







7.1 汉语自动分词中的基本问题
主要困难:分词规范,歧义切分,未登录词的识别
7.1.1 分词规范问题
总结来说,就是每个人的认识不一样,会导致分词规范不同
1992 年国家标准局颁布了作为国家标准的《信息处理用现代汉语分词规范》刘源等,1994;刘开瑛,2000]。在这个规范中,大部分规定都是通过举例和定性描述来体现的例如,规范 4.2规定:“二字或三字词,以及结合紧密使用稳定的二字或三字词组,一律为分词单位。”那么,何谓“紧密”,何谓“稳定”,人们在实际操作中都很难界定。在规范4.3,4.4,5.1.1.1,5.1.1.2,5.24,5.2.5,5.2.6等很多规定中都对分词单位有“结合紧密、使用稳定”的要求。这种规定的操作尺度很难把握,极易受主观因素的影响。因而使得《规范》并没有从根本上统一国人对汉语词的认识,哪怕只是在信息处理界。在这种情况下,建立公平公开的自动分词评测标准的努力也一样步履维艰[黄昌宁等,20037。
7.1.2 歧义切分
歧义:
- 交集型,偶发歧义。AJB,满足AJ、JB同时为词。如:大学生、研究生物、为人民工作、中国产品质量
- 组合型,固有歧义。AB,满足A、B、AB同时为词。如:起身、将来、现在、才能、学生会
汉语词语边界的歧义切分问题比较复杂,处理这类问题时往往需要进行复杂的上下文语义分析,甚至韵律分析,包括语气、重音、停顿等。
7.1.3 未登录词
未登录词又称为生词(unknown word),可以有两种解释:一是指已有的词表中没有收录的词;二是指已有的训练语料中未曾出现过的词。在第二种含义下,未登录词又称为集外词(out of vocabulary,OOV),即训练集以外的词。由于目前的汉语自动分词系统多采用基于大规模训练语料的统计方法,或者如果已有大规模训练语料(尤其是已做了人工分词标注的训练语料)便很容易获得词汇表,因此通常情况下将 OOV 与未登录词看作一回事。
但是,从汉语分词的角度而言,当我们看到这些发布的“新词语”之际,其中很多词语已经退出了历史舞台。因此,对于一个分词系统来说,如果不能实时获取和更新训练语料,并及时地调整系统参数(这个过程本身就涉及新词的界定问题),一旦这类词语出现在待切分文本中,其切分结果几乎可以肯定是错误的。不过从某种意义上讲,这类错误没有理由成为我们关注的重点,至少不应该是汉语分词系统研究的核心问题。
7.2 汉语分词
分为词表分词和HMM分词。
由于很多专著和论文已经对汉语自动分词方法作了详细介绍[刘源等,1994;梁南元,1987b;揭春雨,1989;朱巧明等,20057,尤其是基于词表的分词方法和传统的基于HMM和元语法的分词方法因此,我们不再详述这些方法。本节主要介绍几种性能较好的基于统计模型的分词方法,并对这些分词技术进行简要的比较。
两个主要问题:切分歧义消除、未登录词识别。
7.2.1 N-最短路径
大致思想:
考虑到汉语自动分词中存在切分歧义消除和未登录词识别两个主要问题,因此,有专家将分词过程分成两个阶段:首先采用切分算法对句子词语进行初步切分,得到一个相对最好的粗分结果,然后,再进行歧义排除和未登录词识别。
N-最短路径方法就是一种词语粗分模型,大致步骤:
- 1.根据词典,找出字串中所有可能的词,构造词语切分有向无环图。
- 2.每个词对应图中的一条有向边,并赋给相应的边长(权值) 。
