






学习目标:
- 深度学习花书
- 一篇A类会议论文
学习内容:
- 蒙特卡罗方法——深度学习第十七章
- GL-RG: Global-Local Representation Granularity for Video Captioning(IJCAI 2022)
- 了解退火算法
- 认识MSR-VTT 和 MSVD
- 了解BLEU,METEOR,ROUGE,CIDEr四种评价指标
- 了解强化学习
学习时间:
- 9.12 ~ 9.17
学习输出:
蒙特卡罗方法——深度学习第十七章
假设我们数据的概率分布是 p ( x ) p(x) p(x) ,我们要求在这一分布上函数 f ( x ) f(x) f(x) 的期望,即 s = ∑ x p ( x ) f ( x ) = E p [ f ( x ) ] s=\sum_xp(x)f(x)=E_p[f(x)] s=∑xp(x)f(x)=Ep[f(x)] ,蒙特卡洛方法即是通过从 p ( x ) p(x) p(x) 中采样n个样本 x ( 1 ) , . . . , x ( n ) x^{(1)},...,x^{(n)} x(1),...,x(n) ,并用经验平均值(empirical average) 来近似s,即 s ^ n = 1 n ∑ i = 1 n f ( x ( i ) ) \hat s_n=\frac{1}{n}\sum_{i=1}^nf(x^{(i)}) s^n=n1∑i=1nf(x(i)) 。
为什么我们可以采用经验平均值来近似真实的期望呢?一是 s ^ n \hat s_n s^n 是无偏估计(unbiased estimation),即 E [ s ^ n ] = 1 n ∑ i = 1 n E [ f ( x ( i ) ) ] = 1 n ∑ i = 1 n s = s E[\hat s_n] = \frac{1}{n}\sum_{i=1}^nE[f(x^{(i)})] = \frac{1}{n}\sum_{i=1}^ns=s E[s^n]=n1∑i=1nE[f(x(i))]=n1∑i=1ns=s ,且根据大数定理,如果样本 x ( i ) x^{(i)} x(i) 是独立同分布,则 l i m n → ∞ s ^ n = s lim_{n\rightarrow\infty} \hat s_n = s limn→∞s^n=s ,另一方面, s ^ n \hat s_n s^n 的方差与采样量n是成反比的,当采样量足够多时,我们可以很好的近似真实期望。
观察求和形式 p ( x ) f ( x ) p(x)f(x) p(x)f(x) 我们可以发现如何选取 p ( x ) p(x) p(x) 和 f ( x ) f(x) f(x) 并不是唯一的,即我们总可以将其分解为 p ( x ) f ( x ) = q ( x ) p ( x ) f ( x ) q ( x ) p(x)f(x)=q(x)\frac{p(x)f(x)}{q(x)} p(x)f(x)=q(x)q(x)p(x)f(x) 的形式而不改变求和结果,我们可以将 q ( x ) q(x) q(x) 当做新的 p ( x ) p(x) p(x) 而 p ( x ) f ( x ) q ( x ) \frac{p(x)f(x)}{q(x)} q(x)p(x)f(x) 当做新的 f ( x ) f(x) f(x) 。因此,我们可以从分布 q ( x ) q(x) q(x) 中取样,并利用 s ^ q = 1 n ∑ i = 1 , x ( i ) ∼ q n p ( x ( i ) ) f ( x ( i ) ) q ( x ( i ) ) \hat s_q = \frac{1}{n} \sum_{i=1,x^{(i)}\sim q}^n \frac{p(x^{(i)})f(x^{(i)})}{q(x^{(i)})} s^q=n1∑i=1,x(i)∼qnq(x(i))p(x(i))f(x(i)) 求 f ( x ) f(x) f(x) 的期望,这一方法被称作重要采样importance sampling。那么我们什么时候需要importance sampling而不是直接从 p ( x ) p(x) p(x) 中取样呢?有时是因为相较于 p ( x ) p(x) p(x) , q ( x ) q(x) q(x) 更方便采样,或者 q ( x ) q(x) q(x) 可使预测的方差更小。