







DAPO: An Open-Source LLM Reinforcement Learning System at Scale
链接:https://arxiv.org/pdf/2503.14476
1. Motivation
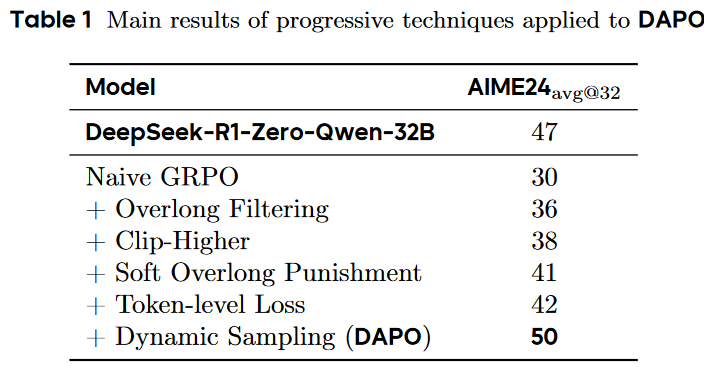
强化学习(RL)是提升LLMs推理能力的核心技术,但目前最先进的推理LLMs(如OpenAI的o1和DeepSeek的R1)的技术细节并未公开,导致难以复现其RL训练结果。为了填补这一空白,作者提出了DAPO算法,并开源了一个基于Qwen2.5-32B模型的RL系统,该系统在AIME 2024竞赛中取得了50分的成绩,超越了DeepSeek-R1-Zero-Qwen-32B的47分。
2. Contribution
We propose the Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO) algorithm, and introduce 4 key techniques to make RL shine in the long-CoT RL scenario.
- Clip-Higher, which promotes the diversity of the system and avoids entropy collapse;
- Dynamic Sampling, which improves training efficiency and stability;
- Token-Level Policy Gradient Loss, which is critical in long-CoT RL scenarios;
- Overlong Reward Shaping, which reduces reward noise and stabilizes training.
Our implementation is based on verl [20](https://github.com/volcengine/verl). By fully releasing our state-of-the-art RL system including training code and data, we aim to reveal valuable insights to large-scale LLM RL that benefit the larger community.
3. Preliminary
3.1. Proximal Policy Optimization (PPO)
PPO [21] introduces a clipped surrogate objective for policy optimization. By constraining the policy updates within a proximal region of the previous policy using clip, PPO stabilizes training and improves sample efficiency. Specifically, PPO updates the policy by maximizing the following objective:

Given the value function V and the reward function R, ˆ At is computed using the Generalized Advantage Estimation (GAE):
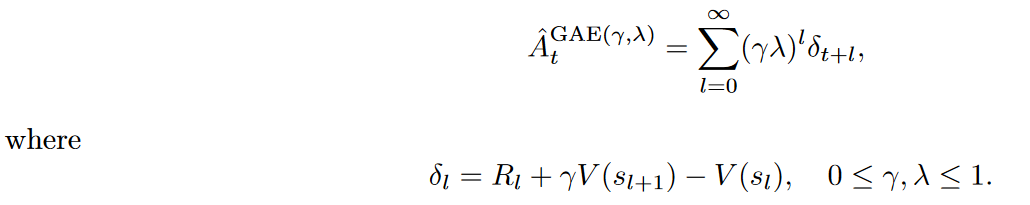
PPO的目标函数相对简单,易于实现和优化。它通过截断概率比率来避免策略更新过大,避免了复杂的KL散度惩罚项,使得算法更加高效。
3.2. Group Relative Policy Optimization (GRPO)
Compared to PPO, GRPO eliminates the value function(没有价值函数) and estimates the advantage in a group-relative manner. For a specific question-answer pair (q, a), the behavior policy πθold samples a group of G individual responses {oi}G i=1. Then, the advantage of the i-th response is calculated by normalizing the group-level rewards {Ri}G i=1:
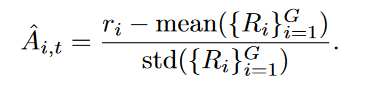
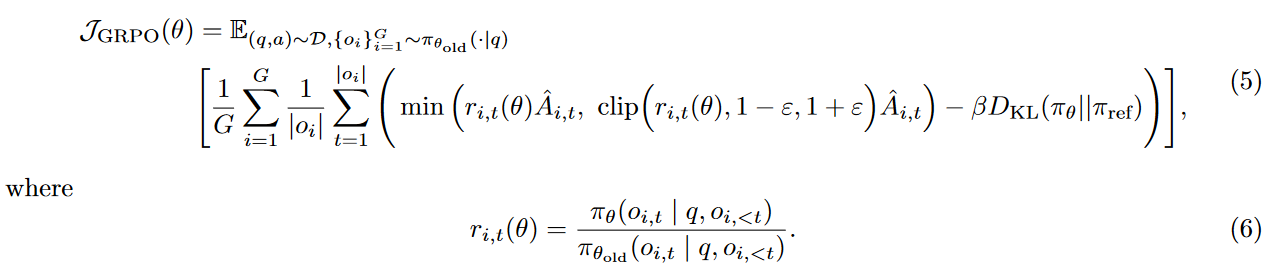
除以 ∣oi∣ 是为了对序列中的每个元素(token)进行归一化处理。这里的 ∣oi∣ 表示第 i 个输出序列的长度,即该序列中元素(token)的总数,
3.3. Removing KL Divergence
The KL penalty term is used to regulate the divergence between the online policy and the frozen reference policy. In the RLHF scenario [23], the goal of RL is to align the model behavior without diverging too far from the initial model. However, during training the long-CoT reasoning model, the model distribution can diverge significantly from the initial model, thus this restriction is not necessary. Therefore, we will exclude the KL term from our proposed algorithm.(允许较大变化)
3.4. Rule-based Reward Modeling
The use of reward model usually suffers from the reward hacking problem [24–29]. Instead, we directly use the final accuracy of a verifiable task as the outcome reward, computed using the following rule.