- 3.然后针对该切分图,在起点到终点的所有路径中,求出长度值按严格升序排列(任何两个不同位置上的值一定不等)依次为第1、第2、…、第i、…、第N(N≥1)的路径集合作为相应的粗分结果集。
- 4.如果两条或两条以上路径长度相等,那么它们的长度并列第i,都要列入粗分结果集,而且不影响其他路径的排列序号,最后的粗分结果集合大小大于或等于N。
一个实例:句子:“他说的确实在理”
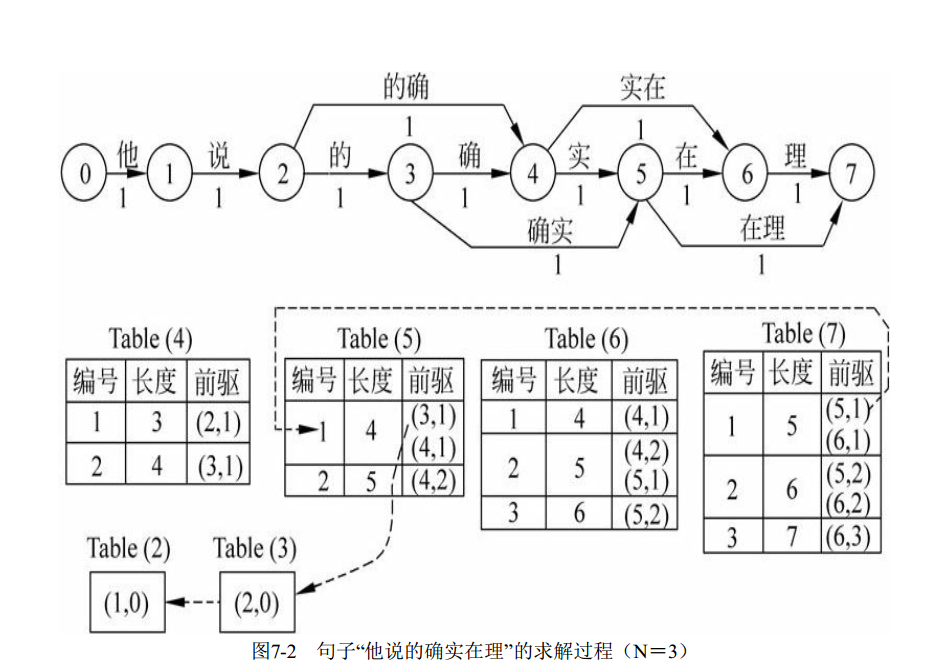
上面图中,Table(i)表示结点i的信息记录表,表里记录的是不同长度的路径的编号(不超过N),且从小到大排列。
前驱字段里的(i,j)表示沿当前路径到达当前结点的最后一条边的出发结点是i,这条边对应的是结点i的信息记录表中编号为j的路径。如果j=0,表示没有其他候选的路径。
如结点7对应的信息记录表Table(7)中编号为1的路径前驱(5,1)表示前一条边为结点5的信息表中第1条路径。
信息记录表为系统回溯找出所有可选路径提供了依据。
7.2.2 基于词的n元语法模型的分词方法
基于词的n元文法模型是一个典型的生成式模型,早期很多统计分词方法均以它为基本模型,然后配合其他未登录词识别模块进行扩展。其基本思想是:首先根据词典(可以是从训练语料中抽取出来的词典,也可以是外部词典)对句子进行简单匹配,找出所有可能的词典词,然后,将它们和所有单个字作为结点,构造的 n 元的切分词图,图中的结点表示可能的词候选,边表示路径,边上的 n 元概率表示代价,最后利用相关搜索算法(如Viterbi算法)从图中找到代价最小的路径作为最后的分词结果。
7.3 命名体识别
实体概念在文本中的引用(Entity Mention)有三种形式:
- 命名性指称。如,刘国梁
- 名词性指称。如,中国乒乓球队主教练
- 代词性指称。如,他
早期也是基于规则的,代价比较贵,后期就改为基于机器学习的了。
基于统计模型的NER方法有很多种:
- 有监督:HMM、n-gram、ME、SVM、CRF等
- 半监督:自举学习
- 无监督:利用词汇资源进行上下文聚类
- 混合型
7.3.2 基于CRF的命名体识别方式
类似汉语分词原理,把NER看成一个序列标注问题:
- 分词;
- 识别人名、简单地名、简单组织名;
- 识别复合地名、符合组织名。
有监督学习,需要已标注的大规模语料,常用 北京大学计算语言学研究所 标注的现代汉语多级加工语料库。
步骤:标注语料 -> 产生特征 -> 训练模型 (比一般ML过程多一步标注语料)
7.5 词性标注
词性(part-of-speech)是词汇基本的语法属性,通常也称为词类。词性标注就是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程。词性标注是自然语言处理中一项非常重要的基础性工作。
主要困难:
(1)汉语是一种缺乏词形态变化的语言,词的类别不能像印欧语那样,直接从词的形态变化上来判别。
(2) 常用词兼类现象严重。
(3)研究者的主观因素
7.7 关于技术测评
(1)汉语是一种缺乏词形态变化的语言,词的类别不能像印欧语那样,直接从词的形态变化上来判别。
(2) 常用词兼类现象严重。
(3)研究者的主观因素
7.7 关于技术测评
分词、NER(命名体识别)、词性标注,这三者是中文信息处理的基础性关键技术。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









