






12.1-决策树实验分析
# 导入所需的库
import numpy as np
import os
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
# 导入决策树可视化所需的库
from sklearn.tree import export_graphviz
# 导入Iris数据集和决策树分类器
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# 加载Iris数据集
iris = load_iris()
X = iris.data[:, 2:] # 提取花瓣长度和宽度作为特征
y = iris.target
# 创建决策树分类器,限制树的深度为2
tree_clf = DecisionTreeClassifier(max_depth=2)
# 使用Iris数据训练决策树分类器
tree_clf.fit(X, y)
# 导出决策树结构到.dot文件,用于后续可视化
export_graphviz(
tree_clf,
out_file="iris_tree.dot",
feature_names=iris.feature_names[2:], # 使用特征的名称
class_names=iris.target_names, # 使用类别的名称
rounded=True,
filled=True
)
# 导入用于在Jupyter Notebook中显示图像的库
#from IPython.display import Image
#Image(filename='iris_tree.png', width=400, height=400)
# 注意:在Python编译器中,你需要使用Graphviz工具手动将.dot文件转换为图像文件。
# 命令行转换为.png图像文件的示例命令:$ dot -Tpng iris_tree.dot -o iris_tree.png

12.2-决策边界展示分析
# 导入所需的库
import numpy as np
import os
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
# 导入决策树可视化所需的库
from sklearn.tree import export_graphviz
# 导入Iris数据集和决策树分类器
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from matplotlib.colors import ListedColormap
# 加载Iris数据集
iris = load_iris()
X = iris.data[:, 2:] # 提取花瓣长度和宽度作为特征
y = iris.target
# 创建决策树分类器,限制树的深度为2
tree_clf = DecisionTreeClassifier(max_depth=2)
# 使用Iris数据训练决策树分类器
tree_clf.fit(X, y)
# 定义一个函数,用于绘制决策边界
def plot_decision_boundary(clf, X, y, axes=[0, 7.5, 0, 3], iris=True, legend=False, plot_training=True):
# 创建一组水平和垂直坐标点,用于绘制决策边界
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
# 使用分类器进行预测,并将结果整形为与坐标网格相同的形状
y_pred = clf.predict(X_new).reshape(x1.shape)
# 自定义颜色映射
custom_cmap = ListedColormap(['#fafab0', '#9898ff', '#a0faa0'])
# 使用contourf函数绘制决策边界的背景色
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)
# 如果不是Iris数据集,则绘制决策边界的轮廓线
if not iris:
custom_cmap2 = ListedColormap(['#7d7d58', '#4c4c7f', '#507d50'])
plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)
