







/*
*Copyright (c) 2015 , 烟台大学计算机学院
*All right resvered .
*文件名称: 图的自建算法库.cpp
*作 者: 郑兆涵
*图——自建算法库
*/问题:定义图的临街矩阵和临街表存储结构,实现其基本运算,并完成测试,包含:①头文件:graph.h,包含定义图数据结构的代码、宏定义、要实现算法的函数的声明②源文件:graph.cpp,包含实现各种算法的函数的定义
编程代码:
//头文件:graph.h,包含定义图数据结构的代码、宏定义、要实现算法的函数的声明
#ifndef GRAPH_H_INCLUDED
#define GRAPH_H_INCLUDED
#define MAXV 100 //最大顶点个数
#define INF 32767 //INF表示∞
typedef int InfoType;
//以下定义邻接矩阵类型
typedef struct
{
int no; //顶点编号
InfoType info; //顶点其他信息,在此存放带权图权值
} VertexType; //顶点类型
typedef struct //图的定义
{
int edges[MAXV][MAXV]; //邻接矩阵
int n,e; //顶点数,弧数
VertexType vexs[MAXV]; //存放顶点信息
} MGraph; //图的邻接矩阵类型
//以下定义邻接表类型
typedef struct ANode //弧的结点结构类型
{
int adjvex; //该弧的终点位置
struct ANode *nextarc; //指向下一条弧的指针
InfoType info; //该弧的相关信息,这里用于存放权值
} ArcNode;
typedef int Vertex;
typedef struct Vnode //邻接表头结点的类型
{
Vertex data; //顶点信息
int count; //存放顶点入度,只在拓扑排序中用
ArcNode *firstarc; //指向第一条弧
} VNode;
typedef VNode AdjList[MAXV]; //AdjList是邻接表类型
typedef struct
{
AdjList adjlist; //邻接表
int n,e; //图中顶点数n和边数e
} ALGraph; //图的邻接表类型
//功能:由一个反映图中顶点邻接关系的二维数组,构造出用邻接矩阵存储的图
//参数:Arr - 数组名,由于形式参数为二维数组时必须给出每行的元素个数,在此将参数Arr声明为一维数组名(指向int的指针)
// n - 矩阵的阶数
// g - 要构造出来的邻接矩阵数据结构
void ArrayToMat(int *Arr, int n, MGraph &g); //用普通数组构造图的邻接矩阵
void ArrayToList(int *Arr, int n, ALGraph *&); //用普通数组构造图的邻接表
void MatToList(MGraph g,ALGraph *&G);//将邻接矩阵g转换成邻接表G
void ListToMat(ALGraph *G,MGraph &g);//将邻接表G转换成邻接矩阵g
void DispMat(MGraph g);//输出邻接矩阵g
void DispAdj(ALGraph *G);//输出邻接表G
#endif // GRAPH_H_INCLUDED
//源文件:graph.cpp,包含实现各种算法的函数的定义
#include <stdio.h>
#include <malloc.h>
#include "graph.h"
//功能:由一个反映图中顶点邻接关系的二维数组,构造出用邻接矩阵存储的图
//参数:Arr - 数组名,由于形式参数为二维数组时必须给出每行的元素个数,在此将参数Arr声明为一维数组名(指向int的指针)
// n - 矩阵的阶数
// g - 要构造出来的邻接矩阵数据结构
void ArrayToMat(int *Arr, int n, MGraph &g)
{
int i,j,count=0; //count用于统计边数,即矩阵中非0元素个数
g.n=n;
for (i=0; i<g.n; i++)
for (j=0; j<g.n; j++)
{
g.edges[i][j]=Arr[i*n+j]; //将Arr看作n×n的二维数组,Arr[i*n+j]即是Arr[i][j],计算存储位置的功夫在此应用
if(g.edges[i][j]!=0)
count++;
}
g.e=count;
}
void ArrayToList(int *Arr, int n, ALGraph *&G)
{
int i,j,count=0; //count用于统计边数,即矩阵中非0元素个数
ArcNode *p;
G=(ALGraph *)malloc(sizeof(ALGraph));
G->n=n;
for (i=0; i<n; i++) //给邻接表中所有头节点的指针域置初值
G->adjlist[i].firstarc=NULL;
for (i=0; i<n; i++) //检查邻接矩阵中每个元素
for (j=n-1; j>=0; j--)
if (Arr[i*n+j]!=0) //存在一条边,将Arr看作n×n的二维数组,Arr[i*n+j]即是Arr[i][j]
