







在学习spark之前我们应该已经学习了Scala语法,spark是通过scala语言编写的,对scala语言的支持较好
目录
一、spark的搭建模式
local:一般用于测试代码和学习的
standalone:用的是spark自身的集群,spark自身提供了计算资源,由一个主节点Master和其余的从节点Worker构成提交任务有2种方式,cient(客户端)和cluster(集群)模式,client模式的driver端在本地启动,运行日志也会在本地打印,数据量一大,所有日志拉到一台机器上导致网卡流量激增,机器可能崩溃;cluster模式的日志不会在本地打印,可以通过外部UI查看(在spark的端口:8080,查看到运行日志信息),diver端存在集群中随机的一台机器
mesos:Spark on Mesos模式中,Spark程序所需要的各种资源,都由Mesos负责调度。由于Mesos和Spark存在一定的血缘关系,因此,Spark这个框架在进行设计开发的时候,就充分考虑到了对Mesos的充分支持,因此,相对而言,Spark运行在Mesos上,要比运行在YARN上更加灵活、自然。目前,Spark官方推荐采用这种模式.
yarn:Spark可运行于YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,资源管理和调度依赖YARN,分布式存储则依赖HDF
spark on yarn提交任务有也是2种方式,cient(客户端)和cluster(集群)模式,client模式的driver端在本地启动,运行日志也会在本地打印,;cluster模式的日志不会在本地打印,可以通过命令(yarn logs -applicationId 程序的id)进行查看,diver端存在集群中随机的一台机器
k8s:是一种容器化部署方式,可以让用户对应用的管理更加方便
二、 spark中的一些重要名词的功能及内部组成
Driver:spark程序中除了算子内部的代码都是Driver端的内容,负责资源的申请(申请多少内存,核数)和调度(发送task到executor中)
Executor:集群中每一个节点上的一个jvm进程,里面包含的内容非常丰富:
一个线程池(taskpool),用于运行发送到executor中的task
Blockmanager:4样功能,ConnectionManager,BlockTransferService,MenmoryStore,DiskStore
cpu和内存,计算资源和存储资源(Resource Manager分配)


blockmanager主要用于管理以下的三种数据

三、RDD
RDD称为弹性分布式数据集,是spark中的基本数据处理模型,代码中他是一个抽象类,他是一个弹性的,不可变,可分区,里面的元素可并行计算的集合
下面的对RDD特点的一些补充
1.弹性:存储弹性:内存与磁盘自动切换
容错弹性:数据丢失可以自动恢复
计算弹性:计算出错可以重试机制
分片弹性:根据需要可以重新分片(分区)
2.分布式:数据存储在大数据集群中的不同节点上
3.数据集:RDD不保存数据,他封装了计算逻辑,我的理解:从数据开始源头,经历第一个RDD的处理逻辑后,计算结果传递给下一个RDD,RDD本身没有数据记录。只是在使用的时候会调用里面的计算逻辑
4.数据抽象:RDD是一个抽象类,需要子类实现,比如RDD[Int],RDD[String],RDD[(String, Iterable[String])]
5.不可变:RDD的计算逻辑确定下来就不可再更改,只能重新创建新的RDD封装新逻辑
6.可分区,并行计算
rdd5大特性

