







- 按其分析的粒度可以分为篇章级,句子级,词或短语级
文本级别:通过完整文档或段落来获取情绪;
句子级别:获得单句的情绪。
子句级别:获得句子中,子表达的情感。
基本流程图
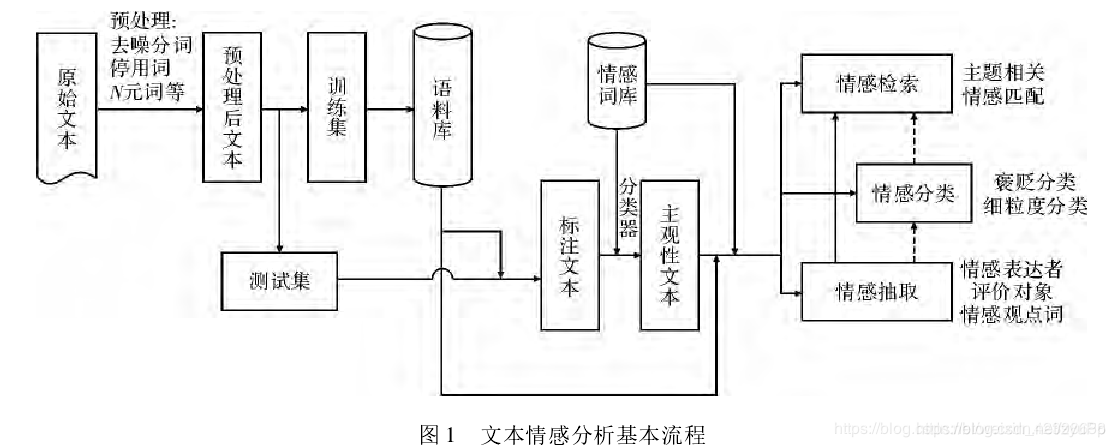
情感分类
任务:给定文本,识别其主观性文本的倾向,肯定or否定?正面或负面?
网络中存在 主 观 性 文 本 \color{red}{主观性文本} 主观性文本和 客 观 性 文 本 \color{red}{客观性文本} 客观性文本,而情感分类的对象是带有情感倾向的主观性文本,因此首先要进行文本的主观性分类。有两种类别的观点:直接性和比较性,例如A真的好和A比B好。有明确的,也有含蓄的
主观性分类:以情感词识别为主,利用不同的文本特征表示方法和分类器进行识别分类。主要研究思路:
- 基于语义的情感词典方法
- 基于机器学习的方法
基于语义的情感词典方法
(1)构建词典
情感词典是情感分类的基础,有4类词语:通用情感词、程度副词、否定词和领域词。
构建方法:利用已有词典扩展生成
做法:利用语义相似度计算方法计算词语与基准情感词集的语义相似度
(2)构建倾向性计算算法
利用情感词典和分析文本语句的特殊结构以及情感倾向词,采用权值算法或利用简单统计方法进行情感分类。根据情感强度给情感词赋予不同权值,然后进行加权求和
(3)确定阈值来判断文本倾向性
一般情况下,加权计算结果为正是正面倾向,结果为负是负面倾向 ,得分为零无倾向。所得结果评价一般采用自然语言中经常使用的正确率、召回率和 F 值来评判算法效果。
优点:不依赖标注好的训练集,实现简单,快速有效
缺点:粗粒度的分析,对词典构建要求比较高
基于机器学习的情感分类方法
(1)人工标注文本倾向性作为训练集
(2)提取文本情感特征
(3)机器学习方法构造情感分类器
(4)待分类文本通过分类器进行倾向性分类
常用的情感分类特征包括情感词,词性,句法结构,否定表达模板,连接,语义话题等.
.常用特征提取方法:信息增益,文档频率
分类方法:KNN,Bayes,SVM,CRF,最大熵分类器等
深度学习方法
用word embedding + DNN或者 Language model + Decoder
情感分析的类型
- 细粒度情感分析
了解评论的极性水平,例如5星评级
- 情绪检测
旨在检测诸如快乐,沮丧,愤怒,悲伤等情绪,采用词典(即单词列表和它们传达的情感)或复杂的机器学习算法
- 基于Aspect的情感分析
“相机的电池续航不行”,说相机不行,但是更注重的是电池方面的不行,针对产品的特定方面
- 意图分析
检测人们通过文本做什么;“如何更换墨盒?”
实现情感分析
- 基于规则(手动指定规则)
- 自动系统(机器学习)
- 混合系统(基于规则和自动方法)
情感分析评估标准:
精确度,召回率和准确度是用于评估分类器性能的标准度量
- Precision 精确率:预测为1的样本中,多少被正确分类
- Recall召回率:实际为1的样本中,多少被成功预测
- Accuracy准确率:所有文本中,被预测正确的文本
情感分析的挑战
主观性和语气
事实上,所谓的客观文本不包含明确的情绪。分析以下两个文本的情绪:“包很好。”“包裹是红色的。”
所有谓词(形容词,动词和某些名词)在创造情绪方面不应该被视为相同。 在上面的例子中,nice比red更主观。
语境和极性
反讽和讽刺
比较
表情符号
定义中性
包括客观文本,无关信息,包含愿望的文本

















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









