






参考官网文档:https://spark.apache.org/docs/latest/graphx-programming-guide.html
构建图,查看图信息
package zzf
import org.apache.spark.graphx._
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object graphx01_graphProperty {
def main(args: Array[String]): Unit = {
val spark: SparkSession= SparkSession.builder().master("local[*]").appName("graphx01").getOrCreate()
val sc = spark.sparkContext
// Create an RDD for the vertices
val users: RDD[(VertexId, (String, String))] =
sc.parallelize(Seq((3L, ("rxin", "student")), (7L, ("jgonzal", "postdoc")),
(5L, ("franklin", "prof")), (2L, ("istoica", "prof"))))
// Create an RDD for edges
val relationships: RDD[Edge[String]] =
sc.parallelize(Seq(Edge(3L, 7L, "collab"), Edge(5L, 3L, "advisor"),
Edge(2L, 5L, "colleague"), Edge(5L, 7L, "pi")))
// Define a default user in case there are relationship with missing user
val defaultUser = ("John Doe", "Missing")
// Build the initial Graph
val graph = Graph(users, relationships, defaultUser)
println("vertices..............")
graph.vertices.collect.foreach(println)
println("edges...............")
graph.edges.collect.foreach(println)
println("triplets............")
graph.triplets.collect.foreach(println)
}
}
执行效果:
vertices..............
(2,(istoica,prof))
(3,(rxin,student))
(5,(franklin,prof))
(7,(jgonzal,postdoc))
edges...............
Edge(3,7,collab)
Edge(5,3,advisor)
Edge(2,5,colleague)
Edge(5,7,pi)
triplets............
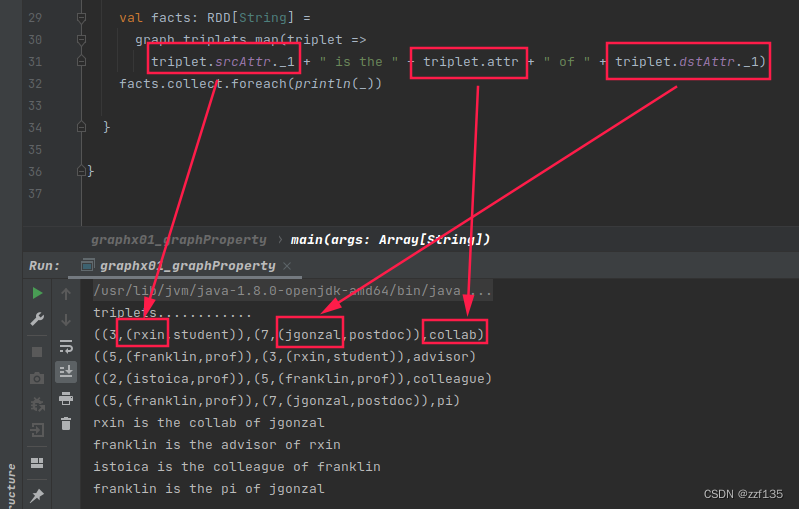
((3,(rxin,student)),(7,(jgonzal,postdoc)),collab)
((5,(franklin,prof)),(3,(rxin,student)),advisor)
((2,(istoica,prof)),(5,(franklin,prof)),colleague)
((5,(franklin,prof)),(7,(jgonzal,postdoc)),pi)
边过滤,点过滤
println("vertices filter...........")
graph.vertices.filter { case (id, (name, pos)) => pos == "postdoc" }.collect.foreach(println)
println(graph.vertices.filter { case (id, (name, pos)) => pos == "postdoc" }.count)
println("edge filter...........")
graph.edges.filter(e => e.srcId > e.dstId).collect.foreach(println)
println(graph.edges.filter(e => e.srcId > e.dstId).count)
运行效果
vertices filter...........
(7,(jgonzal,postdoc))
1
edge filter...........
