






学习时间:
- 6.12 ~ 6.17
学习笔记:
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
论文链接:https://arxiv.org/pdf/2305.06500.pdf
代码链接:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip

这篇文章主要介绍了Saleforce发布的图像语言多模态大模型InstructBLIP,作者基于预训练的BLIP-2模型对视觉语言指导微调进行了系统全面的研究。在InstructBLIP模型中,充分利用BLIP-2模型中的Q-Former架构,提出了一种指令感知的视觉特征提取方法。
指令感知(instruction-aware )的视觉模型可以增强模型从不同指令中学习和遵循的能力。作者给出了两个例子:
- 给定相同的图像,模型被指导完成两个不同的任务;
- 给定两个不同的图像,模型被指导完成相同的任务。
在第一个例子中,指令感知的视觉模型可以根据指令从相同的图像中提取不同的特征,以解决不同的任务,产生更有信息量的特征;在第二个例子中,指令感知的视觉模型可以利用指令中体现的共同知识来提取两个不同图像的特征,实现更好的图像之间的知识迁移。
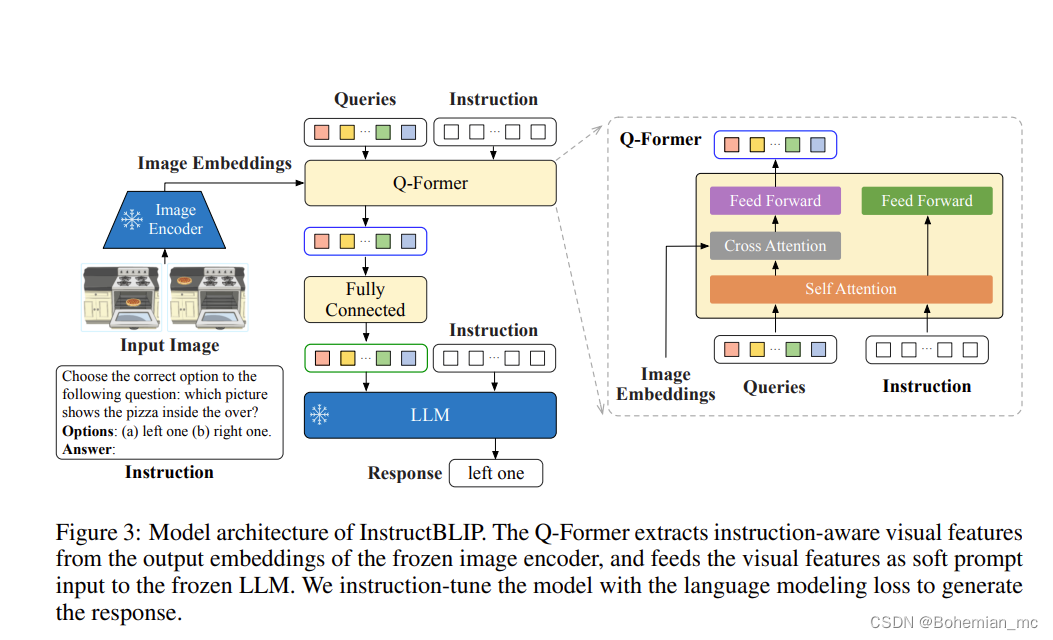
具体而言,一组可学习的查询嵌入通过交叉注意力层与冻结的图像编码器进行交互。这些查询的输出特征随后被映射为输入视觉提示,提供给冻结的LLM。
根据BLIP-2论文的方法,Q-Former已经分成两个阶段进行了预训练,通过预训练,它学会了提取可以被LLM消化的文本对齐的视觉特征,进而在推理过程中,通过将指令附加在视觉提示后引导LLM执行特定的任务。
而在InstructBLIP中,指令文本不仅作为输入给到LLM,同时也给到了QFormer,这样做的好处是:指令通过Q-Former的自注意力层与查询进行交互,影响查询提取与指令所描述的任务更相关的图像特征。因此,LLM能接收到更有用的视觉信息,以更好地完成任务。
VALOR代码学习
上周学习的论文“VALOR: Vision-Audio-Language Omni-Perception Pretraining Model and Dataset”使用了BERT和CLIP两个预训练模型,实现了图像和文本之间跨模态的语义理解,本周也在研究这篇论文的代码,看懂这两个模型是如何应用的,并尝试在HMN中应用这两个预训练模型。














 2886
2886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