对上面内容的一些补充
1.rdd的最开始的分区是由文件的切片数决定的,一个文件至少生成了一个切片,一个切片就对应了一个分区
2.每个分区都会使用RDD里面的计算逻辑,他们的计算逻辑都是相同的,一个分区对应了一个Task
3.RDD直接的依赖关系,最后一个RDD肯定是上一个RDD的基础上通过新的计算逻辑得到的,所以一个一个有向上依赖的关系。这种依赖一个对一个的称为窄依赖,与之对应的有宽依赖:一个父节点可以是多个节点的的依赖,形成一对多的情况。
4.分区器,数据进行分区的基础,保证数据得先是kv类型
5.首选位置:判断计算(task)发送到哪个节点,效果最优,如果计算节点和文件存储节点不在一块,还需要通过网络IO传输,无形中降低了性能。所以移动数据不如移动计算,文件存储在哪个节点,计算任务发到相应节点。
创建rdd的3种方法
1、parallelize:通过scala中的集合创建RDD,一般是Array和List创建的
val RDD1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5))
val RDD2: RDD[(Int, Int)] = sc.parallelize(Array((6,7),(1,2)))2、 makeRDD,底层还是调用parallelize
val RDD3: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5))
val RDD4: RDD[(Int, Int)] = sc.makeRDD(List((6,7),(1,2)))3、读取文件创建RDD
val stuRDD=sc.textfile("spark/data/students.txt")4.常见的算子
转换算子(transformation)
由一个算子变成另外一个算子
map:传入一个函数,对RDD中的每一条数据按照这个函数的内容处理,返回值自定义
val listRDD = sc.parallelize(List(1, 2, 3, 4, 5))
listRDD.map(_*2).foreach(println)
//输出结果:2,4,6,8,10flatMap:要求返回值类型是集合类型,会把这个返回的集合打开
val strRDD=sc.makeRDD(List("hello,world","java,scala,spark","sum,moon"))
strRDD.filter(string=>string.split(",")).foreach(println)
//输出:hello,world,java,scala,spark,sum,moonfilter:传入一个函数,要求返回值类型是boolean类型,true就留下这个数据,false被过滤掉
val strRDD=sc.makeRDD(List("hello,world","java,scala,spark","sum,moon"))
strRDD.filter(string=>string.startsWith("h")).foreach(println)
//输出: hello,worldgroupby:传入一个自定义函数,函数需要指定根据什么进行分组,返回k-v格式的数据
val arrRDD: RDD[String] = sc.makeRDD(Array("hello","java","java","hello","spark","scala","spark"))
val wordRDD = arrRDD.map(word => (word, 1))
val groupRDD = wordRDD.groupBy(kv => kv._1)
groupRDD.foreach(println)
groupByKey:要求传入的数据是k-v格式,根据key直接为我们分好组,可以看到相比上面的groupby方法,groupByKey方法只是返回了value
val arrRDD: RDD[String] = sc.makeRDD(Array("hello","java","java","hello","spark","scala","spark"))
val wordRDD = arrRDD.map(word => (word, 1))
val groupRDD: RDD[(String, Iterable[Int])] = wordRDD.groupByKey()
groupRDD.foreach(println)
reduceByKey:只能作用在kv格式的数据上;相比较于groupByKey:性能更高但功能较弱
需要接收一个 聚合函数f,一般是 求加和、最大值、最小值;相当于MR中的combiner,只能使用等幂操作,会在Map端进行预聚合,相当于combine
val arrRDD: RDD[String] = sc.makeRDD(Array("hello","java","java","hello","spark","scala","spark"))
val wordRDD = arrRDD.map(word => (word, 1))
val rb_RDD = wordRDD.reduceByKey((i, j) => {
i + j
})
rb_RDD.foreach(println)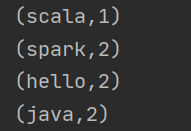
join:我们首先需要准备两个rdd,这2个rdd必须是kv格式,而且key需要相同,key相同的,会把他们的value放入一个元组中作为新的value,key就是连接的key
val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6)))
rdd.join(rdd1).foreach(println)//输出结果(1,(dd,4)) (2,(bb,5)) (3,(aa,6))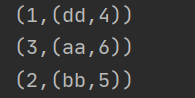
left join/right join:join默认是inner join,有时候可能需要用到left join/right join这种操作
在maysql中,如果id关联上,但是被关联一方的数据为空,是用null填充;在spark中很显然没有这种操作,使用left/right join,被关联方返回的是一个Option类型的数据,如果有数据就是Some类型,没有数据就是None类型
比如我这里写的rdd1里面就没有key是6的,可以看看结果应该是 6,(cc,None)
val rdd: RDD[(Int, String)] = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
val rdd1: RDD[(Int, Int)] = sc.parallelize(Array((1,4),(2,5),(3,6)))
rdd.leftOuterJoin(rdd1).foreach(println)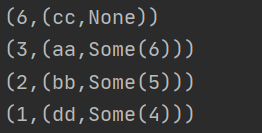
如果要取出Some里面的数据,用case模式匹配很好做
union:连接相同格式的RDD
val RDD1: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val RDD2: RDD[Int] = sc.parallelize(List(6, 7, 8, 9, 10))
val union_RDD: RDD[Int] = RDD1.union(RDD2)
union_RDD.foreach(println)
//输出结果:1 2 3 4 5 6 7 8 9 10不同格式的,你在写的时候就直接报错了

