch": range(num_epochs),"train_loss_all": train_loss_all,
"val_loss_all": val_loss_all,
"train_acc_all": train_acc_all,
"val_acc_all": val_acc_all})
return train_process
#P51:loss和acc图的绘制,视频地址:https://www.bilibili.com/video/BV1e34y1M7wR?p=51
def matplot_acc_loss(train_process):
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.plot(train_process["epoch"],train_process.train_loss_all,'ro-',label="train loss")
plt.plot(train_process["epoch"],train_process.val_loss_all,'bs-',label="val loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("loss")
plt.subplot(1,2,2)
plt.plot(train_process["epoch"],train_process.train_acc_all,'ro-',label="train loss")
plt.plot(train_process["epoch"],train_process.val_acc_all,'bs-',label="val_loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("acc")
plt.show()
if __name__ == "__main__":
LeNet = LeNet() #将模型实例化
train_dataloader, val_dataloader = train_val_data_process()
train_process = train_model_process(LeNet, train_dataloader, val_dataloader, 20)
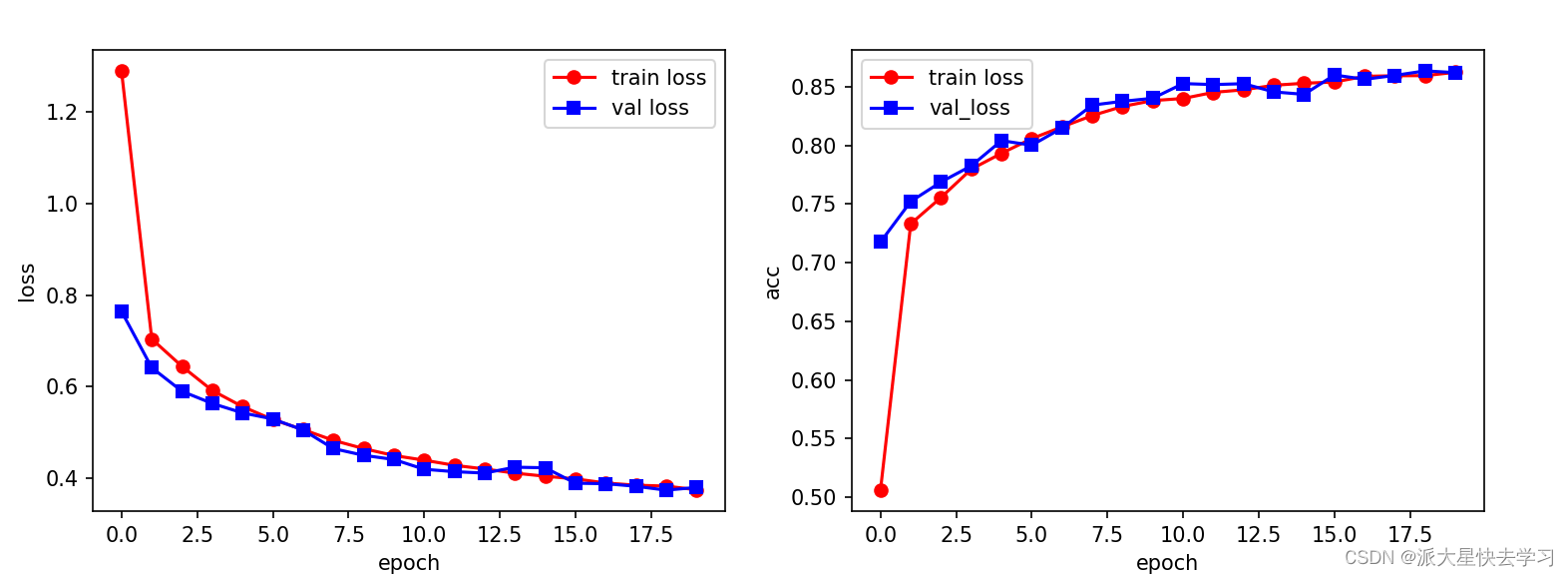
matplot_acc_loss(train_process)结果图:
我在学习中的疑惑
1.什么是实例化?
GPT3.5的回答:
在编程中,实例化是指根据类创建对象的过程。在面向对象编程中,类是一种抽象的数据类型,描述了对象的属性和行为。当我们需要使用类创建具体的对象时,就会进行实例化操作。
在Python中,通过调用类的构造函数来实现实例化。例如,在上述代码中,通过 model = LeNet() 这行代码,我们实例化了一个LeNet类的对象,即创建了一个LeNet模型的实例。这个实例可以调用类中定义的方法(例如前向传播方法),也可以访问类中定义的属性(例如各层的参数)
还是不太理解,所以问了一个通俗的解释:
在程序中,类就是这个设计图纸,它定义了对象的特征和行为。当我们需要使用这个类创建一个具体的对象时,就像在工厂里生产一辆汽车一样,我们就会进行实例化操作。
举个例子,假设我们有一个类叫做Dog,描述了狗的特征和行为,比如颜色、品种、叫声等等。那么当我们需要创建一个具体的狗对象时,就需要实例化这个类,类似于在工厂里生产一只狗。这样我们就可以根据需要创建多个不同的狗对象,它们都有各自的特征和行为,但都是基于相同的Dog类所创建的。
那么我的理解就是我们创建了一个模型LeNet这个类,这个类里面包含了LeNet的特征,参数,函数,但是当我们想要使用这个模型,真的将其用起来的时候就需要将其实例化。
2.torch.nn 是什么?有什么功能?