通过importance sampling的式子我们可以得到 E q [ s ^ q ] = E p [ s ^ p ] = s E_q[\hat s_q] = E_p[\hat s_p] = s Eq[s^q]=Ep[s^p]=s ,即 s ^ q \hat s_q s^q 也是无偏估计,并且当 q ∗ ( x ) = p ( x ) ∣ f ( x ) ∣ Z q^*(x)=\frac{p(x)|f(x)|}{Z} q∗(x)=Zp(x)∣f(x)∣ ,其中 Z Z Z 是使 q ∗ ( x ) q^*(x) q∗(x) 归一的常数, V a r [ s ^ q ] = 0 Var[\hat s_q]=0 Var[s^q]=0 ,即当分布q取为 q ∗ ( x ) q^*(x) q∗(x) 时,我们仅需要从中采样一个样本就可计算真实期望。当然,最优的 q ∗ ( x ) q^*(x) q∗(x) 需要计算原求和,我们又回到最初的问题,实际上无法采用,不过这有助于理解选取合适的 q ( x ) q(x) q(x) 可以有效的减小方差。
在章节——结构化概率模型中提到,有向图可以用ancestral sampling的方法采样,而对于无向图由于没法进行拓扑排序不能用ancestral sampling,解决方法之一是利用马尔可夫链蒙特卡罗方法(Markov Chain Monte Carlo, 简称MCMC)。
Markov Chain的核心思想是我们最初可以随机的选取初始状态,再不断的更新这一状态,最终使其分布近似于真实分布 p ( x ) p(x) p(x) 。假设Markov Chain可以由一序列状态 S 0 , S 1 , . . . S_0,S_1,... S0,S1,... 来表示,其中 S i ∈ 1 , 2 , . . . , d S_i\in {1,2,...,d} Si∈1,2,...,d ,代表系统可取的各种状态。初始状态满足 p ( S 0 ) p(S_0) p(S0) 分布,而之后的分布是依赖于前一时间点的条件概率分布,即 p ( S i ∣ S i − 1 ) p(S_i|S_{i-1}) p(Si∣Si−1) 。Markov假设对于每一步i, p ( S i ∣ S i − 1 ) p(S_i|S_{i-1}) p(Si∣Si−1) 是相同的,即当前状态仅依赖于前一时刻状态,而不依赖于其他历史状态。我们可以用转移矩阵来表示这一概率 T i j = p ( S n e w = i ∣ S p r e v = j ) T_{ij}=p(S_{new}=i|S_{prev}=j) Tij=p(Snew=i∣Sprev=j) ,假设初始的 S 0 S_0 S0 分布为 p 0 p_0 p0 ,则经过 t t t 步采样后,概率分布为 p t = T t p 0 p_t = T^tp_0 pt=Ttp0 ,其极限 π = l i m t → ∞ p t \pi = lim_{t\rightarrow\infty}p_t π=limt→∞pt 被称作平稳分布(stationary distribution),在进入平稳分布后,后续的每一步 S ′ = T S = S S'=TS=S S′=TS=S ,即进入稳态分布后,随着更多的采样的进行,分布并不会再进行改变。那么,在什么条件下,存在稳态分布呢?以下两条构成充分条件:
1.不可约性(Irreducibility),在有限步骤中,可以从任一状态S到达另一状态S’。这一条件保证不存在我们无法离开的黑洞状态。
2.非周期性(Aperiodicity),任意时刻可以返回任意状态,即对于 n ′ ≥ n n'\geq n n′≥n , P ( S n ′ = i ∣ S n = i ) > 0 P(S_{n'}=i|S_n=i)>0 P(Sn′=i∣Sn=i)>0 。这一条件保证我们不存在这样的转移矩阵 T = [ 0 1 1 0 ] T=\begin{bmatrix} 0 & 1 \\ 1 & 0 \end{bmatrix} T=[0110] ,即在两个状态间来回变动而不能达到平稳分布。
为了满足以上条件,通常在利用MCMC方法时,我们采取基于能量的模型 p ( x ) ∝ e x p ( − E ( x ) ) p(x) \propto exp(-E(x)) p(x)∝exp(−E(x)) 。
假设我们有了转移矩阵为T且平稳分布为p的Markov Chain,我们怎么进行MCMC取样呢?