sortBy:指定按照每条数据中具体什么位置进行排序
val RDD3: RDD[(String,Int)] = sc.parallelize(List(("one",3), ("two",2), ("three",1)))
RDD3.sortBy(kv=>kv._2).foreach(println)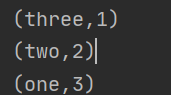
可以在sortBy里面加参数,ascending = false这样就是降序排序
mapParttions:这个算子的作用是向里面写入一个函数,参数是迭代器,返回值自定义
object mapPartitionDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("mapPartitionDemo")
val sc = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/")
linesRDD.mapPartitions((iter:Iterator[String])=>{
println("**mapPartition**")
iter.flatMap(line=>line.split(","))
}).foreach(println)
linesRDD.map(lines=>{
println("**map**")
lines.split(",")
}).foreach(println)
while(true){
}
}
}
打印的数据没什么好说的,结果看起来都一样是把目标文件夹下面的单词都打印出来了
但是**mapPartition**打印了2次,**map**打印了10次
我的data文件夹下是2个文件,都是几十k的小文件,我们读取数据就会产生2个分区
mapPartition算子做了什么事呢?
他是根据分区读取数据,传入一个分区(迭代器)后,再对这个分区的数据进行处理,我用flatmap方法处理这个迭代器
map算子做了什么呢?
他是将每一行的数据读入,然后切分
在将这个打印的标签换成数据库连接的时候就可以感受到2者的差距在哪里
mapPartitionsWithIndex:和上面的方法没啥区别,就是我们可以多查看一个分区号,从0开始计数
linesRDD.mapPartitionsWithIndex((index,iter)=>{
println(index)
iter.flatMap(line=>line.split(","))
}).foreach(println)mapValues:要求传入kv类型数据,仅对value数据进行处理
val mapvRDD = sc.makeRDD(List(("小红",1),("小明",2)))
mapvRDD.mapValues(i=>math.pow(i,2)).foreach(println)
//输出(小红,1.0) (小明,4.0)sample:用来抽样,可以传入参数为withReplacement:是否放回,franction:抽样比例(大概是这么多,但也不一定),seed:随机种子(这个不会)
//从数据源抽样,withReplacement参数指的是不放回抽样,franction是抽取比例,但不是说一个返回这么多,大概在这个范围左右
val sampleRDD: RDD[String] = linesRDD.sample(false, 0.02)行为算子(Action)
每个action算子都会产生一个job
foreach:传入一个函数,没有返回值;对rdd中的每一条数据使用这个函数,我们通常用的就是foreach(println)
take:从RDD中取出前n条数据,放进一个数组
val RDD4: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val arr1: Array[Int] = RDD4.take(2)
arr1.foreach(println)
//输出:1,2collect: 将RDD里面的元素取出放在一个数组中
val RDD4: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
val arr1: Array[Int] = RDD4.collect()
arr1.foreach(println)
//输出:1,2,3,4,5count:数RDD里面有几个元素
val RDD4: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5))
println(RDD4.count())
//输出结果:5reduce:传入一个聚合函数,对RDD的全部数据做聚合
val RDD4: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5))
println(RDD4.reduce((i, j) => i + j))
//输出结果:15saveasTextfile:里面传入保存路径
RDD4.saveasTextFile("spark/data/rdd4")foreachPartition:这是一个行为算子: 需要接收一个函数f:参数类型是Iterator类型,返回值类型为Unit , 会将每个分区的数据传给Iterator并进行最终的处理,一般用于将结果数据保存到外部系统
读取我的本地文件,向数据库中写入数据,我们之前对rdd的操作都是有返回值的,但是现在向数据库写入数据,这是不需要返回值的

