










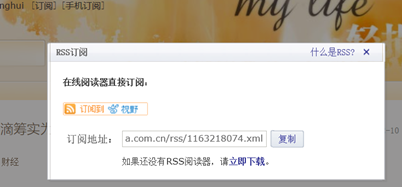
我们一般用xmlfeed模版爬虫去处理RSS订阅信息。RSS是一种信息聚合技术,可以让信息的发布和共享更为高效和便捷。RSS是基于XML标准的,扩展名是 .xml ,需要下载专门的阅读器才能打开,否则看到的就是这个样子:

(1)创建项目:scrapy startproject xmlfeedspider
(2)使用XMLFeedSpider模板创建爬虫:
scrapy genspider -t xmlfeed jobbole sina.com.cn
(3)使用Item收集数据,在xmlfeedspider文件夹中,修改items.py文件,代码如下:
import scrapy
class XmlfeedspiderItem(scrapy.Item):
# 文章标题
title = scrapy.Field()
# 发表日期
public_date = scrapy.Field()
# 文章链接
link = scrapy.Field()
(4)在spiders文件中,修改jobbole.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.spiders import XMLFeedSpider
# 导入 item
from xmlfeedspider.items import XmlfeedspiderItem
class JobboleSpider(XMLFeedSpider):
name = 'jobbole'
allowed_domains = ['sina.com']
start_urls = ['http://blog.sina.com.cn/rss/1163218074.xml']
iterator = 'iternodes' # 迭代器,默认是 iternodes
# 抓取item节点(也可以是rss,具体要看 .xml 文件结构)
itertag = 'item'
def parse_node(self, response, selector):
item = XmlfeedspiderItem()
item['title'] = selector.css('title::text').extract_first()
item['public_date']=selector.css('pubDate::text').extract_first()
item['link'] = selector.css('link::text').extract_first()
yield item # 也可以使用 return item
(5)在setting中需要修改的配置如下:
# 自定义USER_AGENT 的值
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) Apple‘
+’WebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
# 不遵守robots.txt协议规则
ROBOTSTXT_OBEY = False
(6)运行爬虫,查看结果,如下:

















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