2.1torch.nn 是什么
from torch import nn
这行代码的意思是从 torch 包中导入 nn 模块。nn 模块是 PyTorch 中用于构建神经网络的核心模块之一
2.2torch.nn 中的功能
torch.nn 提供了构建神经网络所需的各种组件:
-
神经网络层(Layers):这些是构成神经网络的基本组成部分,如全连接层、卷积层、池化层等。例如,
nn.Linear表示全连接层,nn.Conv2d表示二维卷积层,nn.MaxPool2d表示二维最大池化层等等。 -
激活函数(Activation Functions):激活函数是神经网络中的非线性变换,用于增加网络的非线性拟合能力。PyTorch 提供了各种激活函数,如 Sigmoid、ReLU、Tanh 等。这些函数可以在
torch.nn.functional模块中找到,例如torch.nn.functional.sigmoid、torch.nn.functional.relu。 -
损失函数(Loss Functions):损失函数用于衡量模型预测与实际标签之间的差异。PyTorch 提供了各种常见的损失函数,如均方误差损失、交叉熵损失、负对数似然损失等。这些函数通常在
torch.nn模块中直接使用,例如nn.MSELoss、nn.CrossEntropyLoss。 -
优化器(Optimizers):优化器用于更新神经网络的参数,以最小化损失函数。PyTorch 提供了各种优化器,如随机梯度下降(SGD)、Adam、RMSprop 等。这些优化器通常在
torch.optim模块中使用,例如torch.optim.SGD、torch.optim.Adam。
2.3举个例子使用 nn 构建神经网络
在实际使用中,我们可以通过继承 nn.Module 类并重写 forward 方法来定义自己的神经网络模型。nn.Module 提供了一些方法来管理神经网络的结构和参数。
然后,我们可以在 forward 方法中定义神经网络的结构,包括各种层、激活函数等。最后,我们将实例化的层对象组合在一起,并在 forward 方法中将输入数据传递给这些层,从而完成整个神经网络的前向传播过程。
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.layer1 = nn.Linear(in_features=784, out_features=128)
self.layer2 = nn.Linear(in_features=128, out_features=10)
def forward(self, x):
x = self.layer1(x)
x = nn.functional.relu(x)
x = self.layer2(x)
return x
这样,我们就定义了一个简单的神经网络模型,其中包含两个全连接层。在 forward 方法中,我们首先通过第一个全连接层 self.layer1 进行线性变换,然后应用 ReLU 激活函数,最后通过第二个全连接层 self.layer2 得到最终的输出
3.激活函数
3.1激活函数用在哪里?
激活函数通常被应用在神经网络的全连接层、卷积层、循环层等层的输出之后。这样做的目的是为了引入非线性特性,使得神经网络能够学习和表示更加复杂的函数关系。
具体来说:
-
全连接层(Linear)后面: 在全连接层中,每个神经元的输出是由输入特征与对应的权重相乘后求和得到的,如果没有激活函数,那么整个全连接层的计算结果仍然是线性的。因此,为了引入非线性,激活函数通常被应用在全连接层的输出之后。
-
卷积层(Convolutional)后面: 在卷积神经网络中,卷积层的输出也需要通过激活函数进行非线性变换。这是因为卷积操作本身是线性的,如果不引入非线性变换,那么整个卷积神经网络也会是线性的,无法处理复杂的数据关系。
-
循环层(Recurrent)后面: 对于循环神经网络(RNN)和长短期记忆网络(LSTM)等循环层,也需要通过激活函数引入非线性,以便更好地捕捉序列数据中的时间相关性和复杂模式。
因此,激活函数通常被应用在神经网络的各种层的输出之后,以实现网络的非线性变换.