Edge(5,3,advisor)
1
三元组属性值
val facts: RDD[String] =
graph.triplets.map(triplet =>
triplet.srcAttr._1 + " is the " + triplet.attr + " of " + triplet.dstAttr._1)
facts.collect.foreach(println(_))
运行效果
出度入度
println("numedges: "+ graph.numEdges)
println("numVertices: "+ graph.numVertices)
println("入度,按目标顶点id分组就和")
graph.inDegrees.collect.foreach(println)
println("出度,按源顶点id分组就和")
graph.outDegrees.collect.foreach(println)
println("出度入度合并")
graph.degrees.collect.foreach(println)
运行效果
numedges: 4
numVertices: 4
入度,按目标顶点id分组就和
(3,1)
(5,1)
(7,2)
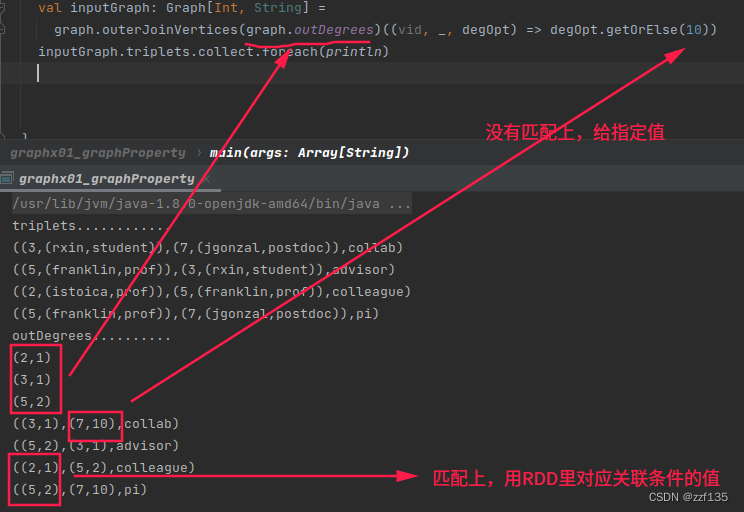
出度,按源顶点id分组就和
(2,1)
(3,1)
(5,2)
度数,顶点id分组就和
(2,1)
(3,2)
(5,3)
(7,2)
outerjoinvertices
顶点属性有多个时,用元组表示,按照元组索引来取值
val inputGraph: Graph[Int, String] =
graph.outerJoinVertices(graph.outDegrees)((vid, _, degOpt) => degOpt.getOrElse(10))
inputGraph.triplets.collect.foreach(println)
// 等价
val inputGraph: Graph[Int, String] =
graph.outerJoinVertices(graph.outDegrees)((vid, _, degOpt) =>
degOpt match {
case Some(opt) => opt
case None => 10
}
)
// 加入其他的判断条件
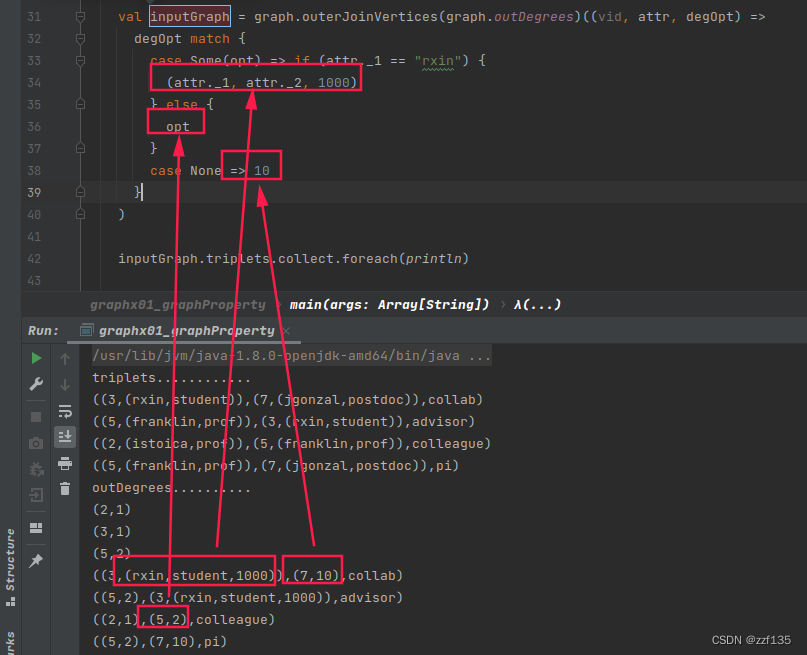
val inputGraph: Graph[Int, String] =
graph.outerJoinVertices(graph.outDegrees)((vid, attr, degOpt) =>
degOpt match {
case Some(opt) => if (attr._1 == "rxin") {
1000
}else {
opt
}
case None => 10
}
)
// 给定点新增属性
