






目录
三、划分small_ccpd制成small_ccpd_yolo数据集
1、在ccpd文件夹下新建train.txt和val.txt
一、CCPD2019数据集下载
1、官网下载CCPD数据集
官网:https://github.com/detectRecog/CCPD
2、查看CCPD2019数据集
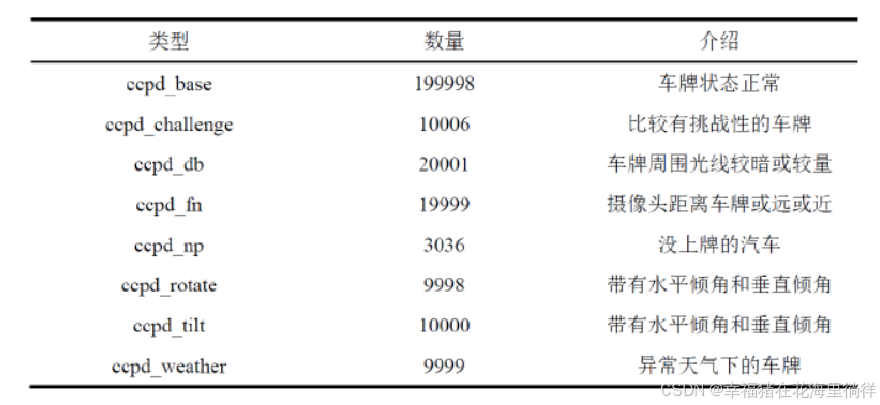
3、CCPD2019数据集说明
二、制作小数据集
因为CCPD2019数据集非常大,有接近30w张车牌图片,因此要全部训练和验证是不现实的,所以我们可以写python脚本来随机选取CCPD2019数据集中的部分文件,制作成一个小的数据集small_ccpd。
1、新建文件夹small_ccpd
在本地新建文件夹Data,再建一个子文件夹small_ccpd,用来存放待会随机选取的图片。
2、从原CCPD数据集中随机选取若干图片
(1)在Pycharm新建项目HuaFenData
(2)新建select_ccpd_data.py文件
注:根据自己需要设置代码中随机选取图片的数量,我这取了5300张
# ccpd_base: 5000
# ccpd_challenge: 50
# ccpd_db: 50
# ccpd_fn: 50
# ccpd_fn: 0
# ccpd_rotate: 50
# ccpd_tilt: 50
# ccpd_weather: 50
# 共5300张图片
from shutil import copyfile
import os
import random
def select_data(src_path, dst_path_1, dst_path_2, num):
dirs = os.listdir(src_path)
random.seed(0)#随机选取图片
data_index = random.sample(range(len(dirs)), num)
data_index.sort(reverse=True)
counter = 0
for image in dirs:
if counter == data_index[-1]:
ret = data_index.pop()
if len(data_index) <= num/10:
copyfile(src_path + f"{image}", dst_path_2 + f"{image}")
else:
copyfile(src_path + f"{image}", dst_path_1 + f"{image}")
if not data_index:
break
counter += 1
if __name__ == "__main__":
# CCPD数据集文件夹位置
root = "E:/Desktop/CCPD/CCPD2019/"