3.2激活函数的作用
总结如下:
-
引入非线性: 一个神经网络如果没有激活函数,那么整个网络就是一个线性模型,无论有多少层,其整体效果都相当于单层网络。而引入了非线性的激活函数后,神经网络才具备了拟合复杂函数的能力。激活函数的非线性特性允许神经网络学习和表示非线性关系,从而提高模型的表达能力。
-
解决梯度消失问题: 在深层神经网络中,如果使用线性激活函数(如恒等函数),梯度会随着网络的深度逐渐变小,导致梯度消失问题。而非线性激活函数可以防止梯度消失,使得反向传播时能够更有效地传递梯度,从而更好地更新参数。
-
增加模型的非线性: 激活函数能够给神经网络引入非线性变换,使得神经网络可以学习和表示更加复杂的函数关系。这对于处理实际问题中的复杂数据非常重要,例如图像、语音、文本等。
-
网络输出的映射: 对于不同类型的任务,如分类、回归等,需要将网络输出映射到合适的范围或概率分布。激活函数可以帮助网络输出具有特定的性质,如将输出限制在0到1之间(如Sigmoid函数),或者将输出限制在-1到1之间(如Tanh函数)等。
综上所述,激活函数在神经网络中的作用是非常重要的,它不仅能够增加网络的表达能力,还能够解决梯度消失问题,从而使得神经网络能够更好地适应和学习复杂的数据关系
3.3激活函数的类型,适用条件
激活函数有很多种,每种激活函数都有自己的特点和适用条件。以下是常用的几种激活函数以及它们适用的条件:(不会编辑函数,没有放公式,可以自己查询一下公式)
-
Sigmoid 函数:
- 适用条件:适用于二分类问题的输出层,在输出值需要被映射到0到1之间的概率值时常用。但是在深层网络中容易出现梯度消失的问题,因此在隐藏层中使用较少。
-
Tanh 函数:
- 适用条件:适用于输出范围在-1到1之间的情况,与Sigmoid函数类似,但输出范围更广。同样,由于存在梯度消失问题,深层网络中也需要谨慎使用。
-
ReLU 函数(Rectified Linear Unit):
- 适用条件:在深度学习中最常用的激活函数之一。具有线性和非线性特性,计算简单,训练速度快。适用于大多数情况,特别是在隐藏层中。
-
Leaky ReLU 函数:
- 适用条件:解决ReLU函数中负数部分梯度消失的问题。通过引入小的负数斜率,使得激活函数在负数部分也有一定的输出,从而避免了“神经元死亡”的问题。
-
ELU 函数(Exponential Linear Unit):
- 适用条件:类似于Leaky ReLU,ELU函数在负数部分有一定的输出,但相对于Leaky ReLU,ELU函数的输出更加平滑。因此在一些情况下,ELU函数可能会带来更好的效果。
-
Softmax 函数:
- 适用条件:适用于多分类问题的输出层,将网络输出转化为概率分布。Softmax函数将每个输出转化为一个0到1之间的概率值,并且所有输出的概率之和为1。
这些是常用的几种激活函数,每种激活函数都有自己的特点和适用条件。在选择激活函数时,需要根据具体的问题和网络结构进行选择,并根据实验结果进行调优。
4.Flatten()函数
"扁平"通常指的是将数据从多维数组或嵌套结构转换为一维结构的过程。在计算机编程中,特别是在机器学习和深度学习中,经常会涉及到数据的扁平化操作,以便更方便地进行处理和分析。
4.1PyTorch 环境
可以使用 torch.flatten() 函数来将张量扁平化为一维张量
import torch
# 创建一个二维张量
tensor = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 使用 flatten() 函数将二维张量扁平化为一维张量
flat_tensor = torch.flatten(tensor)
print("tnesor")
print("------")
print("flat_tensor")
可以看到扁平操作之后,张量tensor大小没有变化,但是shape改变了,维度降低了。
4.2Python环境
import numpy as np
# 二维数组或矩阵
matrix = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 使用 flatten() 方法将矩阵扁平化为一维数组
flat_array = matrix.flatten()
print("原始矩阵:")
print(matrix)
print("\n扁平化后的一维数组:")
print(flat_array)

5.model_train.py中用到的模块的作用
import copy
import time
import pandas as pd
import torch
from torchvision.datasets import FashionMNIST
from torchvision import transforms
import torch.utils.data as Data
import numpy as np
import matplotlib.pyplot as plt
from model import LeNet
import torch.nn as nn-
copy:这个模块提供了一种实现对象复制的方法,可以用于复制数据结构,包括列表、字典等。在深度学习中,经常需要复制模型的参数或其他对象,以便进行一些操作而不影响原始对象。 -
time:这个模块提供了处理时间的功能,比如获取当前时间、计算时间间隔等。在代码中,通常会用到time.time()函数来获取当前时间,用于计算程序执行时间等。 -
pandas:Pandas 是 Python 中用于数据处理和分析的重要库。它提供了 DataFrame 数据结构,可以方便地进行数据索引、筛选、排序、分组等操作。在深度学习中,Pandas 经常用于加载和处理数据集,以及保存训练过程中的指标数据。 -