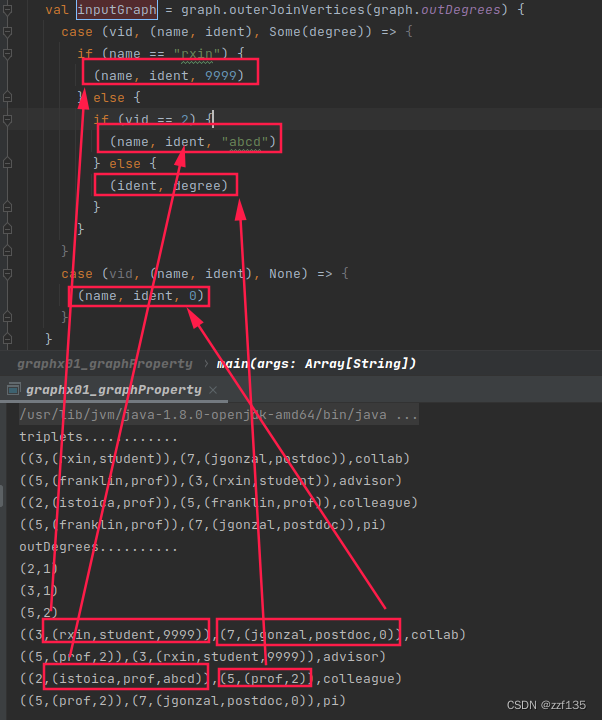
val inputGraph = graph.outerJoinVertices(graph.outDegrees) {
case (vid, (name, ident), Some(degree)) => (name, ident, degree)
case (vid, (name, ident), None) => (name, ident, 0)
}
运行效果:
subgraph
package zzf
import org.apache.spark.graphx._
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object graphx01_graphProperty {
def main(args: Array[String]): Unit = {
val spark: SparkSession= SparkSession.builder().master("local[*]").appName("graphx01").getOrCreate()
val sc = spark.sparkContext
val users: RDD[(VertexId, (String, String))] =
sc.parallelize(Seq((3L, ("rxin", "student")), (7L, ("jgonzal", "postdoc")),
(5L, ("franklin", "prof")), (2L, ("istoica", "prof")),
(4L, ("peter", "student"))))
// Create an RDD for edges
val relationships: RDD[Edge[String]] =
sc.parallelize(Seq(Edge(3L, 7L, "collab"), Edge(5L, 3L, "advisor"),
Edge(2L, 5L, "colleague"), Edge(5L, 7L, "pi"),
Edge(4L, 0L, "student"), Edge(5L, 0L, "colleague")))
// Define a default user in case there are relationship with missing user
val defaultUser = ("John Doe", "Missing")
// Build the initial Graph
val graph = Graph(users, relationships, defaultUser)
// Notice that there is a user 0 (for which we have no information) connected to users
// 4 (peter) and 5 (franklin).