base_path = root + "ccpd_base/"
challenge_path = root + "ccpd_challenge/"
db_path = root + "ccpd_db/"
fn_path = root + "ccpd_fn/"
rotate_path = root + "ccpd_rotate/"
tilt_path = root + "ccpd_tilt/"
weather_path = root + "ccpd_weather/"
dic = {base_path: 5000, challenge_path: 50, db_path: 50, fn_path: 50, rotate_path: 50,
tilt_path: 50, weather_path: 50}#从ccpd2019数据集的各个文件选取n张图片
# 训练集路径
dst_train_path = "D:/Data/small_ccpd/"
# 评估集路径
dst_val_path = "D:/Data/small_ccpd/"
for path in dic:
select_data(path, dst_path_1=dst_train_path, dst_path_2=dst_val_path, num=dic[path])
(3)运行select_ccpd_data.py
(4)查看small_ccpd数据集
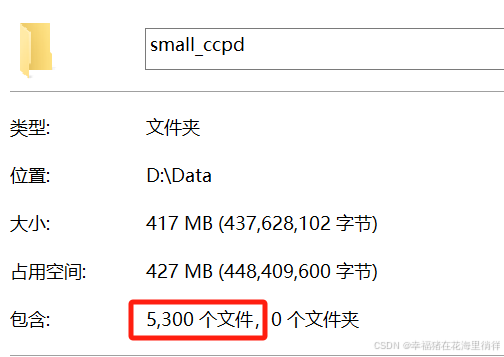
三、划分small_ccpd制成small_ccpd_yolo数据集
small_ccpd下有5300张图片,但这个数据集并不能直接用于训练。用yolov7模型进行训练时要求把数据集划分成训练集、验证集和测试集。因此我们要对small_ccpd进行划分,构成终极数据集small_ccpd_yolo。
1、新建文件夹small_ccpd_yolo
在Data下新建文件夹small_ccpd_yolo,再新建文件夹images,新建训练集train、验证集val和测试集test。

2、新建divide_data.py文件
功能:把small_ccpd数据集进行划分并存储到small_ccpd_yolo中。
在HuaFen项目中新建divide_data.py文件,设置自己想要的划分比(我设置的是8:2:0)。
small_ccpd数据集共有5300图片,故train:val:test=8:2:0=4240:1060:0。
import os
import random
import shutil
from shutil import copy2
trainfiles = os.listdir(r"D:/DATA/small_ccpd") #(源图片文件夹)
num_train = len(trainfiles)
print("num_train: " + str(num_train) )
