







英文诗歌数据-绘制词云图+本文分类
本项目包含:
1.文本处理
2.词云图绘制
3.文本分类
往期文章可以关注我的专栏
下巴同学的数据加油小站
或者关注CSDN
会不定期分享数据挖掘、机器学习、风控模型、深度学习、NLP等方向的学习项目
数据和完整代码文末链接可以下载
一、导入数据、检查数据
import torch
from torch.utils.data import random_split
import pandas as pd
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
导入训练集
train_data = pd.read_csv('/home/mw/input/data6487/Poem_classification - train_data.csv')
train_data.head()
Genre Poem
0 Music NaN
1 Music In the thick brushthey spend the...
2 Music Storms are generous. ...
3 Music —After Ana Mendieta Did you carry around the ...
4 Music for Aja Sherrard at 20The portent may itself ...
检查训练集
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 841 entries, 0 to 840
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Genre 841 non-null object
1 Poem 837 non-null object
dtypes: object(2)
memory usage: 13.3+ KB
train_data = train_data.dropna()
train_data = train_data.reset_index(drop=True)
train_data
Genre Poem
0 Music In the thick brushthey spend the...
1 Music Storms are generous. ...
2 Music —After Ana Mendieta Did you carry around the ...
3 Music for Aja Sherrard at 20The portent may itself ...
4 Music for Bob Marley, Bavaria, November 1980 Here i...
... ... ...
832 Environment Why make so much of fragmentary blue In here a...
833 Environment Woman, I wish I didn't know your name. What co...
834 Environment Yonder to the kiosk, beside the creek, Paddle ...
835 Environment You come to fetch me from my work to-night Whe...
836 Environment You see them through water and glass, (both li...
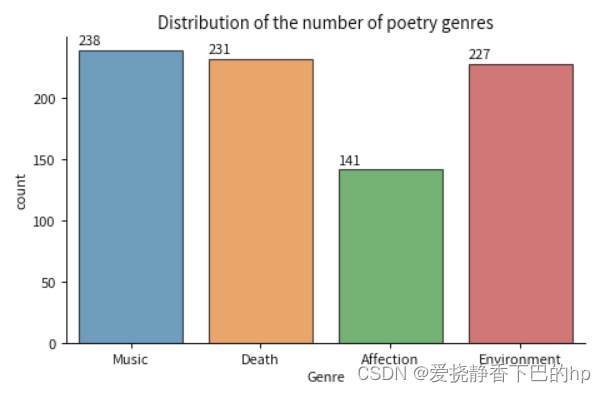
train_data['Genre'].value_counts()
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
fig,ax = plt.subplots(figsize=(6,4), dpi=80)
sns.countplot(x=train_data['Genre'], edgecolor="black", alpha=0.7, data=train_data)
sns.despine()
plt.title("Distribution of the number of poetry genres")
plt.tight_layout()
for p in ax.patches:
ax.annotate(f'\n{p.get_height()}', (p.get_x(), p.get_height()+5), color='black', size=10)
测试集部分省略,操作相同
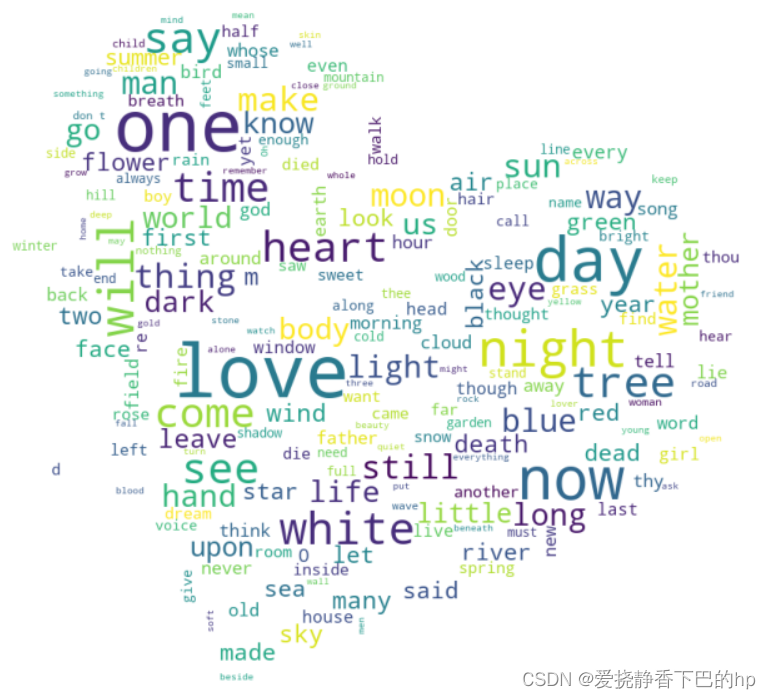
二、词云图
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
from PIL import Image
background_image = np.array(Image.open("/home/mw/project/p.jpg"))
fig,ax = plt.subplots(figsize=(12,8), dpi=100)
stopwords = STOPWORDS
stopwords.add('S')
mytext = ''
for i in range(len(test_data)):
mytext += test_data['Poem'][i]
for j in range(len(train_data)):
mytext += train_data['Poem'][j]
wcloud = WordCloud(width=2400, height=1600,background_color="white",stopwords=stopwords,mask = background_image).generate(mytext)
plt.imshow(wcloud)
plt.axis('off')
三、文本分类
处理文本
import re
def handle_data(data):
X = data['Poem']
y = data['Genre']
tv_data = []
label = []
for i in range(len(X)):
r = '[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~\n。!,—]+'
temp = X[i].replace('\n', '')
temp = re.sub(r, '', temp)
tv_data.append(temp)
if y[i] == 'Music':
label.append(0)