{
p=(ArcNode *)malloc(sizeof(ArcNode)); //创建一个节点*p
p->adjvex=j;
p->info=Arr[i*n+j];
p->nextarc=G->adjlist[i].firstarc; //采用头插法插入*p
G->adjlist[i].firstarc=p;
}
G->e=count;
}
void MatToList(MGraph g, ALGraph *&G)
//将邻接矩阵g转换成邻接表G
{
int i,j;
ArcNode *p;
G=(ALGraph *)malloc(sizeof(ALGraph));
for (i=0; i<g.n; i++) //给邻接表中所有头节点的指针域置初值
G->adjlist[i].firstarc=NULL;
for (i=0; i<g.n; i++) //检查邻接矩阵中每个元素
for (j=g.n-1; j>=0; j--)
if (g.edges[i][j]!=0) //存在一条边
{
p=(ArcNode *)malloc(sizeof(ArcNode)); //创建一个节点*p
p->adjvex=j;
p->info=g.edges[i][j];
p->nextarc=G->adjlist[i].firstarc; //采用头插法插入*p
G->adjlist[i].firstarc=p;
}
G->n=g.n;
G->e=g.e;
}
void ListToMat(ALGraph *G,MGraph &g)
//将邻接表G转换成邻接矩阵g
{
int i,j;
ArcNode *p;
g.n=G->n; //根据一楼同学“举报”改的。g.n未赋值,下面的初始化不起作用
g.e=G->e;
for (i=0; i<g.n; i++) //先初始化邻接矩阵
for (j=0; j<g.n; j++)
g.edges[i][j]=0;
for (i=0; i<G->n; i++) //根据邻接表,为邻接矩阵赋值
{
p=G->adjlist[i].firstarc;
while (p!=NULL)
{
g.edges[i][p->adjvex]=p->info;
p=p->nextarc;
}
}
}
void DispMat(MGraph g)
//输出邻接矩阵g
{
int i,j;
for (i=0; i<g.n; i++)
{
for (j=0; j<g.n; j++)
if (g.edges[i][j]==INF)
printf("%3s","∞");
else
printf("%3d",g.edges[i][j]);
printf("\n");
}
}
void DispAdj(ALGraph *G)
//输出邻接表G
{
int i;
ArcNode *p;
for (i=0; i<G->n; i++)
{
p=G->adjlist[i].firstarc;
printf("%3d: ",i);
while (p!=NULL)
{
printf("-->%d/%d ",p->adjvex,p->info);
p=p->nextarc;
}
printf("\n");
}
}
//编制main函数,完成相关的测试工作
#include <stdio.h>
#include <malloc.h>
#include "graph.h"
int main()
{
MGraph g1,g2;
ALGraph *G1,*G2;
int A[6][6]=
{
{0,5,0,7,0,0},
{0,0,4,0,0,0},
{8,0,0,0,0,9},
{0,0,5,0,0,6},
{0,0,0,5,0,0},
{3,0,0,0,1,0}
};
ArrayToMat(A[0], 6, g1); //取二维数组的起始地址作实参,用A[0],因其实质为一维数组地址,与形参匹配
printf(" 有向图g1的邻接矩阵:\n");
DispMat(g1);
ArrayToList(A[0], 6, G1);
printf(" 有向图G1的邻接表:\n");
DispAdj(G1);
MatToList(g1,G2);
printf(" 图g1的邻接矩阵转换成邻接表G2:\n");
DispAdj(G2);
ListToMat(G1,g2);
printf(" 图G1的邻接表转换成邻接邻阵g2:\n");
DispMat(g2);
printf("\n");
return 0;输出结果:
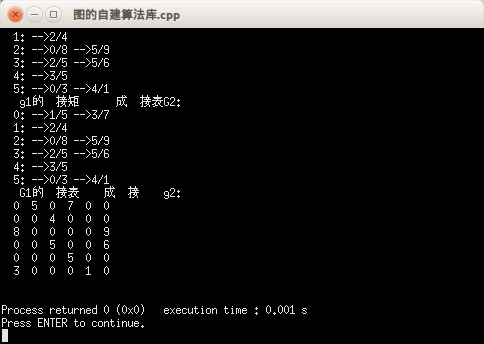
对于邻接矩阵的特点如下:
(1)图的邻接矩阵表示是唯一的。
(2)对于含有n个顶点的图,采用邻接矩阵存储时,无论是有向图还是无向图,也无论边的数目是多少,其存储空间均为O(n²),所以邻接矩阵适合于存储边的数目较多的稠密图。
(3)无向图的邻接矩阵一定是一个对称矩阵。因此,可以采用压缩存储的思想,在具体存放临街矩阵时只需要存放上三角或下三角的元素即可。
(4)对于无向图,邻接矩阵的第i行的非零元素的个数正好是顶点i的度。
(5)对于有向图,邻接矩阵的第i行的非零元素的个数正好是顶点i的入度或出度。
(6)用邻接矩阵方法存储图,很容易确定图中任意两个顶点之间是否有边相连。但是,要确定图中有多少条边,则必须按行、按列队每个元素进行检测,所花费的时间代价很大,这是用邻接矩阵存储图的局限性。