torch:PyTorch 是一个用于深度学习的开源框架,提供了张量运算、自动求导等功能。torch模块是 PyTorch 的核心模块,包括张量操作、模型构建、优化器、损失函数等。 -
torchvision.datasets:这个模块包含了一些常用的计算机视觉数据集,如 MNIST、FashionMNIST、CIFAR 等。FashionMNIST类就是用于加载 FashionMNIST 数据集的。 -
transforms:这个模块包含了一些常用的数据预处理操作,如缩放、裁剪、旋转、归一化等。可以用于对图像数据进行预处理,以便用于模型训练。 -
torch.utils.data:这个模块包含了一些用于数据处理的工具,如 DataLoader 类,用于批量加载数据。在深度学习中,通常会用 DataLoader 来加载训练集和验证集,并设置批量大小、是否随机打乱等参数。 -
numpy:NumPy 是 Python 中用于科学计算的重要库,提供了高效的数组操作和数学函数。在深度学习中,经常会用到 NumPy 来处理数据、进行数学运算等。 -
matplotlib.pyplot:Matplotlib 是 Python 中用于绘图的库,pyplot是 Matplotlib 中的一个子模块,提供了类似 MATLAB 的绘图接口。在深度学习中,经常会用到 Matplotlib 来绘制损失曲线、准确率曲线等,以便进行模型性能的分析和可视化。 -
model:这个是自定义的模型模块,其中包含了LeNet类,是一个用于图像分类的卷积神经网络模型。 -
torch.nn:这个模块是 PyTorch 中的神经网络模块,包含了构建神经网络模型的相关类和函数,如神经网络层、损失函数等。nn模块是 PyTorch 中的核心模块之一
6.Data.random_split函数
Data.random_split 函数用于将数据集随机划分为两个子集,可以用于划分训练集和验证集、或者将数据集划分为训练集、验证集和测试集等。
6.1使用方法
dataset_splits = Data.random_split(dataset, lengths)其中:
-
dataset是要划分的数据集对象,可以是任何 PyTorch 中的数据集对象,比如TensorDataset、ImageFolder、FashionMNIST等。 -
lengths是一个整数列表,表示划分后每个子集的长度。例如,如果lengths=[50000, 10000],则表示划分后的两个子集的长度分别为 50000 和 10000
6.2示例
import torch
from torch.utils.data import TensorDataset, DataLoader, random_split
# 创建一个张量数据集
data = torch.randn(60000, 10) # 创建一个包含 60000 个样本的数据集,每个样本有 10 个特征
labels = torch.randint(0, 2, (60000,)) # 创建随机标签,0 或 1
dataset = TensorDataset(data, labels)
# 将数据集划分为训练集和验证集,比例为 4:1
train_set, val_set = random_split(dataset, [50000, 10000])
print(len(train_set)) # 输出训练集的长度
print(len(val_set)) # 输出验证集的长度 在这个示例中,我们创建了一个包含 60000 个样本的张量数据集 dataset,然后使用 random_split 函数将其划分为训练集 train_set 和验证集 val_set,比例为 4:1。最后输出了训练集和验证集的长度
7.epoch和batch
在深度学习中,一个 epoch(时代)指的是将所有训练样本都过一遍神经网络训练的过程。换句话说,一个 epoch 表示神经网络学习了整个训练数据集的一次。在每个 epoch 中,训练数据集会被分成若干个批次(batches),每个批次包含一定数量的样本,然后神经网络对每个批次的样本进行前向传播(计算输出)、计算损失、反向传播(计算梯度)和参数更新的过程。
训练一个神经网络通常需要多个 epoch,因为在训练过程中,神经网络的参数需要多次迭代优化才能达到较好的性能。每个 epoch 结束后,我们通常会对模型进行评估,例如在验证集上计算损失和准确率,以便监控模型的训练过程和性能.
8.enumerate
enumerate 是 Python 内置函数,用于将一个可迭代对象(如列表、元组、字符串等)组合为一个索引序列,同时可以获得每个元素的值。它通常与 for 循环一起使用,在循环的过程中可以同时获得索引和对应的值。
8.1 enumerate 函数的语法
enumerate(iterable, start=0)
其中:
iterable:表示要迭代的可迭代对象,如列表、元组、字符串等。start:可选参数,表示起始索引值,默认为 0。如果指定了start参数,则索引从指定的值开始。
enumerate 函数返回一个枚举对象,每个元素是一个元组,包含两个值:索引和对应的元素值
8.2示例
my_list = ['apple', 'banana', 'orange']
for index, value in enumerate(my_list):
print(f'Index: {index}, Value: {value}')
结果:
Index: 0, Value: apple
Index: 1, Value: banana
Index: 2, Value: orange
在这个示例中,enumerate(my_list) 将列表 my_list 转换为一个枚举对象,然后通过 for 循环遍历枚举对象,每次循环得到一个索引和对应的值















 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