假设初始状态为 x 0 x_0 x0 ,则我们先进行B次步进,使Markov Chain达到稳态,这一过程称为burn in,这一过程所需的时间称为混合时间(mixing time)。达到稳态后,我们再进行若干次Markov Chain采样,并利用这些样本来近似估计期望。当然实际应用中,达到稳态后,连续两次取样间还是强相关的,所以通常是采取每n次连续markov chain操作后取一个样本。为了使取样是相互独立的,我们也可以同时进行多个Markov Chain取样。
那么如何选取合适的转移操作使平稳分布接近真实分布p呢?一种方法是吉布斯采样(Gibbs Sampling),即对于每一个变量,从依赖于图中其邻居节点的条件概率分布p中采样,对于相互条件独立的变量,我们也可以同时进行Gibbs Sampling。以如下所示的简单的无向图作为例子。
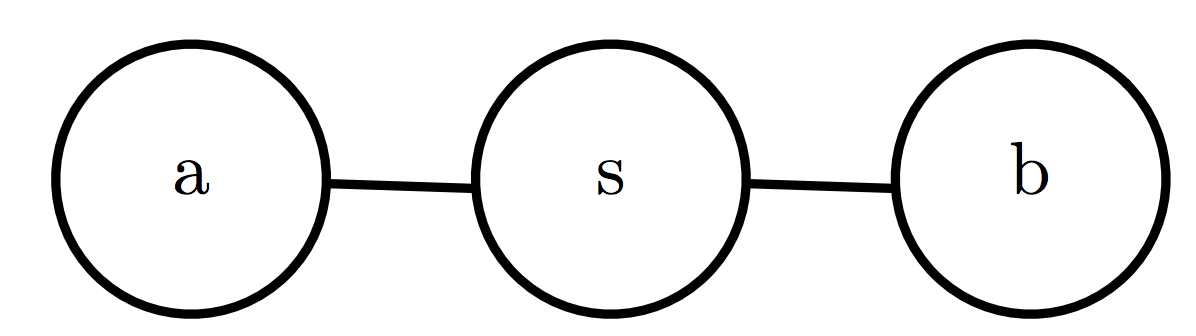
- 随机初始化a,s,b。
- 将下述步骤重复n次:
①从P(a|s)中采样a,从P(b|s)中采样b,由于a,b在s给定的条件下是条件独立的,所以a,b的采样可以同时进行。
②从P(s|a,b)中采样s。
Gibbs Sampling是Metropolis-Hastings采样算法的一种特殊形式,这一类采样方法会收敛于真实分布p。
利用MCMC方法的难点是如何判断我们已经达到稳态,暂时还没有明确的理论指导markov chain是否到达稳态,何时能到达稳态,所以需要一些直观判断方法如人为的检验样本或观察连续采样间的关联。
另一个难点是混合时间过长,尤其是对于维数较多,变量间关联较强或者有若干峰值的概率分布,其混合时间很长。对于有若干峰值的情况,我们可以通过引入一个反比于温度(来源于统计物理概念)的参数 β \beta β 来改变基于能量的模型的分布 p β ( x ) ∝ e x p ( − β E ( x ) ) p_\beta (x) \propto exp(-\beta E(x)) pβ(x)∝exp(−βE(x)) ,当 β < 1 \beta<1 β<1 时,我们可以有效地混合不同峰值的分布。
退火算法
很多优化算法的灵感都源自于自然界和社会生活,比如蚁群算法(ant colony optimization)、遗传算法(Genetic Algorithm) ,而退火算法的灵感来自于金属加工、铸造的流程,也叫作模拟退火算法 (Simulated annealing)。
首先需要知道在金属加工、铸造过程中如何实现退火:

对金属棒进行加热、再让其自然冷却的过程称之为退火。经过退火处理后的金属棒,可以进行弯折,进而用于打造不同形状的器件。退火算法的原理则是利用了高温环境下分子动能(活性)增大的特性。
而在深度学习领域,常常需要搜寻问题的最优解,这个过程类似于在一片山脉区域中寻找最高峰,当一名蒙眼攀登者被随机放置在山脉区域中,当攀登者的下一步选择能够使其海拔上升,则接受该方案,否则不改变位置:

这种方案很容易陷入局部最优,如果我们借助模拟退火算法,让攀登者在初始状态保持较大的活性(体力足够),那么攀登者便有可能会在达到局部最高的山峰(局部最优解)时继续尝试攀爬其他的山峰,需要注意的是,这里所说攀登者的活性(体力)在整个攀登过程中是不断下降的,因此在后期随着活性的下降,攀登者将以更接近传统爬山算法的方式找到全局最优解。
如果理解了上述过程,不难发现退火算法也无法保证能够获取全局最优解,只能说该方法增加了找到最优解的概率。在实践操作中,需要对初始活性、活性衰减速度等参数组合进行调试比较,以便找到适合自己案例的设置。
MSR-VTT 和 MSVD 数据集
MSR-VTT(Microsoft Research Video to Text)
是一种新的大规模视频理解基准,是视频文本翻译的新兴课题。它从一个商业视频搜索引擎了收集257个热门查询,每个查询包括118个视频。在当前版本中,MSR-VTT提供了10K个网络视频片段,时长41.2小时,剪辑-句子对总数为200K,涵盖了最全面的类别和多样化的视觉内容,代表了最大的句子和词汇集。每段视频都由1327名AMT工作人员注释了约20句自然句子。

- 官方分区使用6513个剪辑进行训练,497个剪辑用于验证,其余2990个剪辑用于测试。
- 对于的划分,有6656个剪辑用于训练,1000个剪辑用于测试。
- 分区分别使用7010和1000个剪辑进行训练和测试。由于最后两个数据分区没有提供验证集,我们通过从MSR-VTT中随机抽取1000个片段来构建一个验证集。
MSVD(Microsoft Research Video Description Corpus)
MSVD包含1970个视频,每个视频剪辑包含40个句子。我们使用标准拆分,1200个视频用于培训,100个视频用于验证,670个视频用于测试。

- 这个数据集包含 1970个短视频,10-25s,平均时长为9s,视频包含不同的人,动物,动作,场景等。
- 每个视频由不同的人标注了多个句子,大约41 annotated sentences per clip,共有 80839个sentences,平均每个句子有8个words,这些所有的句子中共包含近16000个 unique words。
- caption中包括多国的语言进行描述,部分论文中采取只选用laguage = english 的caption 进行训练和测试。
BLEU,METEOR,ROUGE,CIDEr
1.BLEU
BLEU(Bilingual Evaluation understudy),双语互译质量评估,是一种流行的机器翻译评价指标,一种基于精确度的相似度量方法,用于分析候选译文中有多少 n 元词组出现在参考译文中,由IBM于2002年提出。在自然语言处理(NLTK) 中, 其允许用户显式指定不同的N-grams的权重以便来计算BLEU的值。这使得用户可以灵活的计算不同类型的BLEU值, 比如独立的BLEU或者累积的BLEU。
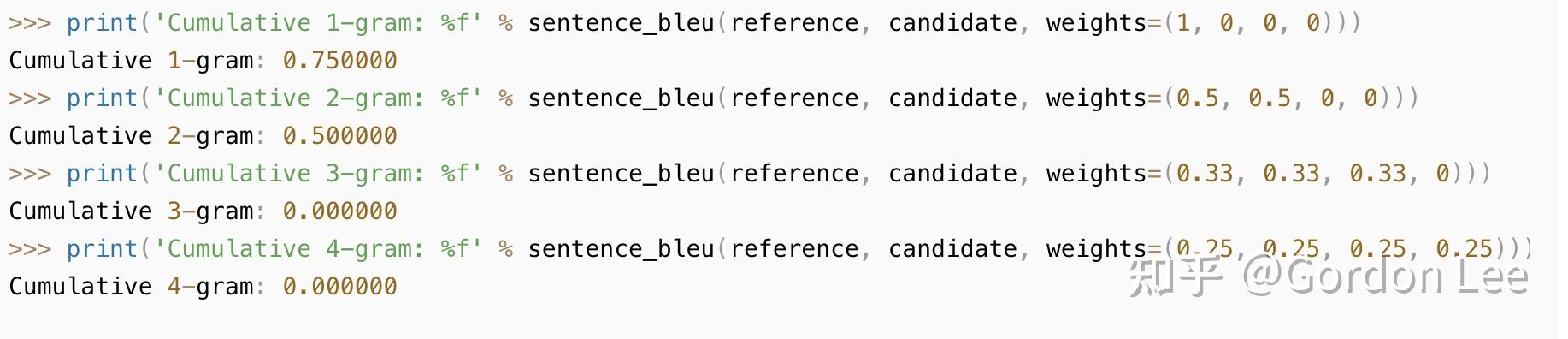
对BLEU-4 容易产生的误解:
- BLEU-4并不是只看4-gram的情况,而是计算从1-gram到4-gram的累积分数,加权策略为 1-gram, 2-gram,3-gram和4-gram 的权重各占25%。
- 默认情况下, sentence_bleu()和corpus_bleu()都是计算累积的4-gram BLEU分数的,
也称之为BLEU-4。 - 下面的不同权重的累积BLEU分别叫做:BLEU-1,BLEU-2,BLEU-3,BLEU-4
2.ROUGE
BLEU更关注翻译结果的准确性和流畅度;而到了神经网络翻译时代,神经网络很擅长脑补,自己就把语句梳理得很流畅了,这个时候人们更关心的是召回率,也就是参考译文中有多少词组在候选译文中出现。
ROUGE(recall-oriented understanding for gisting evaluation) 就是一种基于召回率的相似性度量方法,主要考察参考译文的充分性和忠实性,无法评价参考译文的流畅度,它跟BLEU的计算方式几乎一模一样,但是 n-gram 词组是从参考译文中产生的。分为4种类型:
| ROUGE | 解释 |
|---|---|
| ROUGE-N | 基于 N-gram 的共现(共同出现)统计 |
| ROUGE-L | 基于最长共有子句共现性精度和召回率 Fmeasure 统计 |
| ROUGE-W | 带权重的最长共有子句共现性精度和召回率 Fmeasure 统计 |
| ROUGE-S | 不连续二元组共现性精度和召回率 Fmeasure 统计 |
3.METEOR
METEOR关注到那些翻译准确、但是和候选译文对不上的参考译文,比如参考译文用了候选译文的同义词。METEOR 需要 WordNet 扩充同义词集,同时需要考虑单词词性(比如like、likes应该都算对);在计算方式上它融合了准确率、召回率,利用二者的调和平均值来作为评判标准。
4.CIDEr
CIDEr 首先将 n-grams 在参考译文中出现的频率编码进来,通过TF-IDF 计算每个 n-gram 的权重,将句子用 n-gram 表示成向量的形式,然后计算参考译文和候选译文之间的 TF-IDF 向量余弦距离,以此度量二者的相似性。
强化学习
强化学习是一种最接近于人类的学习。强化学习的基本思想是通过试错(Trail-and-Error) 来学习。试错分为两步:首先是智能体(agent)通过与特定的环境进行交互,观查结果,例如获得奖励或惩罚;然后,记住与特定环境交互的结果,得到自己的优化策略。优化策略的目标就是最大化奖励,即尽可能获得更多的奖励,获得更少的惩罚,这很像动物的趋利避害行为。所以,强化学习是一种以目标为导向,通过交互进行学习的学习方式。
与其他机器学习相比,强化学习有以下特点:
(1)强化学习没有监督数据,只有一个奖励信号。
(2)反馈是有延迟的,即延迟奖励,为了最大化奖励,可能牺牲当前奖励。
(3)时间序列是很重要的因素。
(4)当前的行为影响后续收到的数据。















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









