







链接:https://arxiv.org/abs/2502.01563
Motivation:
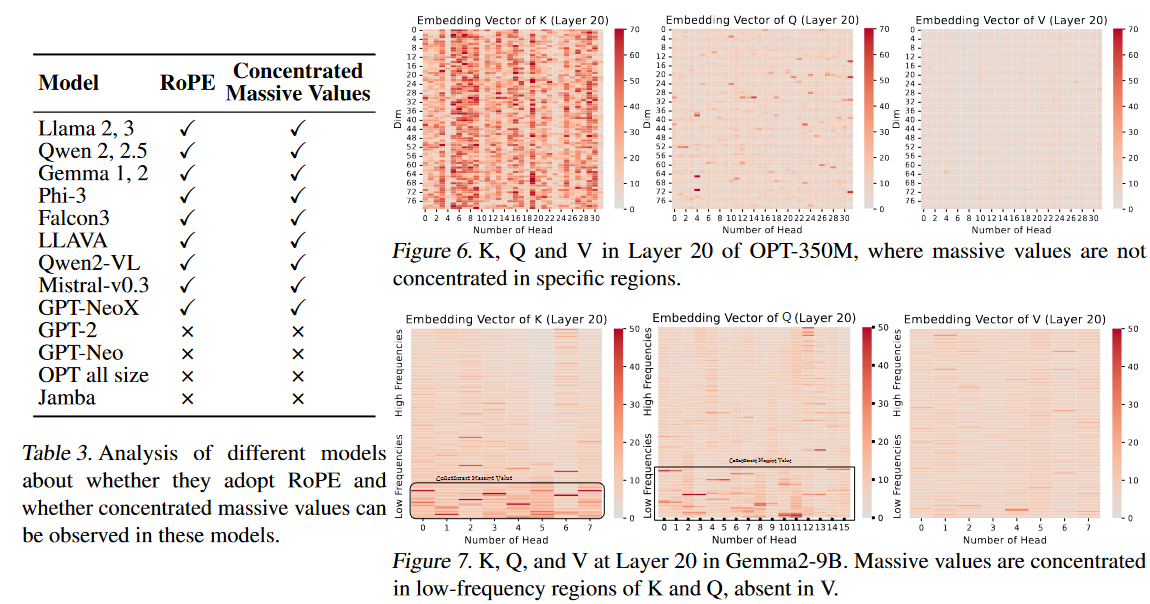
- 自注意力模块中的Massive values:研究发现,在基于Transformer架构的LLMs中,自注意力模块的查询(Q)和键(K)中会出现集中分布的巨大值(i.e., magnitudes significantly larger than typical values),而在值(V)中则没有这种模式。这些巨大值对模型的上下文知识理解可能起着关键作用,但其具体作用和形成机制尚不清楚。
- 量化策略的需求:在实际应用中,为了提高模型的效率和可扩展性,需要对模型进行量化。然而,现有的量化方法在处理这些巨大值时可能会导致性能下降,因此需要深入研究这些值的性质,以便开发更有效的量化策略。
Method:
RoPE:旋转位置编码,一种相对位置编码方式。