index_list = list(range(num_train))
print(index_list)
random.shuffle(index_list) # 打乱顺序
num = 0
trainDir = r"D:/Data/small_ccpd_yolo/images/train" #(将图片文件夹中的8份放在这个文件夹下)
validDir = r"D:/Data/small_ccpd_yolo/images/val" #(将图片文件夹中的2份放在这个文件夹下)
detectDir = r"D:/Data/small_ccpd_yolo/images/test" #(将图片文件夹中的0份放在这个文件夹下)
for i in index_list:
fileName = os.path.join(r"D:/DATA/small_ccpd", trainfiles[i]) #(源图片文件夹)+图片名=图片地址
if num < num_train*0.8: # 8:2:0
print(str(fileName))
copy2(fileName, trainDir)
elif num < num_train*1.0:
print(str(fileName))
copy2(fileName, validDir)
else:
print(str(fileName))
copy2(fileName, detectDir)
num += 1
3、运行divide_data.py
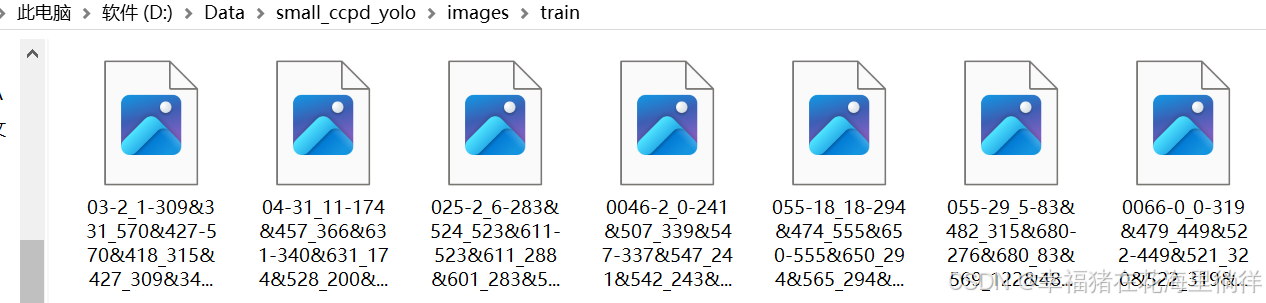
4、查看train和val文件夹下的文件
注:我前面划分的test文件夹比例为0,所以这里我就不示范了。
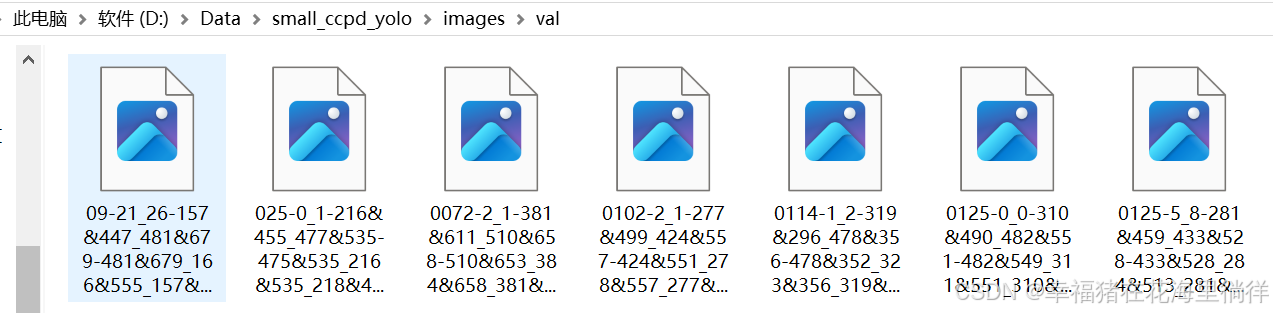
至此,数据集就划分完成了,但是!!yolov7模型进行训练时还要求有图片对应的label,所以这还不算完!!!
四、转换为txt格式
说明:在目标检测领域,YOLO算法是一个流行的选择。为了训练和测试YOLO模型,需要将数据集格式化为YOLO可以识别的格式。三种常见YOLO数据集格式分别是txt、voc、coco。
1、txt格式简单易用,适合初学者和快速原型开发;voc格式适合需要更详细标注信息的项目;而coco格式则因其标准化和通用性,成为许多研究和实际应用的首选。
2、YOLO的txt格式要求图片images和标签labels分别存放在两个文件夹中,并按照一定的比例分为训练集和验证集。每个TXT文件包含目标的类别和边界框的坐标。
1、转化工具
工具:LabelImg,可以对图片进行标注,生成每张图片对应的txt文件。但是!!!ccpd这个数据集就特殊了🤓,这个数据集的检测和识别标签都在图片名中,因此我们可以直接从图片名上读取出来,再写入txt文件中即可!
