






最近看过的几篇论文里,VALOR和InstructBLIP模型使用了cross-attention机制,以这两篇论文为基础着重学习cross-attention相关的代码和思路。
学习内容:
- cross-attention机制学习
- lstm与transformer
学习时间:
- 6.26 ~ 7.1
学习笔记:
cross-attention机制学习
1.VALOR
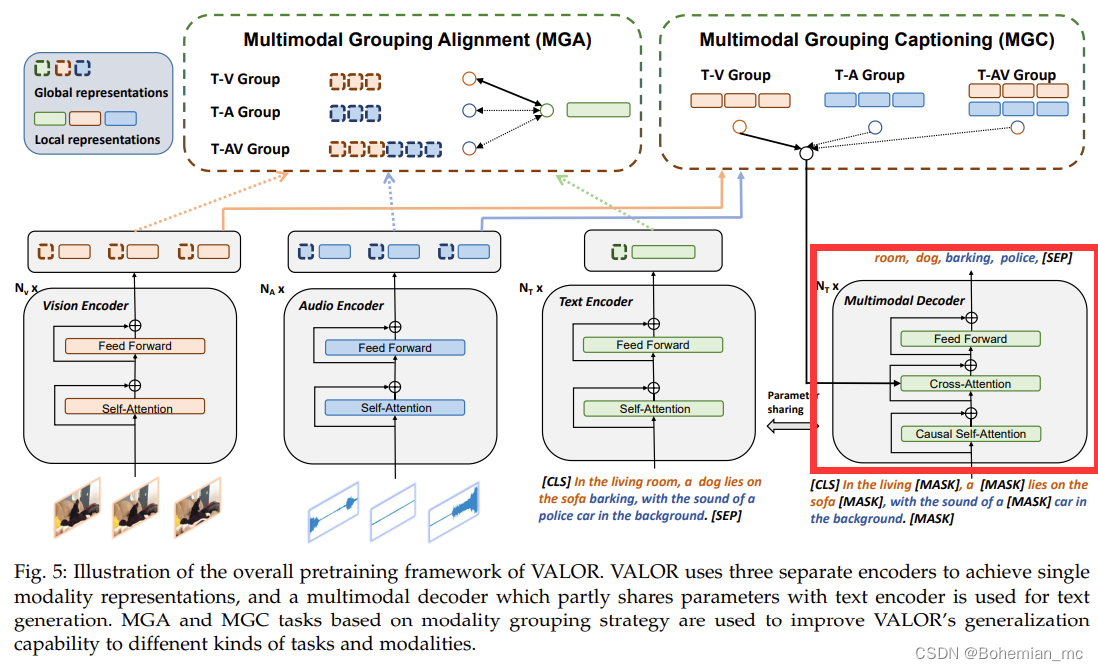
在“Multimodal Decode”中:
首先self-attention层运用causal attention掩码防止信息泄露以及保持自回归推理过程的一致性,然后通过cross-attention层融合文本、视觉、音频这三种模态特征,在融合前沿时间维度将 F a 和 F v F_a和F_v Fa和Fv压缩为两个维度,并通过线形层将这两个特征转换为相同的hidden size。
在代码中,self-attention的 q , k , v q,k,v q,k,v 均为hidden_states。
def forward(self, hidden_states, attention_mask, use_cache=False, cache=None, cache_first=False, layer_num=0, cache_type='unimlm'):
mixed_query_layer = self.query(hidden_states) ### b,n,c
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer) # b,h,n,c
key_layer = self.transpose_for_scores(mixed_key_layer) # b,h,n,c
value_layer = self.transpose_for_scores(mixed_value_layer) # b,h,n,c
cross-attention的 q q q 为hidden_states,但 k , v k,v k,v 为cross_hidden_states。而cross_hidden_states就是MGC得到的分组结果(T-V、T-A、T-AV),当不使用音频特征时,计算代码为:
elif video_feat is not None and audio_feat is None:
attention_output, cache = self.cross_attn(attention_output, None, video_feat)
hidden_states为self_attention的输出,而self_attention的输出是由输入的token序列得到的,cross_hidden_states为video_feat:
elif video_feat is not None and audio_feat is None:
attention_output, cache = self.cross_attn(attention_output, None, video_feat)
因此,在Bert模型里是对text_feat和video_feat做了交叉注意力计算。
在HMN里没有能够直接与video_feat维度匹配的语义信息,而且在bert里输入序列经过mask操作替换和修改了一些内容。
lstm 与 transformer
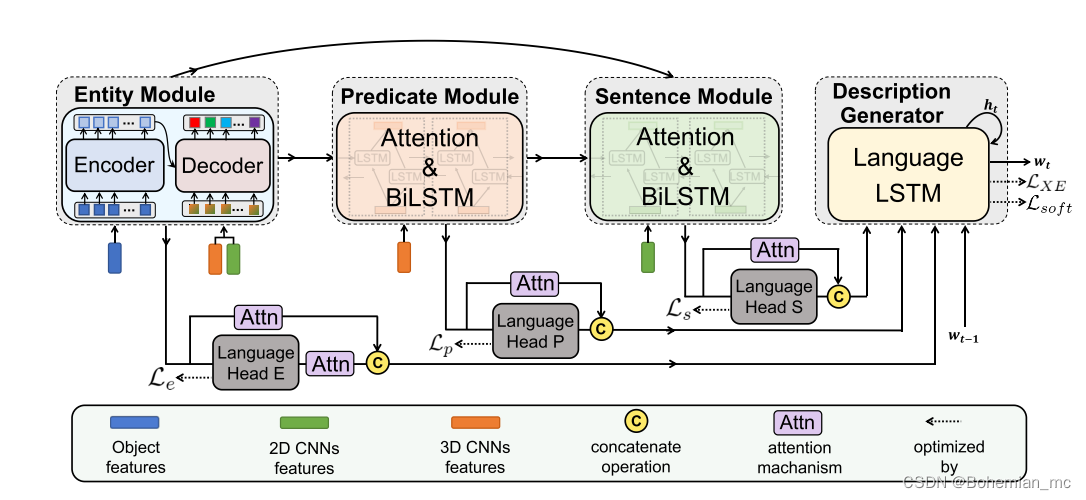
HMN里只在entity module里使用了transformer,而predicate module、sentence module以及最后的description generator都使用的是lstm,可以考虑将lstm替换为transformer,然后在transformer里使用cross-attn计算entity_feat、action_feat、video_feat之间的交叉注意力分数,但需要设计相应的mask、padding_mask,还要再深入研究一下。















 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