Massive values 定义:
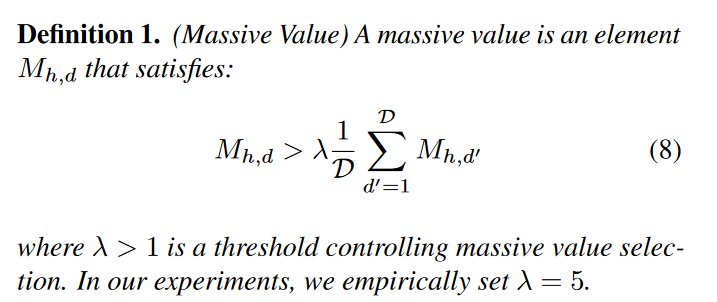

Disruption of Massive Value
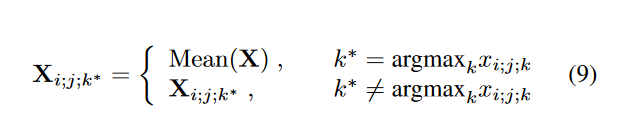
- 实验设计:
-
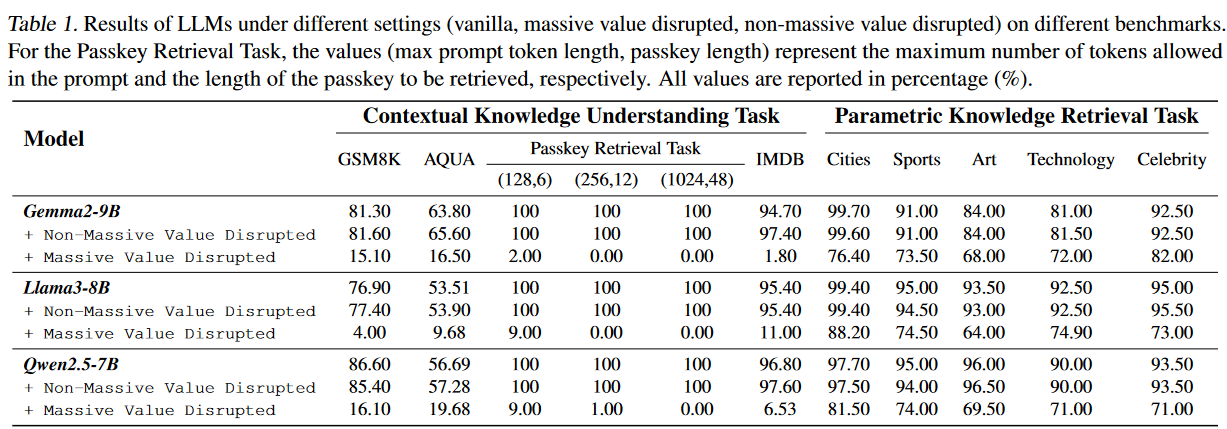
- 数据集选择:选择了多种数据集,包括数学推理基准(GSM-8K、AQUA)、情感分析数据集(IMDB)和合成的密钥检索数据集,以评估模型在上下文知识理解和参数知识检索任务中的表现。
- 模型选择:选择了多种LLMs,包括Llama、Gemma和Qwen等,这些模型都使用了RoPE(旋转位置编码)。
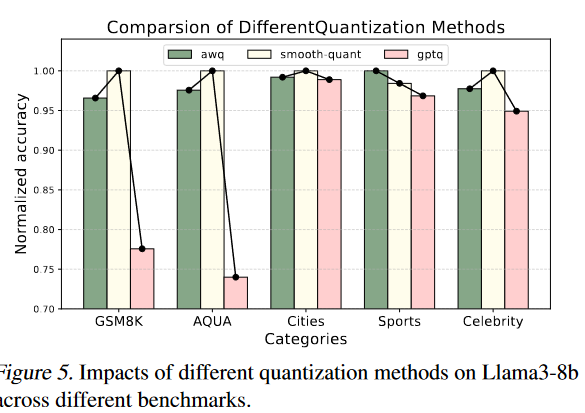
- 量化方法评估:评估了三种量化方法(AWQ、SmoothQuant和GPTQ),以了解它们对模型性能的影响。
结论:
- 巨大值的集中分布:在使用RoPE的LLMs中,Q和K中会出现集中分布的巨大值,而V中则没有这种模式。这些巨大值在不同注意力头中的位置非常接近,且在不同模型中具有一致性。
- 巨大值对上下文知识理解的重要性:实验表明,巨大值对上下文知识理解任务(如密钥检索、IMDB情感分析和数学推理)至关重要,而对参数知识检索任务(如世界城市知识问答)的影响较小。
- 量化方法的影响:针对巨大值的量化方法(如AWQ和SmoothQuant)能够更好地保持LLMs的上下文知识理解能力,而忽略巨大值的量化方法(如GPTQ)会导致性能显著下降。
- 巨大值的起源:文章发现巨大值的集中分布是由RoPE引起的,并且这种现象从模型的最初几层就开始出现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