graph.triplets.collect.foreach(println(_))
println("=================")
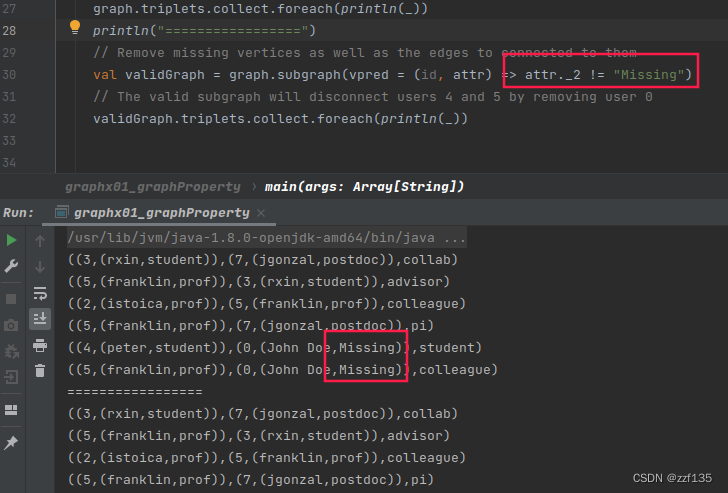
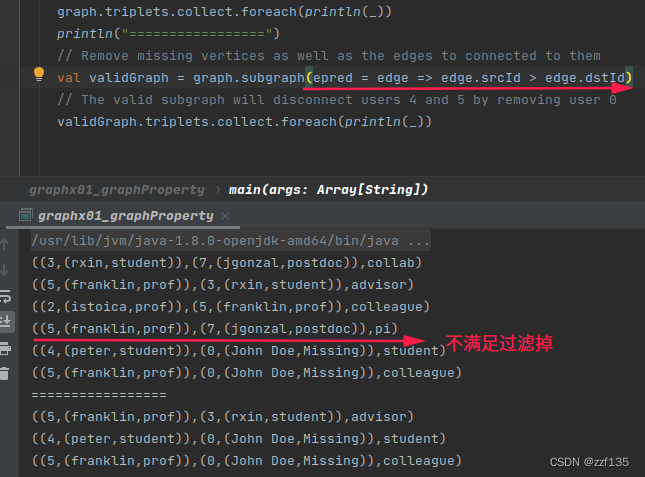
// Remove missing vertices as well as the edges to connected to them
val validGraph = graph.subgraph(vpred = (id, attr) => attr._2 != "Missing")
// The valid subgraph will disconnect users 4 and 5 by removing user 0
validGraph.triplets.collect.foreach(println(_))
}
}
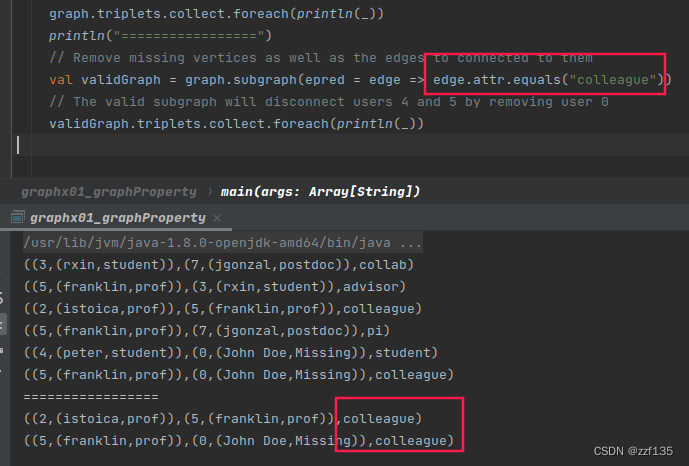
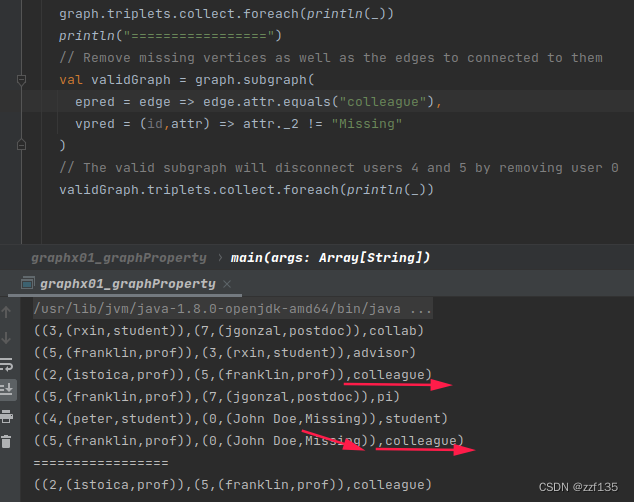
同时过滤点和边
连通图
package zzf
import org.apache.spark.graphx._
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object graphx01_graphProperty {
def main(args: Array[String]): Unit = {
val spark: SparkSession= SparkSession.builder().master("local[*]").appName("graphx01").getOrCreate()
val sc = spark.sparkContext
val users: RDD[(VertexId, (String, String))] =
sc.parallelize(Seq((3L, ("rxin", "student")), (7L, ("jgonzal", "postdoc")),
(5L, ("franklin", "prof")), (2L, ("istoica", "prof")),(10L, ("istoica10", "prof10")),(11L, ("istoica11", "prof11")),
(4L, ("peter", "student"))))
// Create an RDD for edges
val relationships: RDD[Edge[String]] =
sc.parallelize(Seq(Edge(3L, 7L, "collab"), Edge(5L, 3L, "advisor"),
Edge(2L, 5L, "colleague"), Edge(5L, 7L, "pi"),Edge(10L, 11L, "pi11"),
Edge(4L, 0L, "student"), Edge(5L, 0L, "colleague")))
// Define a default user in case there are relationship with missing user
val defaultUser = ("John Doe", "Missing")
// Build the initial Graph
val graph = Graph(users, relationships, defaultUser)
println("graph...........")