2、新建文件夹labels
在small_ccpd_yolo下新建文件夹labels,新建train、val
3、新建transform.py文件
功能:把small_ccpd_yolo/images中的每张图片名读取出来,再生成对应的txt文件,写入small_ccpd_yolo/labels
在HuaFen项目中新建divide_data.py文件
import shutil
import cv2
import os
def txt_translate(path, txt_path):
for filename in os.listdir(path):
print(filename)
list1 = filename.split("-", 3) # 第一次分割,以减号'-'做分割
subname = list1[2]
list2 = filename.split(".", 1)
subname1 = list2[1]
if subname1 == 'txt':
continue
lt, rb = subname.split("_", 1) # 第二次分割,以下划线'_'做分割
lx, ly = lt.split("&", 1)
rx, ry = rb.split("&", 1)
width = int(rx) - int(lx)
height = int(ry) - int(ly) # bounding box的宽和高
cx = float(lx) + width / 2
cy = float(ly) + height / 2 # bounding box中心点
img = cv2.imread(path + filename)
if img is None: # 自动删除失效图片(下载过程有的图片会存在无法读取的情况)
os.remove(os.path.join(path, filename))
continue
width = width / img.shape[1]
height = height / img.shape[0]
cx = cx / img.shape[1]
cy = cy / img.shape[0]
txtname = filename.split(".", 1)
txtfile = txt_path + txtname[0] + ".txt"
# 绿牌是第0类,蓝牌是第1类,这里的str(0)就表示绿色车牌(默认值)。
with open(txtfile, "w") as f:
f.write(str(0) + " " + str(cx) + " " + str(cy) + " " + str(width) + " " + str(height))
