









String.protatype.search(reg)
1.search()方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串
2.方法返回第一个匹配结果index,查找不到返回-1
3.search()方法不执行全局匹配,它将忽略标志g,并且总是从字符串的开始进行检索
下面请看例子:

1.传入的参数可以不是字符串
2.当传入的参数不是正则的时候,系统会尝试把参数转换成正则,如1->/1/
3.不执行全局匹配,忽略标志g,并且总是从字符串的开始进行检索。这一点大家可以从最后3条一样的指令看出
String.protatype.match(reg)
1.match()方法将检索字符串,以找到一或多个与regexp匹配的文本
2.regexp是否具有标志g对结果影响很大
我们来看一下没有g的时候,也就是非全局调用的时候
非全局调用
1.如果regexp没有标志g,那么match()方法就只能在字符串中执行一次匹配
2.如果没有找到任何匹配的文本,将返回null
3.否则它将返回一个数组,其中存放了与它找到的匹配文本有关的信息
那么它返回了什么了?我们以前回顾前面非全局调用的内容(与exec是相同的):
1.返回数组的第一个元素存放的是匹配文本,而其余的元素存放的是与正则表达式的子表达式匹配的文本
2.除了常规的数组元素之外,返回的数组还有2个对象属性
a. index声明匹配文本的起始字符在字符串的位置
b. input声明对stringObject的引用
非全局调用请看下图:
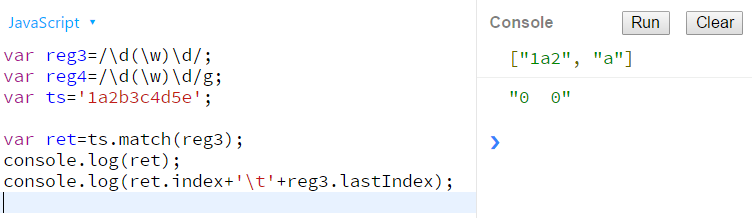
全局调用
1.如果regexp具有标志g则match()方法将执行全局检索,找到字符串中的所有匹配子字符串
a.没有找到任何匹配的子串,则返回null
b.如果找到了一个或多个匹配子串,则返回一个数组
2.数组元素中存放的是字符串中所有的匹配子串,而且也没有index属性或input属性
全局调用请看下图
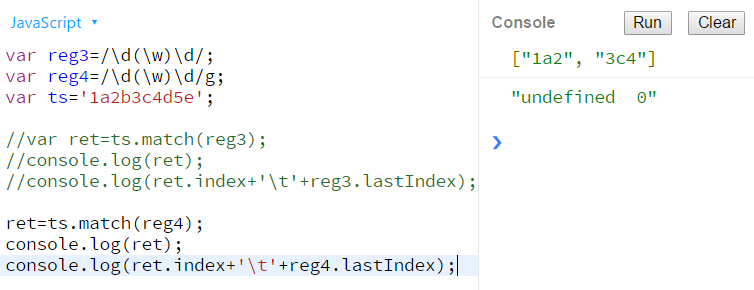
我们可以看到,match()方法返回的数组既没有匹配的分组信息,也没有相应的下标信息。只是单单的告诉你有几个匹配结果,如果我们只是想获得匹配内容的话,用match()效率会高一些。如果我们需要详细信息,则应该选择exec()方法。
String.prototype.split(reg)
1.我们经常使用split方法把字符串分割为字符数组
'a,b,c,d'.split(','); //["a","b","c","d"]
2.在一些复杂的分割情况我们可以使用正则表达式解决
'a1b2c3d'.split(/\d/); //["a","b","c","d"]
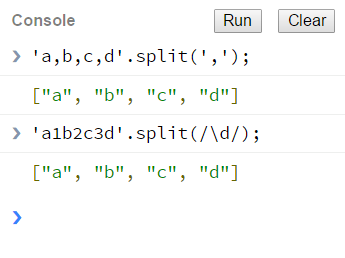
一般的分割我们用不到正则,但是当我们需要分割的字符串中既包含逗号(,)又包含竖线(|)的时候,正则表达式的方便就体现出来了
String.prototype.replace
这是最常用的正则函数之一,可以传入2个参数,一个参数用于查找,一个参数用于替换。
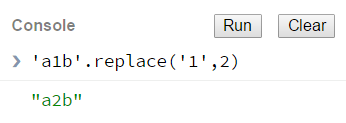
第一个例子:
第二个例子:
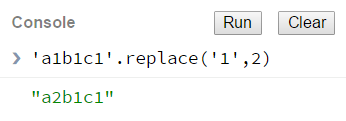
第二个例子很明显没有达到我们期望的效果,后面两个1没有被替换,它只匹配了第一个参数。那么如何才能实现我们要的效果呢?
看一下replace()方法接受哪些参数
String.prototype.replace(str,replaceStr)
String.prototype.replace(reg,replaceStr)
String.prototype.replace(reg,function)
所以我们可以传入正则表达式的参数,这个时候用正则会方便一点。

其实看到这里大家也应该猜到了,为什么第二个例子中只有第一个1被替换了?因为'1'被隐式转换成了/1/这种正则的写法。
但是当我们需要进行更精细的操作的时候,正则表达式作为参数就无能为力了,比如我们要将:a1b2c3 => a2b3c4 ,每一个数字加1
function参数含义
function会在每次匹配替换的时候调用,有四个参数(参数个数不固定)
1.匹配字符串
2.正则表达式分组内容,没有分组则没有该参数
3.匹配项在字符串中的index
4.原字符串
如果没有分组则只有3个参数,如果有1个分组则有4个参数,如果有2个分组则有5个参数。我们需要根据不同的正则表达式来写不同参数个数的函数,这种设计不太好
请看第一个例子:

搜索数字,第一个参数是匹配结果,第二个参数是当前匹配的位置,第三个参数是原字符串,因为这里没有分组,所以只有3个参数
请看第二个使用分组的例子:
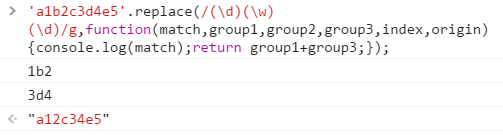
添加了分组参数,其他同第一个例子

















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