graph.triplets.collect.foreach(println)
// Notice that there is a user 0 (for which we have no information) connected to users
// 4 (peter) and 5 (franklin).
// Run Connected Components
val ccGraph = graph.connectedComponents() // No longer contains missing field
println("ccGraph..............")
ccGraph.triplets.collect.foreach(println)
// Remove missing vertices as well as the edges to connected to them
val validGraph = graph.subgraph(vpred = (id, attr) => attr._2 != "Missing")
// Restrict the answer to the valid subgraph
val validCCGraph = ccGraph.mask(validGraph)
}
}
运行结果:
((5,(franklin,prof)),(3,(rxin,student)),advisor)
((2,(istoica,prof)),(5,(franklin,prof)),colleague)
((5,(franklin,prof)),(7,(jgonzal,postdoc)),pi)
((10,(istoica10,prof10)),(11,(istoica11,prof11)),pi11)
((4,(peter,student)),(0,(John Doe,Missing)),student)
((5,(franklin,prof)),(0,(John Doe,Missing)),colleague)
ccGraph..............
((3,0),(7,0),collab)
((5,0),(3,0),advisor)
((2,0),(5,0),colleague)
((5,0),(7,0),pi)
((10,10),(11,10),pi11)
((4,0),(0,0),student)
((5,0),(0,0),colleague)
Graphx用图中顶点的id来标识节点所属的连通体,同一个连通体的编号是采用该联通体中最小的节点id来标识的。
aggregateMessages
用来对图中的顶点进行聚合计算,他会从每条边发出一条消息给变得源顶点和目标顶点,然后用一个函数来合并每个顶点收到的所有消息,最后返回一个新的VertexRDD,包含每个顶点的聚合结果。
入度
graph.aggregateMessages[Int](
_.sendToDst(1),
_+_
).collect().foreach(println)
运行效果
graph...........