if __name__ == '__main__':
# det图片存储地址
trainDir = r"D:/Data/small_ccpd_yolo/images/train/"
validDir = r"D:/Data/small_ccpd_yolo/images/val/"
testDir = r"D:/Data/small_ccpd_yolo/images/test/"
# det txt存储地址,txt里面是类别,四个值
train_txt_path = r"D:/Data/small_ccpd_yolo/labels/train/"
val_txt_path = r"D:/Data/small_ccpd_yolo/labels/val/"
test_txt_path = r"D:/Data/small_ccpd_yolo/labels/test/"
txt_translate(trainDir, train_txt_path)
txt_translate(validDir, val_txt_path)
txt_translate(testDir, test_txt_path)
4、运行transfrom.py
5、查看labels下的文件夹
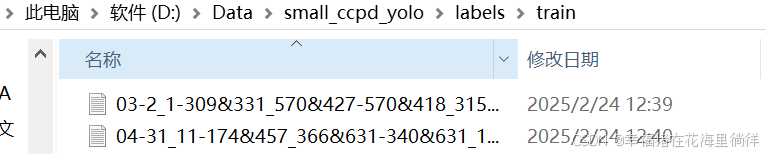
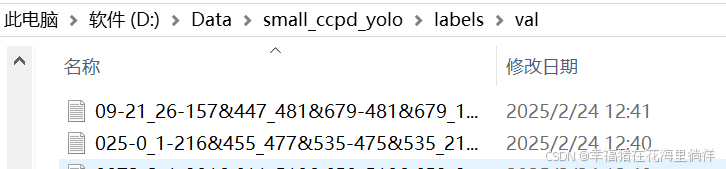

txt的内容就是每张车牌图片对应的信息
6、将最终数据集重命名为ccpd
Now:其他数据集都不重要了,现在我只需要把small_ccpd_yolo拿来用就行!!!这里我又新建了一个文件夹datasets,把small_ccpd_yolo放进来了,重命名为ccpd。方便我放到yolo模型中训练。
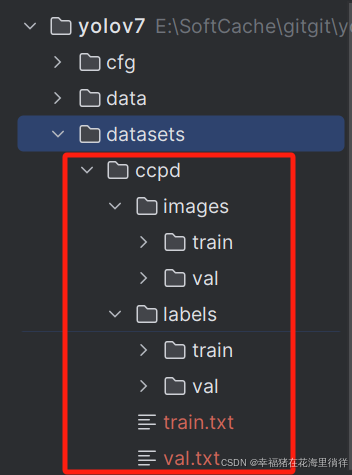
五、新建train.txt和val.txt写入全部图片路径
1、在ccpd文件夹下新建train.txt和val.txt

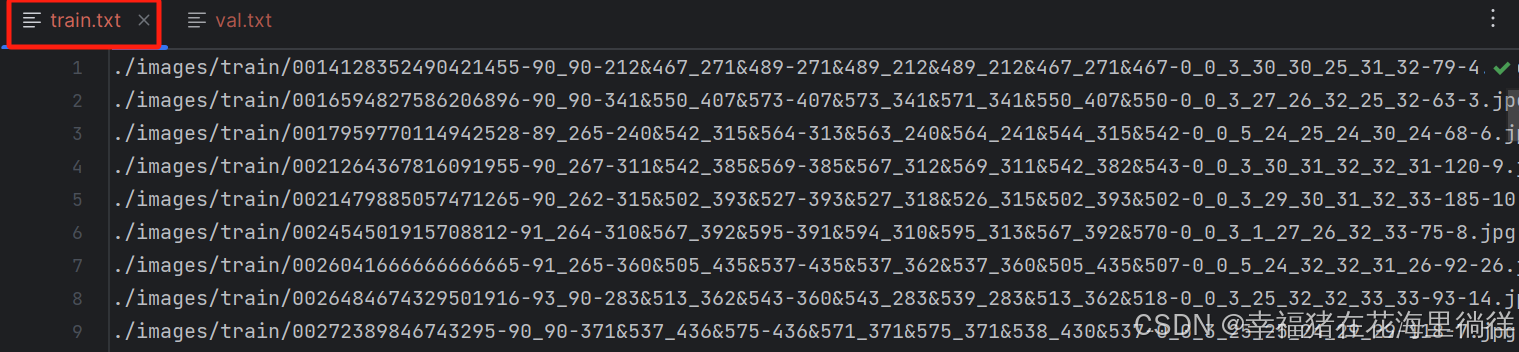
2、编辑train.txt
写入ccpd/images/train下的全部图片路径
ps:有没有什么工具可以一键提取所有图片的路径的?不然自己一个一个写的工作量也太大了吧。。
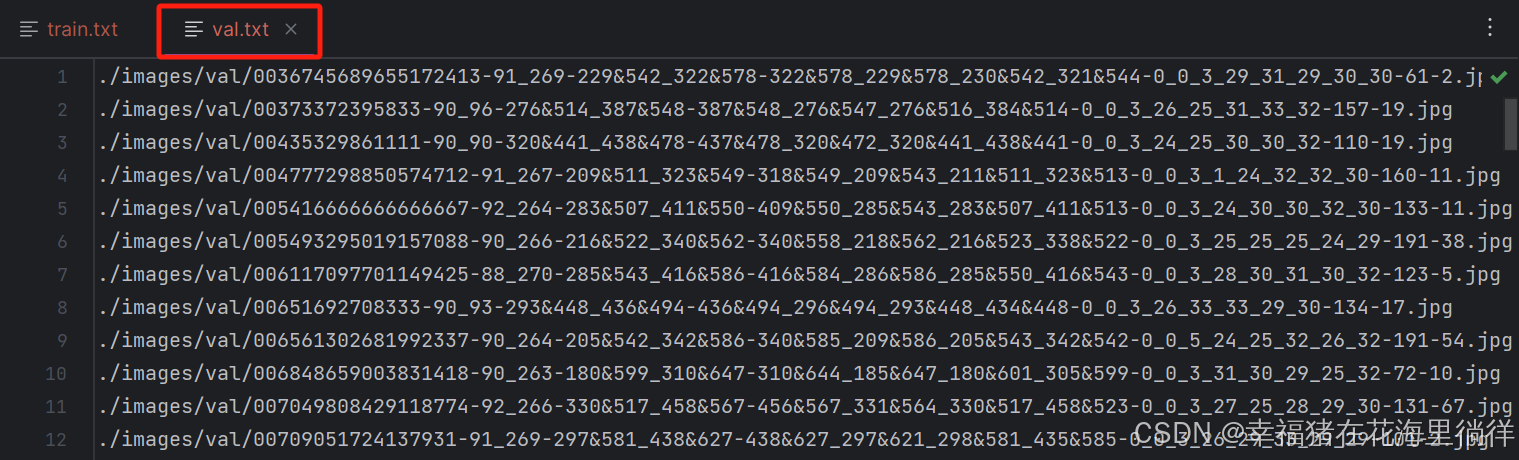
3、编辑val.txt
写入ccpd/images/val下的全部图片路径
至此,符合yolov7训练标准的数据集就彻底制作完成啦!!!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