4. DAPO
DAPO samples a group of outputs {oi}G i=1 for each question q paired with the answer a, and optimizes the policy via the following objective

直观比较公式上的不同,和GRPO一样对回答进行了采样,没有KL散度惩罚,没有value model优势值计算与GRPO一样,clip函数中ε对上下限进行了分别处理。归一化处理不同于GRPO,增加了采样条件即采样的回答不能全对或全错?
4.1. Raise the Ceiling: Clip-Higher
问题:PPO or GRPO :entropy collapse phenomenon
The entropy of the policy decreases quickly as training progresses. The sampled responses of certain groups tend to be nearly identical. This indicates limited exploration and early deterministic policy, which can hinder the scaling process.
解决方案:We propose the Clip-Higher strategy to address this issue. Clipping over the importance sampling ratio is introduced in PPO-Clip to restrict the trust region and enhance the stability of RL. We identify that the upper clip can restrict the exploration of the policy. In this case, it is much easier to make an ‘exploitation token’ more probable, than to uplift the probability of an unlikely ‘exploration token’. upper clip为低概率token提供更多的探索空间。
证明:Concretely, when ε = 0.2 (the default value of most algorithms),
consider two actions with probabilities πθold (oi | q) = 0.01 and 0.9. The maximum possible updated probabilities πθ(oi | q) are 0.012 and 1.08, respectively.
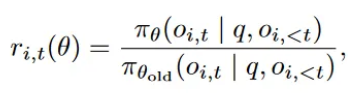
r=1.2
This implies that for tokens with a higher probability (e.g., 0.9) is less constrained. Conversely, for low-probability tokens, achieving a non-trivial increase in probability is considerably more challenging. (即小概率token想提高一点点由于被限制变得更难了)Empirically, we also observe that the maximum probability of clipped tokens is approximately πθ(oi | q) < 0.2 (Figure 3a). This finding supports our analysis that the upper clipping threshold indeed restricts the probability increase of low-probability tokens, thereby potentially constraining the diversity of the system.
4.2. The More the Merrier: Dynamic Sampling
问题:Existing RL algorithm suffers from the gradient-decreasing problem when some prompts have accuracy equal to 1. For example for GRPO, if all outputs {oi}G i=1 of a particular prompt are correct and receive the same reward 1, the resulting advantage for this group is zero. A zero advantage results in no gradients for policy updates, thereby reducing sample efficiency. Empirically, the number of samples with accuracy equal to 1 continues to increase, as shown in Figure 3b. This means that the effective number of prompts in each batch keeps decreasing, which can lead to larger variance in gradient and dampens the gradient signals for model training. 当采样的回答全对时,优势为0,梯度更新也为0.
解决方案:To this end, we propose to over-sample and filter out prompts with the accuracy equal to 1 and 0 illustrated in Equation 11, leaving all prompts in the batch with effective gradients and keeping a consistent number of prompts. Before training, we keep sampling until the batch is fully filled with samples whose accuracy is neither 0 nor 1. 一直采样到符合标准为止。