import java.sql.{DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object ForeachPartitionDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setAppName("ForeachPartitionDemo")
conf.setMaster("local")
val sc = new SparkContext(conf)
//设置分区为4,这个可以忽略
val linesRDD: RDD[String] = sc.textFile("spark/data/students.txt",4)
val conn = DriverManager.getConnection("jdbc:mysql://master:3306/student?characterEncoding=utf-8&&&useSSL=false","root","123456")
val ps: PreparedStatement = conn.prepareStatement("insert into stu values(?,?,?,?,?)")
linesRDD.foreach(line=>{
val splits = line.split(",")
val id = splits(0).toInt
val name = splits(1)
val age = splits(2).toInt
val gender = splits(3)
val clazz = splits(4)
ps.setInt(1,id)
ps.setString(2,name)
ps.setInt(3,age)
ps.setString(4,gender)
ps.setString(5,clazz)
ps.execute()
ps.close()
conn.close()
})
}
}
我写入的数据是1000行,写一行数据就连接一次数据库再关闭所以上面,这样的操作是不是不大合适
所以需要通过一些方法减少连接次数,我们上面的mapParttions,这个算子还有返回值,但是我们是往数据库里写数据,不需要什么返回值,这时候就用到了foreachPartition
linesRDD.foreachPartition(iter => {
// 连接是不能被序列化的,所以连接的建立需要放入算子内部
// foreach是针对每一条数据处理一次,相当于这里会创建1000次连接 会造成性能问题
// 对每个分区的数据进行处理,相当于每个分区建立一次连接,因为有4个分区,所以只会创建4次连接
// 大大降低连接的创建次数 提高性能
val conn: Connection = DriverManager.getConnection("jdbc:mysql://master:3306/student?characterEncoding=utf-8&&&useSSL=false","root","123456")
val st: PreparedStatement = conn.prepareStatement("insert into stu values(?,?,?,?,?)")
// 这里的foreach方法不是RDD的算子了,这里是Iterator的foreach方法
// 不会出现连接未被序列化的问题,当前处理的分区的数据都会共用一个连接
iter.foreach(line => {
val splits: Array[String] = line.split(",")
val id: Int = splits(0).toInt
val name: String = splits(1)
val age: Int = splits(2).toInt
val gender: String = splits(3)
val clazz: String = splits(4)
st.setInt(1, id)
st.setString(2, name)
st.setInt(3, age)
st.setString(4, gender)
st.setString(5, clazz)
// st.execute() // 相当于每条数据插入一次 性能也比较低
st.addBatch()
})
st.executeBatch() // 采用批量插入的方式
st.close()
conn.close()
})最终数据写入了数据库

四、资源申请和任务调度
粗粒度的资源调度:
(1)spark在任务执行之前就将所有的资源申请下来,
(2)task后续启动不需要额外申请资源,启动速度非常快
(3)资源浪费,等到最后一个task执行结束后才会释放资源;
细粒度的资源调度:
(1)mapreduce是每一个task执行的时候单独申请资源,
(2)执行完成之后立即释放资源,资源利用充分
(3)taks启动速度慢
spark为什么比mapreduce计算要快?
1.spark可以将数据缓存在内存中进行计算
2.spark是粗粒度的资源调度,mapreduce是细粒度的资源调度
3.DAG有向无环图,spark中根据shuffle切分出stage,两次shuffle中间不需要落地,mapreduce的shuffle中间文件需要落地
spark on yarn 资源申请和任务调度总流程:
 任务调度的容错机制
任务调度的容错机制