((3,(rxin,student)),(7,(jgonzal,postdoc)),collab)
((5,(franklin,prof)),(3,(rxin,student)),advisor)
((2,(istoica,prof)),(5,(franklin,prof)),colleague)
((5,(franklin,prof)),(7,(jgonzal,postdoc)),pi)
((10,(istoica10,prof10)),(11,(istoica11,prof11)),pi11)
((4,(peter,student)),(0,(John Doe,Missing)),student)
((5,(franklin,prof)),(0,(John Doe,Missing)),colleague)
(0,2)
(11,1)
(3,1)
(5,1)
(7,2)
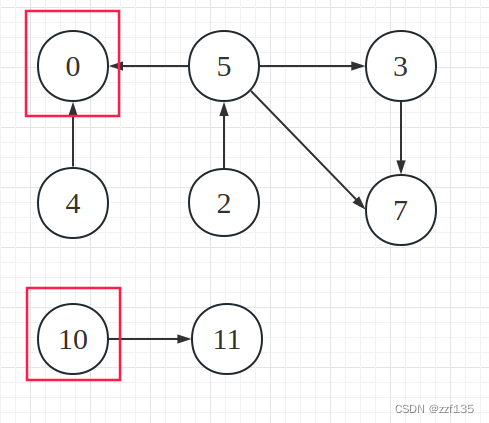
计算每个顶点相邻的点,相邻即可,忽略方向
graph.aggregateMessages[List[Long]](
triplet => {
triplet.sendToSrc(List(triplet.dstId))
triplet.sendToDst(List(triplet.srcId))
},
_++_
).collect().foreach(println)
运行效果
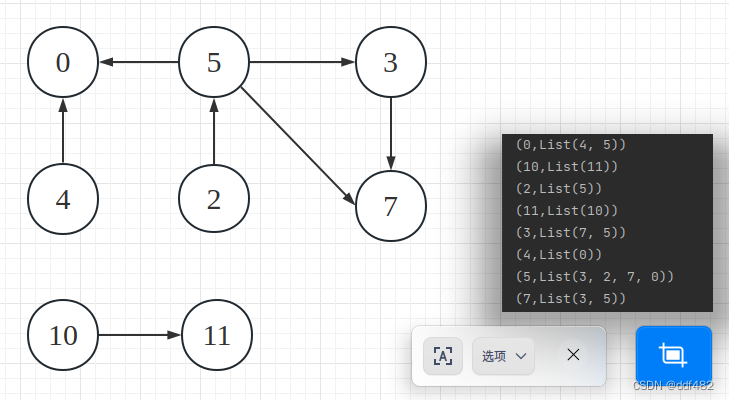
发送给源顶点
graph.aggregateMessages[List[Long]](
triplet => {
triplet.sendToSrc(List(triplet.dstId))
},
_++_
).collect().foreach(println)
运行效果:
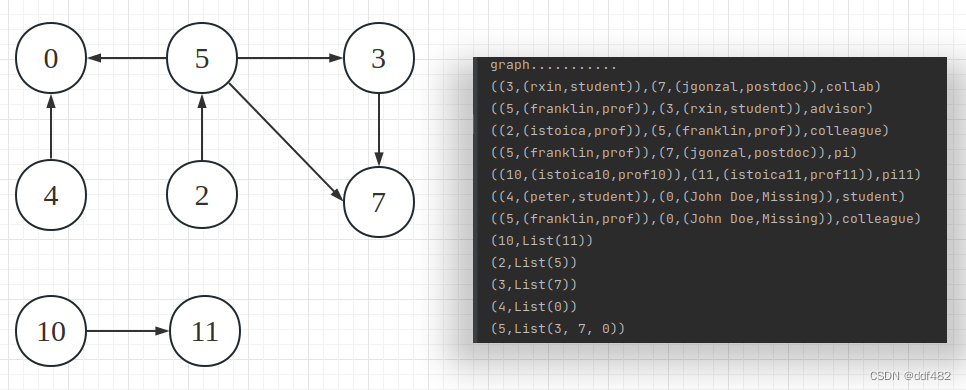
发送目标顶点的属性值给源顶点
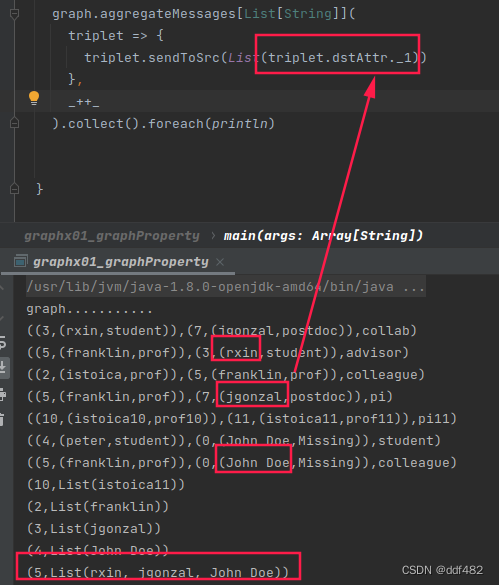















 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