# 如果要绘制训练样本点,则分别绘制不同类别的样本点
if plot_training:
plt.plot(X[:, 0][y == 0], X[:, 1][y == 0], "yo", label="Iris-Setosa")
plt.plot(X[:, 0][y == 1], X[:, 1][y == 1], "bs", label="Iris-Versicolor")
plt.plot(X[:, 0][y == 2], X[:, 1][y == 2], "g^", label="Iris-Virginica")
plt.axis(axes)
# 设置坐标轴标签
if iris:
plt.xlabel("花瓣长度", fontsize=14)
plt.ylabel("花瓣宽度", fontsize=14)
else:
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
# 如果需要绘制图例,则添加图例
if legend:
plt.legend(loc="lower right", fontsize=14)
plt.figure(figsize=(8, 4))
plot_decision_boundary(tree_clf, X, y)
plt.plot([2.45, 2.45], [0, 3], "k-", linewidth=2)
plt.plot([2.45, 7.5], [1.75, 1.75], "k--", linewidth=2)
plt.plot([4.95, 4.95], [0, 1.75], "k:", linewidth=2)
plt.plot([4.85, 4.85], [1.75, 3], "k:", linewidth=2)
plt.text(1.40, 1.0, "Depth=0", fontsize=15)
plt.text(3.2, 1.80, "Depth=1", fontsize=13)
plt.text(4.05, 0.5, "(Depth=2)", fontsize=11)
plt.title('Decision Tree decision boundaries')
plt.show()
"决策边界展示分析"部分的代码用于绘制决策树的决策边界图,并对决策边界进行分析。以下是对该部分的简要概括:
-
导入所需的库:
- 导入NumPy、Matplotlib等库,以及一些绘图参数的设置。
- 导入用于决策树可视化的
export_graphviz函数。 - 导入Iris数据集和决策树分类器,以及
ListedColormap用于绘制颜色地图。
-
加载Iris数据集:
- 使用
load_iris函数加载Iris数据集,并提取花瓣长度和宽度作为特征。 - 创建决策树分类器,限制树的深度为2,并使用Iris数据进行训练。
- 使用
-
定义
plot_decision_boundary函数:- 用于绘制决策树的决策边界图。
- 根据传入的分类器、数据、绘图参数等信息,绘制决策边界和数据点。
- 在图中标注深度信息,以及类别的标签。
- 支持不同的绘图风格,包括Iris数据集和自定义数据集。
-
绘制决策边界图:
- 使用
plot_decision_boundary函数绘制决策树的决策边界图。 - 根据深度和数据点位置,绘制决策树的分割线和决策边界。
- 在图中标注不同深度的节点。
- 使用
这段代码的主要目的是可视化决策树的决策边界,帮助我们理解决策树的分裂规则和结构,以及如何根据特征来进行分类决策。
12.3-树模型预剪枝参数作用
决策树中的正则化
DecisionTreeClassifier类还有一些其他参数类似地限制了决策树的形状:
-
min_samples_split(节点在分割之前必须具有的最小样本数),
-
min_samples_leaf(叶子节点必须具有的最小样本数),
-
max_leaf_nodes(叶子节点的最大数量),
-
max_features(在每个节点处评估用于拆分的最大特征数)。
-
max_depth(树最大的深度)
# 导入所需的库
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
# 使用make_moons函数生成带噪声的数据集
X, y = make_moons(n_samples=100, noise=0.25, random_state=53)