五、缓存cache
我们在spark代码中如果多次使用一个RDD可以考虑把他缓存起来,因为RDD并不存储数据,只是封装了计算逻辑,遇到一个action算子后,这个RDD会一直回溯到最开始的RDD一步步算过来,我们缓存还是很有用的
cache,默认是将RDD缓存到execotor的memory中,但是内存资源是非常宝贵的,我们的计算资源也需要使用内存,对于内存不足的可以使用磁盘(disk)存储;但是磁盘存储还不是我们想要的,因为在磁盘中寻找数据也需要不少时间,通常情况是2者结合使用,内存放不下了就用磁盘存储,这样保证了我们能快速获取到RDD,也保证了资源的合理分配
cache
是一个转换算子,不会触发job,需要接收
将数据放Excutor内存中,等于 persist(StorageLevel.MEMORY_ONLY)
persist
可以指定缓存级别:
1、是否放内存
2、是否放磁盘
3、是否放堆外内存
4、是否序列化
压缩
好处: 节省
缺点:序列化和反序列化需要浪费cpu执行时间
5、缓存的选择
1.内存足够:MEMORY_ONLY
2.内存不太够,尽可能多的将数据存储到内存中:MEMORY_AND_DISK_SER (数据放入磁盘中需要寻址时间,SER是序列化的意思)
3.内存不够:DISK_ONLY
6.用完记得释放缓存
对多次使用的RDD可以进行缓存,用完用unpersist方法释放
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object CacheDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("CacheDemo")
conf.setMaster("local")
val sc = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("spark/data/students.txt")
val stuRDD1: RDD[String] = stuRDD.map(line => {
println("+++++++++")
line
})
//将RDD存储在内存中,指的是executor中的内存
stuRDD1.cache()
//将RDD存储再磁盘中,不是默认的存储方法使用persist方法
stuRDD1.persist(StorageLevel.DISK_ONLY)
//将RDD存储再内存和磁盘中
stuRDD1.persist(StorageLevel.MEMORY_AND_DISK_SER)
stuRDD1.map(line=> (line.split(",")(4),1))
.reduceByKey((i,j)=>i+j)
.foreach(println)
stuRDD1.map(line=>(line.split(",")(3),1))
.reduceByKey((i,j)=>i+j)
.foreach(println)
}
}全部的缓存选项如下:

六、checkpoint
1.数据备份,将RDD写入hdfs
2.action算子出发job,运行完成后,从最后一个RDD回溯,找到调用了checkpoint的RDD,再开启一个job,重新计算这个RDD,再写入HDFS
优化的地方就是把这个调用checkpoint的RDD的上一个RDD缓存了,就不用再重头计算了
3.checkpoint会切断与前面的RDD的依赖关系

代码模拟:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object CheckPointDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("CacheDemo")
conf.setMaster("local")
val sc = new SparkContext(conf)
//在SparkContext中需要设定好checkpoint的存放位置
sc.setCheckpointDir("spark/data/checkpoint")
val stuRDD: RDD[String] = sc.textFile("spark/data/students.txt")
//checkpoint的前一个RDD缓存起来
stuRDD.cache()
val stuRDD1: RDD[String] = stuRDD.map(line => {
println("+++++++++")
line
})
//直接调用checkpoint方法
stuRDD1.checkpoint()
stuRDD1.map(line=> (line.split(",")(4),1))
.reduceByKey((i,j)=>i+j)
.foreach(println)
}
}可以看见checkpoint文件生成了

七、累加器和广播变量
累加器就是用在算子内部实现数值相加,然后在driver端可以获取到这个结果
通常我们在driver端定义一个常量,虽然在算子内部可以获取这个变量,但是那是对driver端的数据进行复制得到的,你在算子内部对这个变量重新赋值,不会对driver端造成任何的影响,
在driver端定义sc.longAccmulator,算子内部累加,driver端进行汇总
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object AccDemo {
def main(args: Array[String]): Unit = {
/**
* 累加器
*/
// 构建Spark上下文环境
val conf: SparkConf = new SparkConf()
conf.setAppName("AccDemo")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
var i: Int = 1
// 读取students、scores数据
val stuRDD: RDD[String] = sc.textFile("spark/data/students.txt")
println(stuRDD.count())//我这里有1000条数据
//定义累加器
val acc: LongAccumulator = sc.longAccumulator
stuRDD.foreach(line => {
acc.add(1)
})
//最终打印的结果是通过累加器的vaule方法我们获取到了值
println(acc.value)//输出结果1000
}
}广播变量
什么是广播变量?
每个算子内部的代码被封装成task发送到executor中执行,如果在算子内部使用了driver端的变量,每一个task都会复制一个副本放进task中,但是task都是在executor中运行,一个exector中可以运行多个task,没必要复制那么多个副本;所以可以将这个外部变量通过广播变量的方式发送发每个executor上,减少task的占用空间,提升任务的运行效率
广播变量在driver端创建,在executor中使用
广播变量的副本数量等于executor的数量
如果直接将数据封装task中,会产生很多副本,增加网络传输的数据量,降低效率
广播变量不能太大,超过executor的内存,导致OOM
用完记得销毁