4.3. Rebalancing Act: Token-Level Policy Gradient Loss
问题:original GRPO algorithm employs a sample-level loss calculation, which involves first averaging the losses by token within each sample and then aggregating the losses across samples. In this approach, each sample is assigned an equal weight in the final loss computation. However, we find that this method of loss reduction introduces several challenges in the context of long-CoT RL scenarios.
较长响应(包含更多token)中的token可能对整体损失的贡献较小,这会导致两个不利影响。
- 对于高质量的长样本,这种效应可能阻碍模型学习其中的推理模式。
- 我们观察到过长的样本常常表现出低质量模式,如无意义和重复的词。
解决方法:We introduce a Token-level Policy Gradient Loss in the long-CoT RL scenario to address the above limitations
优势:在这种情况下,与较短的序列相比,较长的序列对整体梯度更新有更大的影响。此外,从单个令牌的角度来看,如果特定的生成模式可以导致奖励的增加或减少,则无论其出现的响应的长度如何,它都会同样增加或抑制。
4.4. Hide and Seek: Overlong Reward Shaping
问题:In RL training, we typically set a maximum length for generation, with overlong samples truncated accordingly. We find that improper reward shaping for truncated samples can introduce reward noise and significantly disrupt the training process.
解决办法:
截断样本引入惩罚机制,避免了因生成过长响应而引入的噪声
Furthermore, we propose Soft Overlong Punishment (Equation 13), a length-aware penalty mechanism designed to shape the reward for truncated samples. Specifically, when the response length exceeds the predefined maximum value, we define a punishment interval. Within this interval, the longer the response, the greater the punishment it receives. This penalty is added to the original rule-based correctness reward, thereby signaling to the model to avoid excessively long responses.
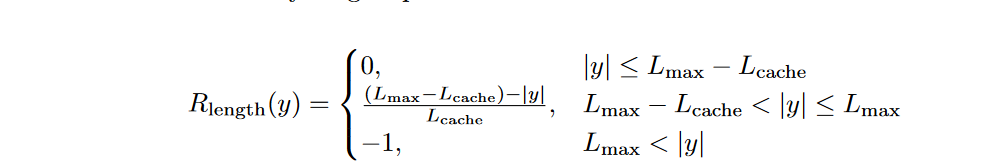
4.5. Dataset Transformation
描数据集的转换过程从AoPS网站和官方竞赛主页通过网页抓取和手动注释获取数据。为了提供准确的奖励信号并最小化公式解析器引入的错误,选择了将答案转换为整数的形式。
5. Experiments
5.1. Training Details
- 专注于数学任务,特别是使用Qwen2.5-32B模型作为预训练模型进行RL实验。
- 使用verl框架进行训练。
- 采用naive GRPO(Group Relative Policy Optimization)作为基线算法。
- 通过组奖励归一化来估计优势函数。
- 超参数设置
-
- 使用AdamW优化器,恒定学习率为 1×10−6。
- 采用线性预热策略,预热步数为20。
- Roll out过程中,提示批大小为512,每个提示采样16个响应。
- 训练时,小批量大小设置为512,即每个rollout步进行16次梯度更新。
- Overlong Reward Shaping中,预期最大长度设为16,384个tokens,额外分配4,096个tokens作为软惩罚缓存。
- 对于Clip-Higher机制,设置剪辑参数 ϵlow 为0.2,ϵhigh 为0.28。
-
- 在AIME上进行评估,重复评估32次以报告avg@32结果以确保稳定性。
- 评估时的推理超参数设置为温度1.0和top-p 0.7。
5.2. Main Results
AIME 2024的实验表明,DAPO成功地将QWEN-32B基本模型训练为强大的推理模型,从而实现了使用R1方法在QWEN2.5-32B上实验优于DeepSeek的实验。在图1中,我们观察到AIME 2024上的性能有了很大的改善,精度从接近0%增加到50%。值得注意的是,仅使用DeepSeek-R1-Zero-Qwen-32B所需的训练步骤的50%实现了这一改进。
6. Take-aways
- 回顾了PPO、GRPO等经典方法。
- 对PPO、GRPO方法的缺点进行分析并提出对应解决办法。
- 提出了DAPO并公布了代码以供学习。(DAPO)

















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