# 创建两个决策树分类器,一个没有限制,一个设置了叶节点最少样本数为4
tree_clf1 = DecisionTreeClassifier(random_state=42)
tree_clf2 = DecisionTreeClassifier(min_samples_leaf=4, random_state=42)
# 分别使用两个分类器对数据进行训练
tree_clf1.fit(X, y)
tree_clf2.fit(X, y)
# 创建一个大的图形窗口,包含两个子图
plt.figure(figsize=(12, 4))
# 绘制第一个子图,显示没有限制的决策树分类器的决策边界
plt.subplot(121)
plot_decision_boundary(tree_clf1, X, y, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title('无限制')
# 绘制第二个子图,显示设置了叶节点最少样本数为4的决策树分类器的决策边界
plt.subplot(122)
plot_decision_boundary(tree_clf2, X, y, axes=[-1.5, 2.5, -1, 1.5], iris=False)
plt.title('min_samples_leaf=4')

"决策树中的正则化"部分的代码演示了如何在决策树中应用正则化技术,以限制决策树的生长,防止过拟合。以下是对该部分的简要概括:
-
使用
make_moons生成带噪声的数据集(这一部分的目的是创建一个用于分类的数据集)。 -
创建两个不同的决策树分类器:
tree_clf1:一个没有任何限制的决策树分类器。tree_clf2:一个设置了叶节点最少样本数为4的决策树分类器,即叶节点至少包含4个样本。
-
使用这两个分类器分别对数据进行训练。
-
绘制两个子图以可视化两个决策树分类器的决策边界。第一个子图显示没有任何限制的决策树,第二个子图显示设置了叶节点最少样本数为4的决策树。
额外解释:
min_samples_split:节点在分割之前必须具有的最小样本数。如果节点的样本数小于此值,将不再进行分裂。min_samples_leaf:叶子节点必须具有的最小样本数。如果叶子节点的样本数小于此值,可能会剪枝。max_leaf_nodes:叶子节点的最大数量。限制叶子节点的数量,以防止过拟合。max_features:在每个节点处评估用于拆分的最大特征数。通过限制考虑的特征数量,可以控制模型的复杂性。max_depth:树的最大深度。限制决策树的深度可以防止过度拟合。
这些参数可以在DecisionTreeClassifier中设置,用于控制决策树的生长方式,以提高模型的泛化能力和防止过拟合。在正则化过程中,根据数据和问题的特点选择适当的参数值是非常重要的。
12.4-回归树模型
对数据的敏感
# 设置随机种子,以确保生成的随机数据可重复
np.random.seed(6)
# 生成随机的二维数据(Xs)和标签(ys)
Xs = np.random.rand(100, 2) - 0.5 # 生成均匀分布的随机数据,范围在[-0.5, 0.5]之间
ys = (Xs[:, 0] > 0).astype(np.float32) * 2 # 根据Xs的第一维度生成标签,如果Xs第一维度大于0,标签为2,否则为0
# 定义一个角度(angle)用于旋转数据
angle = np.pi / 4
# 创建一个旋转矩阵(rotation_matrix),将数据(Xs)旋转
rotation_matrix = np.array([[np.cos(angle), -np.sin(angle)], [np.sin(angle), np.cos(angle)]])
Xsr = Xs.dot(rotation_matrix) # 将Xs数据应用旋转矩阵,得到新的旋转后的数据(Xsr)
# 创建两个决策树分类器(tree_clf_s和tree_clf_sr)并分别使用Xs和Xsr数据进行训练
tree_clf_s = DecisionTreeClassifier(random_state=42)
tree_clf_s.fit(Xs, ys)
tree_clf_sr = DecisionTreeClassifier(random_state=42)
tree_clf_sr.fit(Xsr, ys)
# 创建一个大的图形窗口,包含两个子图
plt.figure(figsize=(11, 4))