对于邻接表的特点如下:
(1)邻接表表示不唯一。这是因为在每个顶点对应的单链表中,各边节点的链接次序可以是任意的,取决于建立邻接表的算法以及边的输入次序。
(2)对于有n各顶点和e条边的无向图,其邻接表有n个表头节点和2e各边节点;对于有n个顶点和e条边的有向图,其邻接表有n个表头节点和e个边节点。显然,对于边数目较少的稀疏图,邻接表比邻接矩阵节省空间。
(3)对于无向图,邻接表的顶点i(0<=i<=n-1)对应的i号链表的边节点数目正好是顶点i的度。
(4)对于有向图,邻接表的顶点i(0<=i<=n-1)对应的i号链表的边节点数目仅仅是顶点i的出度。顶点i的入度为邻接表中所有adjvex域值为i的边节点数目。
代码分析:
(1)
typedef struct //图的定义
{
int edges[MAXV][MAXV]; //邻接矩阵
int n,e; //顶点数,弧数
VertexType vexs[MAXV]; //存放顶点信息
} MGraph; 定义一个结构体变量MGraph,并给此结构体分配一段空间,这样就可以将一个图中的信息全部存储进去,定义int顶点的个数n和边的个数e,还需要定义声名int一个二维数组来保存邻接矩阵,这时定义的edges[MAXV][MAXV]也就是在头文件中所声明的 #define MAXV,也就是最大顶点的个数,而在定义之后,就相当于有了这样一个邻接矩阵edge,此时也分配好空间,则可以存入邻接矩阵的每个单元格的元素,而无穷大,则用#define LIMITLESS 9999。一切定义后,还需要定义一个可以存放顶点信息的结构体VertexType,也成为顶点的类型,则里面存储了顶点的编号和其他信息,因为每个顶点具有一定的含义,需要存储起来。
(2)
<p>typedef struct ANode //弧的结点结构类型
{
int adjvex; //该弧的终点位置
struct ANode *nextarc; //指向下一条弧的指针
InfoType info; //该弧的相关信息,这里用于存放权值
} ArcNode;
typedef int Vertex;</p><p>typedef struct Vnode //邻接表头结点的类型
{
Vertex data; //顶点信息
int count; //存放顶点入度,只在拓扑排序中用
ArcNode *firstarc; //指向第一条弧
} VNode;
typedef VNode AdjList[MAXV]; //AdjList是邻接表类型</p><p>typedef struct
{
AdjList adjlist; //邻接表
int n,e; //图中顶点数n和边数e
} ALGraph; //图的邻接表类型</p>定义结构体ALGraph邻接表,与定义邻接矩阵的方法类似,需要定义邻接表的顶点数目,也就相当于定义多个单链表的表头数目,以及边数,再需要定义一个数组adjlist,这个数组也就形成了一个表头结点的顺序表,用来存放表头结点的顺序及各个信息。而所定义的AdjList[MAXV]中存储的表头节点的类型是Vnode类型的,再分析Vnode则需要定义各顶点的信息,vertex定义一个data数据,还需要给出一个指向节点的边的链接,也就是*firstarc,这个指针指向边节点ArcNode。再需要定义一个结构体ArcNode,这里面也需要定义一个点adjvex,它所对应的就是边表节点中的编号,还需要定义指向下一个节点的指针*nextarc,再定义一个保存值的info即可。
(3)
void MatToList(MGraph g, ALGraph *&G)
//将邻接矩阵g转换成邻接表G
{
int i,j;
ArcNode *p;
G=(ALGraph *)malloc(sizeof(ALGraph));
for (i=0; i<g.n; i++) //给邻接表中所有头节点的指针域置初值
G->adjlist[i].firstarc=NULL;
for (i=0; i<g.n; i++) //检查邻接矩阵中每个元素
for (j=g.n-1; j>=0; j--)
if (g.edges[i][j]!=0) //存在一条边
{
p=(ArcNode *)malloc(sizeof(ArcNode)); //创建一个节点*p
p->adjvex=j;
p->info=g.edges[i][j];
p->nextarc=G->adjlist[i].firstarc; //采用头插法插入*p
G->adjlist[i].firstarc=p;
}
G->n=g.n;
G->e=g.e;
}定义一个G所对应的存储空间,并且给它分配存储空间,通过一个for循环,对所有的指针域赋初值,则G所指向的adjlist[i].firstarc这个域,将它赋值为NULL,赋值NULL可以防止在邻接矩阵中有一些是孤立点,没有下一个指针域。接下来根据邻接矩阵建立邻接表节点,通过两重循环,一重由0到n,二重由0
到n-1,可以将邻接矩阵中的每一个元素都取出来,接下来判断g.edges[i][j]是否为0,若为0,则进行头插法,也就是之前所学过的头插法,在单链表中插入数据的方法,进行插入节点即可,若不为0,则不需要做任何处理。















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









