







Actions ~ Transformations
最近看行为识别论文,发现这篇论文一直都没有看过,但是引用也不少,所以抽出一个上午把这篇论文通读了一遍。
这篇文章通过变换矩阵学习各种类别的行为的变化,即使用一个线性系统保存一种行为类别的动态变化,感觉想法是挺有意思的,目前我正想着能否将其应用于序列合成的问题。
网络结构
正如前言所说,文章使用一个线性系统来描述一类行为高层视觉信息的动态变化,为了更好地描述,需要先定义几个概念:
- precondition state:这个描述的是行为动作发生之前的状态,比如踢球行为,奔跑抬脚都可以认为是precondition state。
- effect state:这个描述的是行为动作发生之后的状态,比如踢球行为,球飞了可以认为是effect state。
文章就是用一个线性系统学习从precondition state的embedding latent representation 到 effect state 的 embedding latent representation的变换。
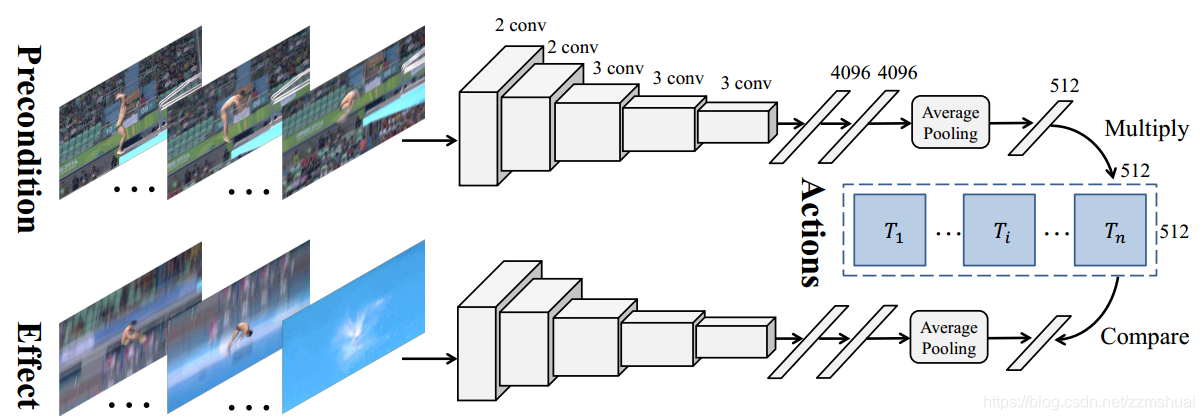
具体的网络结构如上图所示,上图的整个逻辑如下图所示:
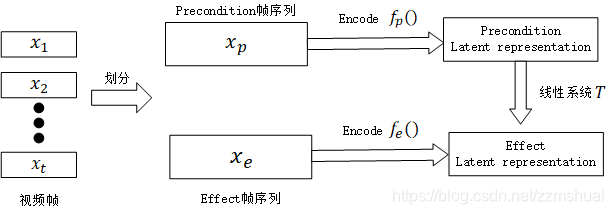
对于输入的一段视频帧
X
=
{
x
1
,
x
2
,
.
.
.
,
x
t
}
X=\left \{ x_{1}, x_{2},...,x_{t} \right \}
X={x1,x2,...,xt},我们首先将其分为 precondition 帧序列
X
p
=
{
x
1
,
.
.
.
,
x
z
p
}
X_{p}=\left \{ x_{1}, ...,x_{z_{p}} \right \}
Xp={x1,...,xzp} 和 effect 帧序列
X
e
=
{
x
z
e
,
.
.
.
,
x
t
}
X_{e}=\left \{ x_{z_{e}}, ...,x_{t} \right \}
Xe={xze,...,xt},然后对于两种帧序列,我们分别使用编码函数
f
p
f_{p}
fp和
f
e
f_{e}
fe对其进行编码,得到 precondition state的embedding latent represetation
f
p
(
X
p
)
f_{p}\left ( X_{p} \right )
fp(Xp) 和 effect state的embedding latent represetation
f
e
(
X
e
)
f_{e}\left ( X_{e} \right )
fe(Xe),对于一个线性系统,我们使用
T
i
T_{i}
Ti来表示,其中
i
i
i表示第
i
i
i类的线性变换系统,我们希望能够实现
f
e
(
X
e
)
=
T
i
f
p
(
X
p
)
f_{e}\left ( X_{e} \right )=T_{i}f_{p}\left ( X_{p} \right )
fe(Xe)=Tifp(Xp)。
上述便是文章的主要的核心思想。
在网络实现的过程之中,
f
p
f_{p}
fp和
f
e
f_{e}
fe使用的是Siamese network,但是Siamese network的两个流并不共享参数,每一个流都是一个VGG网络,但是网络沿着时间维度是共享参数的,所有帧经过VGG网络得到全连接特征后经过一个时间平均池化函数对时间维度进行压缩,得到最终的
f
p
(
X
p
)
f_{p}\left ( X_{p} \right )
fp(Xp)和
f
e
(
X
e
)
f_{e}\left ( X_{e} \right )
fe(Xe)。
训练阶段
我们可以看到整个网络的参数主要有两个部分组成:
- precondition 帧的时间范围和 effect帧的时间范围 z p z_{p} zp和 z e z_{e} ze
- 网络的参数
所以直接使用梯度反向传播是不合适的,文章借鉴了EM算法的 两步迭代优化策略。
-
即首先训练 z p z_{p} zp和 z e z_{e} ze,其优化目标为
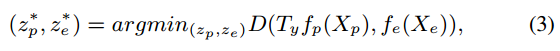
可以解释为希望latent representation的类内距离越小越好,在寻找最优的 z p z_{p} zp和 z e z_{e} ze时,使用的是穷举的方式。 -
然后优化网络参数,优化网络参数时希望线性变换后的两个latent represent 类内距离越小越好,类间距离越大越好,所以优化目标为(1)和(2)
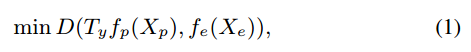
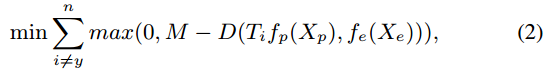
其中M表示margin,也就是距离超过margin就不计入损失,和svm的损失有点像。
整个训练的过程如下表所示:

实验
embedding latent representation实验
文章首先探索了使用本文方法训练的embedding latent representation和使用双流网络训练的embedding latent representation 之间有哪些不同。文章首先随机地选择一个样本,计算其embedding latent representation, 然后将其作为Query,去数据集里检索最相似的embedding latent representation,实验结果如下图所示,其中第一列是选定的样本,第二列是本文方法检索的视频帧,第三列是使用双流网络检索的视频帧。

从上图中可以看到,双流网络(简单的CNN)学习到的更多的是空间和时间的相似性的变化,而本文学习的更多的是运动行为的流形表示。
salient region实验

同时文章实验了将feature map反向传播回输入,观察focus region。可以看到,对于CNN在分类的时候可能会关注到背景环境之类的影响,但是本文主要关注的还是object的变化。
视频预测
这个实验还是非常地有意思地,输入preconditin的图片,给定变换矩阵,在所有帧里搜索最符合的effect图片。当给定的变换矩阵不同时,可以得到不同的 effect图片,然后使用插值的方法就可以生成完整的连续的视频,这个想法有点牛逼。














 934
934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