# 绘制第一个子图,显示对数据旋转敏感的决策树分类器(tree_clf_s)的决策边界
plt.subplot(121)
plot_decision_boundary(tree_clf_s, Xs, ys, axes=[-0.7, 0.7, -0.7, 0.7], iris=False)
plt.title('对训练集旋转敏感')
# 绘制第二个子图,显示对旋转后的数据不敏感的决策树分类器(tree_clf_sr)的决策边界
plt.subplot(122)
plot_decision_boundary(tree_clf_sr, Xsr, ys, axes=[-0.7, 0.7, -0.7, 0.7], iris=False)
plt.title('对训练集旋转不敏感')
plt.show()
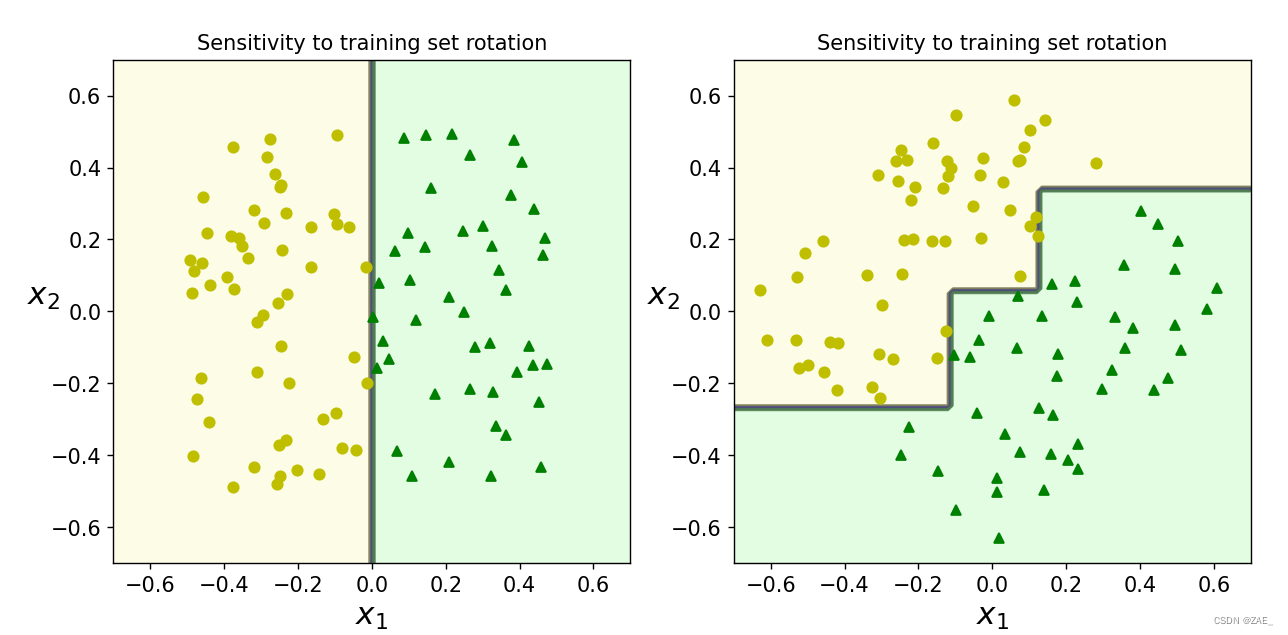
"对数据的敏感"部分的代码演示了决策树在面对不同数据分布和旋转时的敏感性。以下是对该部分的简要概括:
-
生成随机的二维数据(Xs)和标签(ys):
- 使用
make_moons生成带有噪声的数据集,数据点随机分布在平面上。 - 根据数据点的第一维度生成标签,如果第一维度大于0,则标签为2,否则为0。
- 使用
-
定义一个旋转角度(angle)和旋转矩阵(rotation_matrix):
- 旋转角度(angle)为 π / 4。
- 创建一个旋转矩阵(rotation_matrix),用于将数据(Xs)旋转。
-
通过旋转矩阵将数据(Xs)进行旋转,得到旋转后的数据(Xsr)。
-
创建两个决策树分类器(tree_clf_s和tree_clf_sr),并分别使用Xs和Xsr数据进行训练。
-
绘制两个子图以可视化两个决策树分类器的决策边界:
- 第一个子图显示对原始数据(Xs)敏感的决策树分类器(tree_clf_s)的决策边界。
- 第二个子图显示对旋转后数据(Xsr)不敏感的决策树分类器(tree_clf_sr)的决策边界。
"对数据的敏感"原理是指决策树模型对训练数据的特点和分布敏感程度。在决策树中,数据的敏感性主要体现在以下几个方面:
-
特征的重要性: 决策树会根据特征的重要性来选择最佳的分裂点。具有更高重要性的特征将更有可能被用于分裂决策,而不太重要的特征可能被忽略。
-
数据的分布: 决策树的分裂依赖于数据的分布情况。如果数据的分布发生变化,例如数据被旋转或转换,那么决策树可能需要不同的分裂点来适应新的数据分布。
-
样本数量: 决策树中的叶节点最小样本数(min_samples_leaf)和节点分裂最小样本数(min_samples_split)等参数会影响树的形状。样本数量较少时,决策树可能更容易过拟合,而较多的样本可以帮助决策树更好地泛化。
在给定的示例代码中,通过旋转原始数据集,展示了决策树对数据旋转的敏感性。一个决策树模型(tree_clf_s)对旋转前的数据敏感,而另一个模型(tree_clf_sr)对旋转后的数据不敏感。这说明决策树对于数据的特征和分布敏感,可能会导致过拟合或欠拟合的情况。因此,在使用决策树模型时,需要谨慎选择参数,并对数据的特点有清晰的理解,以避免不必要的敏感性问题。
回归任务
# jupyter notebook
# 设置随机种子以确保生成的随机数据可重复
np.random.seed(42)
# 创建一个包含200个样本的一维随机数据(X),范围在[0, 1]之间
m = 200
X = np.random.rand(m, 1)
# 使用数学公式生成对应的目标标签(y)
y = 4 * (X - 0.5) ** 2
y = y + np.random.randn(m, 1) / 10 # 添加一些随机噪声到目标标签中
# 导入决策树回归器
from sklearn.tree import DecisionTreeRegressor
# 创建并训练一个深度为2的决策树回归器
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
# 将决策树可视化并保存为.dot文件
export_graphviz(
tree_reg,
out_file=("regression_tree.dot"),
feature_names=["x1"],
rounded=True,
filled=True
)
# 使用IPython.display库显示生成的决策树图像
from IPython.display import Image