elif y[i] == 'Death':
label.append(1)
elif y[i] == 'Environment':
label.append(2)
elif y[i] == 'Affection':
label.append(3)
return tv_data,label
X_train,y_train = handle_data(train_data)
X_test,y_test = handle_data(test_data)
构建字典
word_list = " ".join(X_train+X_test).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
构建数据集
def transform(sentence, max_len=256):
"""
把句子转换为数字序列
:param sentence:
:param max_len: 句子的最大长度
:return:
"""
if len(sentence) > max_len:
# 句子太长时进行截断
sentence = sentence[:max_len]
else:
# 句子长度不够标准长度时,进行填充
sentence = sentence + [0] * (max_len - len(sentence))
# print(sentence)
return sentence
x_input = [np.asarray(transform([word_dict[n] for n in sen.split()])) for sen in X_train]
x_input_test = [np.asarray(transform([word_dict[n] for n in sen.split()])) for sen in X_test]
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
train_inputs = torch.LongTensor(x_input)
train_labels = torch.LongTensor([out for out in y_train])
test_inputs = torch.LongTensor(x_input_test)
test_labels = torch.LongTensor([out for out in y_test])
# 加载训练数据集
dataset = TensorDataset(train_inputs, train_labels)
train_size = int(len(dataset) * 0.8)
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset=dataset,lengths=[train_size,val_size],generator=torch.Generator().manual_seed(2022)) #分割验证和训练集
test_dataset = TensorDataset(test_inputs, test_labels)
# # 加载测试数据集
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True,drop_last=False)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=True,drop_last=False)
test_loader = DataLoader(test_dataset)
模型构建、编译、训练
class MyModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, num_filter,
filter_sizes, output_dim, dropout=0.5, pad_idx=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.convs = nn.ModuleList([
nn.Conv2d(in_channels=1, out_channels=num_filter,
kernel_size=(fs, embedding_dim))
for fs in filter_sizes
])
# in_channels:输入的channel,文字都是1
# out_channels:输出的channel维度
# fs:每次滑动窗口计算用到几个单词,相当于n-gram中的n
# for fs in filter_sizes用好几个卷积模型最后concate起来看效果。
self.fc = nn.Linear(len(filter_sizes) * num_filter, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
embedded = self.dropout(self.embedding(text)) # [batch size, sent len, emb dim]
embedded = embedded.unsqueeze(1) # [batch size, 1, sent len, emb dim]
# 升维是为了和nn.Conv2d的输入维度吻合,把channel列升维。
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
# conved = [batch size, num_filter, sent len - filter_sizes+1]
# 有几个filter_sizes就有几个conved
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved] # [batch,num_filter]
cat = self.dropout(torch.cat(pooled, dim=1))
# cat = [batch size, num_filter * len(filter_sizes)]
# 把 len(filter_sizes)个卷积模型concate起来传到全连接层。
return self.fc(cat)
vocab_size = len(word_dict) # 词典数量
dmodel = 128 # embedding层词向量
num_filter = 100 # 卷积核个数
filter_size = [2, 3, 4] # 卷积核的长
output_dim = 4 # 种类
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = torch.device("cpu")