比如这个代码,想从stuRDD中筛选出id在driver端定义的列表中人的信息
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
object BroadcastDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setAppName("Demo18ACC")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
// 1、读取students、scores数据
val stuRDD: RDD[String] = sc.textFile("Spark/data/stu/students.txt")
// 定义一个List
val idsList: List[Int] = List(1500100001, 1500100011, 1500100021, 1500100031)
// 如果需要在算子内部使用算子外部的变量,可以将变量进行广播
// 将变量广播到每个Executor中 提高性能
val idsListBro: Broadcast[List[Int]] = sc.broadcast(idsList)
// 从stuRDD中过滤出 idsList中保存的学生,这个列表通常我们想直接用了算了,没有经过广播操作
// Task最终都是在Executor中执行=>>没有必要每个Task放一个副本,可以在每个Executor上放一个副本
// 减少分发Task时网络的开销,提高效率
stuRDD.filter(line => {
// 提取学生id
val id: Int = line.split(",")(0).toInt
// 通过id进行过滤
// 也使用了外部变量 但没有进行修改(不会生效)
// idsList.contains(id)
// 使用广播变量获取算子外部定义的变量
idsListBro.value.contains(id)
}).foreach(println)
}
}
八、分区
1.第一个RDD的分区数量通常是与文件切片的数量相同(TextInputFormat进行切片)
2.后续的RDD分区数量与父RDD的数量保持一致
3.shuffle类算子可以手动设置分区数量,读取文件的时候也可以设置一次分区
最终一个分区对于生成一个文件,我们应该按照文件大小除以block块大小得到一个数,这个数不说直接作为分区数,考虑到产生数据膨胀的可能,再给大点就比较合适了
下面的代码有设置分区的方法
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object PartitionDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("PartitionDemo")
//这个在conf里面设置并行度,只有下面的代码没有对分区数进行改动才能看出来,
// 因为下面一改分区,我也不知道上面到底改没改
conf.set("spark.default.parallelism","4")
val sc: SparkContext = new SparkContext(conf)
//我原来的分区数是2,minPartition设置为3,分区数就会变成更大的那个
//假设我的分区数原来是20,我现在设置minPartition为10,他还是20,因为原理的分区数更大
val stuRDD: RDD[String] = sc.textFile("spark/data/students.txt",3)
val wordsRDD: RDD[String] = stuRDD.flatMap(line => line.split(","))
val wordKVRDD: RDD[(String, Int)] = wordsRDD.map(word => (word, 1))
/**
* 默认的分区数量是等于父分区数量
* reduceByKey是分区类算子,产生shuffle,有一个参数numPartitions可以指定分区的数量
* 额外接收的参数:numPartitions > 通过Spark的参数(spark.default.parallelism)指定 > 默认等于父RDD的分区数量
*/
val word_rbRDD: RDD[(String, Int)] = wordKVRDD.reduceByKey((i, j) => {i + j},4)
println(word_rbRDD.getNumPartitions)
//手动改变RDD的分区数量
val rp_RDD: RDD[(String, Int)] = word_rbRDD.repartition(5)
println("repartition后的分区数量:"+rp_RDD.getNumPartitions)
/**
* coalesce里面第一个参数是分区数量,第二个是shuffle选项(boolean类型)
* 设置的分区数量如果是小于原来的分区数量,可以不管这个shuffle选项,
* 如果你的新设置的分区数量大于原来的需要打开shuffle开关
*/
val coa_RDD: RDD[(String, Int)] = word_rbRDD.coalesce(10)
println("coalesce后的分区数量:"+coa_RDD.getNumPartitions)//4
val coa_RDD1: RDD[(String, Int)] = word_rbRDD.coalesce(3)
println("coalesce后的分区数量:"+coa_RDD1.getNumPartitions)//3
val coa_RDD2: RDD[(String, Int)] = word_rbRDD.coalesce(10,true)
println("coalesce后的分区数量:"+coa_RDD2.getNumPartitions)//10
}
}














 3326
3326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