Image(filename="regression_tree.png", width=400, height=400)

"回归任务"部分的代码演示了如何使用决策树回归器进行回归任务。以下是对该部分的简要概括:
-
生成随机数据:
- 通过设定随机种子生成了一个包含200个样本的一维随机数据(X),取值范围在[0, 1]之间。
- 使用一个数学公式生成了对应的目标标签(y),该公式是一个二次方程,表示y是X的平方,并添加了一些随机噪声。
-
导入和训练决策树回归器:
- 导入
DecisionTreeRegressor类,并创建一个深度为2的决策树回归器(tree_reg)。 - 使用生成的数据(X和y)对决策树回归器进行训练。
- 导入
-
可视化生成的决策树:
- 使用
export_graphviz函数将生成的决策树可视化,并保存为.dot文件。 - 使用
IPython.display库显示生成的决策树图像,这个图像展示了树的结构和每个节点的分裂条件,用于解释决策树模型的回归过程。
- 使用
总之,这段代码演示了如何使用决策树回归器拟合回归数据,并将决策树的结构可视化,以便理解决策树在回归任务中的应用。
对比树的深度对结果的影响
# 导入决策树回归器
from sklearn.tree import DecisionTreeRegressor
# 创建两个深度不同的决策树回归器(tree_reg1和tree_reg2),并使用相同的随机种子
tree_reg1 = DecisionTreeRegressor(random_state=42, max_depth=2)
tree_reg2 = DecisionTreeRegressor(random_state=42, max_depth=3)
# 使用生成的数据(X和y)对两个决策树回归器进行训练
tree_reg1.fit(X, y)
tree_reg2.fit(X, y)
# 定义一个绘制回归预测的函数
def plot_regression_predictions(tree_reg, X, y, axes=[0, 1, -0.2, 1], ylabel="$y$"):
x1 = np.linspace(axes[0], axes[1], 500).reshape(-1, 1)
y_pred = tree_reg.predict(x1)
plt.axis(axes)
plt.xlabel("$x_1$", fontsize=18)
if ylabel:
plt.ylabel(ylabel, fontsize=18, rotation=0)
plt.plot(X, y, "b.") # 绘制原始数据点
plt.plot(x1, y_pred, "r.-", linewidth=2, label=r"$\hat{y}$") # 绘制回归预测曲线
# 创建一个大的图形窗口,包含两个子图
plt.figure(figsize=(11, 4))
plt.subplot(121)
# 绘制第一个子图,显示深度为2的决策树回归器的回归预测结果
plot_regression_predictions(tree_reg1, X, y)
for split, style in ((0.1973, "k-"), (0.0917, "k--"), (0.7718, "k--")):
plt.plot([split, split], [-0.2, 1], style, linewidth=2) # 绘制竖直线表示分裂点
plt.text(0.21, 0.65, "Depth=0", fontsize=15)
plt.text(0.01, 0.2, "Depth=1", fontsize=13)
plt.text(0.65, 0.8, "Depth=1", fontsize=13)
plt.legend(loc="upper center", fontsize=18)
plt.title("max_depth=2", fontsize=14)
plt.subplot(122)
# 绘制第二个子图,显示深度为3的决策树回归器的回归预测结果
plot_regression_predictions(tree_reg2, X, y, ylabel=None)
for split, style in ((0.1973, "k-"), (0.0917, "k--"), (0.7718, "k--")):
plt.plot([split, split], [-0.2, 1], style, linewidth=2) # 绘制竖直线表示分裂点