model = MyModel(vocab_size+1, dmodel, num_filter=num_filter, filter_sizes=filter_size, output_dim=output_dim).to(device)
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for texts, target in dataloader:
texts, target = texts.to(device), target.to(device)
# 计算loss
target_pred = model(texts)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
learn_rate = 1e-2 # 初始学习率
lambda1 = lambda epoch: 0.96 ** (epoch // 5)
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)
import copy
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
epochs = 15
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0 # 设置一个最佳准确率,作为最佳模型的判别指标
for epoch in range(epochs):
# 更新学习率(使用自定义学习率时使用)
# adjust_learning_rate(optimizer, epoch, learn_rate)
model.train()
epoch_train_acc, epoch_train_loss = train(train_loader, model, loss_fn, optimizer)
scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)
model.eval()
epoch_test_acc, epoch_test_loss = test(val_loader, model, loss_fn)
# 保存最佳模型到 best_model
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Val_acc:{:.1f}%, Val_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
print('Done')
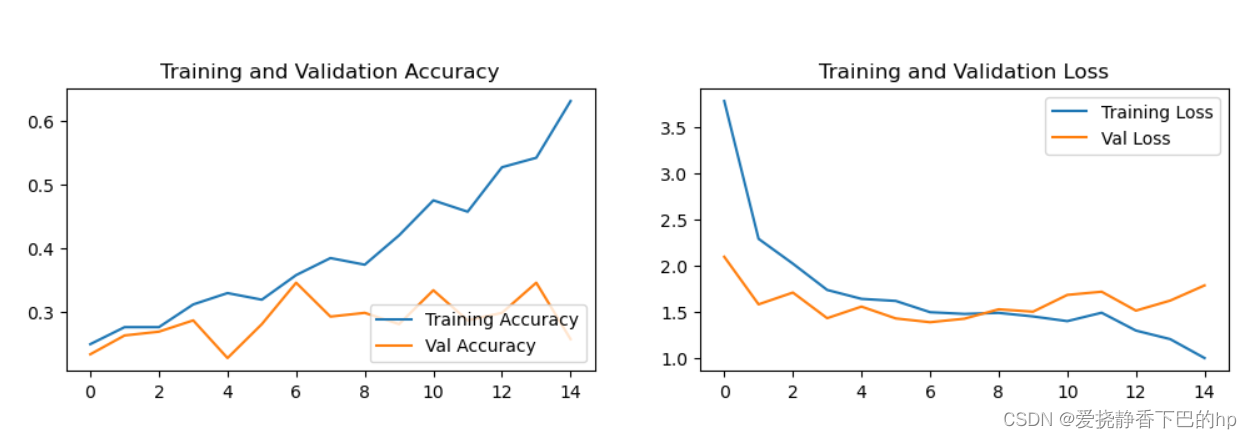
Epoch: 1, Train_acc:24.8%, Train_loss:3.782, Val_acc:23.2%, Val_loss:2.095, Lr:1.00E-02
Epoch: 2, Train_acc:27.5%, Train_loss:2.289, Val_acc:26.2%, Val_loss:1.579, Lr:1.00E-02
Epoch: 3, Train_acc:27.5%, Train_loss:2.020, Val_acc:26.8%, Val_loss:1.707, Lr:1.00E-02
Epoch: 4, Train_acc:31.1%, Train_loss:1.735, Val_acc:28.6%, Val_loss:1.429, Lr:1.00E-02
Epoch: 5, Train_acc:32.9%, Train_loss:1.639, Val_acc:22.6%, Val_loss:1.555, Lr:1.00E-02
Epoch: 6, Train_acc:31.8%, Train_loss:1.616, Val_acc:28.0%, Val_loss:1.427, Lr:1.00E-02
Epoch: 7, Train_acc:35.7%, Train_loss:1.494, Val_acc:34.5%, Val_loss:1.386, Lr:1.00E-02
Epoch: 8, Train_acc:38.4%, Train_loss:1.476, Val_acc:29.2%, Val_loss:1.424, Lr:1.00E-02
Epoch: 9, Train_acc:37.4%, Train_loss:1.487, Val_acc:29.8%, Val_loss:1.526, Lr:1.00E-02
Epoch:10, Train_acc:42.0%, Train_loss:1.448, Val_acc:28.0%, Val_loss:1.500, Lr:1.00E-02
Epoch:11, Train_acc:47.5%, Train_loss:1.397, Val_acc:33.3%, Val_loss:1.682, Lr:1.00E-02
Epoch:12, Train_acc:45.7%, Train_loss:1.489, Val_acc:28.6%, Val_loss:1.716, Lr:1.00E-02
Epoch:13, Train_acc:52.8%, Train_loss:1.295, Val_acc:29.8%, Val_loss:1.511, Lr:1.00E-02
Epoch:14, Train_acc:54.3%, Train_loss:1.202, Val_acc:34.5%, Val_loss:1.620, Lr:1.00E-02
Epoch:15, Train_acc:63.2%, Train_loss:0.997, Val_acc:25.6%, Val_loss:1.785, Lr:1.00E-02
Done
可视化训练损失和精度
过拟合严重,主要是由于数据量太小,参数我也没有仔细调整
使用测试集评估
acc能达到0.4333,还需要调优
model.eval()
epoch_test_acc, epoch_test_loss = test(test_loader, best_model, loss_fn)
epoch_test_acc, epoch_test_loss
(0.43333333333333335, 1.4856029596428078)
数据和完整代码
有需求可以点击下方链接,fork后可以获取所有代码
数据也上传了csdn一份
数据下载链接

















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