for split in (0.0458, 0.1298, 0.2873, 0.9040):
plt.plot([split, split], [-0.2, 1], "k:", linewidth=1) # 绘制虚线表示分裂点
plt.text(0.3, 0.5, "Depth=2", fontsize=13)
plt.title("max_depth=3", fontsize=14)
plt.show()

# 创建两个决策树回归器,其中tree_reg1没有限制,tree_reg2限制了叶节点的最小样本数
tree_reg1 = DecisionTreeRegressor(random_state=42)
tree_reg2 = DecisionTreeRegressor(random_state=42, min_samples_leaf=10)
# 使用生成的数据(X和y)对两个决策树回归器进行训练
tree_reg1.fit(X, y)
tree_reg2.fit(X, y)
# 创建一个等间隔的X值范围用于回归预测
x1 = np.linspace(0, 1, 500).reshape(-1, 1)
y_pred1 = tree_reg1.predict(x1)
y_pred2 = tree_reg2.predict(x1)
# 创建一个大的图形窗口,包含两个子图
plt.figure(figsize=(11, 4))
# 绘制第一个子图,显示没有限制的决策树回归器的回归预测结果
plt.subplot(121)
plt.plot(X, y, "b.") # 绘制原始数据点
plt.plot(x1, y_pred1, "r.-", linewidth=2, label=r"$\hat{y}$") # 绘制回归预测曲线
plt.axis([0, 1, -0.2, 1.1])
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", fontsize=18, rotation=0)
plt.legend(loc="upper center", fontsize=18)
plt.title("No restrictions", fontsize=14)
# 绘制第二个子图,显示限制了叶节点最小样本数的决策树回归器的回归预测结果
plt.subplot(122)
plt.plot(X, y, "b.") # 绘制原始数据点
plt.plot(x1, y_pred2, "r.-", linewidth=2, label=r"$\hat{y}$") # 绘制回归预测曲线
plt.axis([0, 1, -0.2, 1.1])
plt.xlabel("$x_1$", fontsize=18)
plt.title("min_samples_leaf={}".format(tree_reg2.min_samples_leaf), fontsize=14)
plt.show()

上面提供的两段代码演示了不同树的深度对决策树模型在回归任务中的影响。
第一段代码:
- 创建了两个深度不同的决策树回归器,分别是
tree_reg1(深度不限制)和tree_reg2(深度受限制)。 - 通过训练这两个回归器,可以观察它们在回归任务中的不同表现。
- 绘制了两个子图,分别显示了这两个回归器的回归预测结果。
tree_reg1没有深度限制,因此可以完全拟合训练数据,但可能出现过拟合。而tree_reg2限制了叶节点的最小样本数,使得模型更具泛化能力,但可能会欠拟合。
第二段代码:
- 创建了两个决策树回归器,其中
tree_reg1没有限制,tree_reg2限制了叶节点的最小样本数。 - 使用这两个回归器对数据进行回归预测,并将结果可视化。
- 第一个子图展示了没有限制的决策树回归器(
tree_reg1)的回归预测结果。它可以完全拟合训练数据,但容易受到噪声的影响,可能会出现过拟合。 - 第二个子图展示了限制了叶节点最小样本数的决策树回归器(
tree_reg2)的回归预测结果。它在拟合上稍微受限,但更具有泛化能力,能够更好地适应新的数据。
这两段代码的目的是展示了在回归任务中,通过调整决策树的深度和叶节点的最小样本数等参数,可以控制模型的复杂度和拟合效果,以便更好地满足实际问题的需求。














 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









