






问题背景
本文讨论的是,当含有中文字符的文本出现乱码时,如何知道是什么原因造成的,并且推理出其原本的正确字符是什么。至于为什么要说含有中文字符,这是因为英文、数字和常见的符号字符都可以用 ASCII 码表示,而业界主流的字符集都是兼容包含 ASCII 字符集的,因此即使用错了字符集,这些字符通常情况下也是不会出现乱码的,当然一些古早的字符集除外,例如 IBM EBCDIC。
一般有三种情况会导致乱码的出现:一是字符编码是正确的,但是展现的时候使用了错误的编码字符集;二是字符被错误的方式做了转码并保存;三是网络、硬件的原因造成字节的丢失、变换。这三种情况中,前两者是人为因素,本文讨论的是这两种情况,第三种是外部因素。只能清洗,很难复原,本文不作讨论。
使用了错误编码字符集展现
第一种情况就是用了不正确的编码显示,举例来说,原本应该是 UTF-8 的字符,被以 GB 的方式展现,从而出现乱码。这类乱码是有其规律性的,通常情况会是这样:
| 中文原本的编码集 | 错误展现的编码集 | 乱码形式 |
|---|---|---|
| GB 18030 | ISO-8859-1 | ¸ù¾ÝÂÒÂë²Â±àÂë |
| GB 18030 | UTF-8 | ???±??? |
| UTF-8 | GB 18030 | 鏍规嵁涔辩爜鐚滅紪鐮� |
| UTF-8 | ISO-8859-1 | æ ¹æ®ä¹±ç çŒ |
可以看到,每种错误都有其鲜明的特征,有的是出现奇怪汉字字符,有的是出现问号,还有的出现了非英文的拉丁字母。
那么为什么会有这些鲜明的特征呢?我们逐一分析。
GB 18030 -> ISO-8859-1
这个原因很简单,查表可知,GB 18030 中的常用中文字符一般是双字节的,首字节范围是 81-FE,次字节范围是 40-FE:
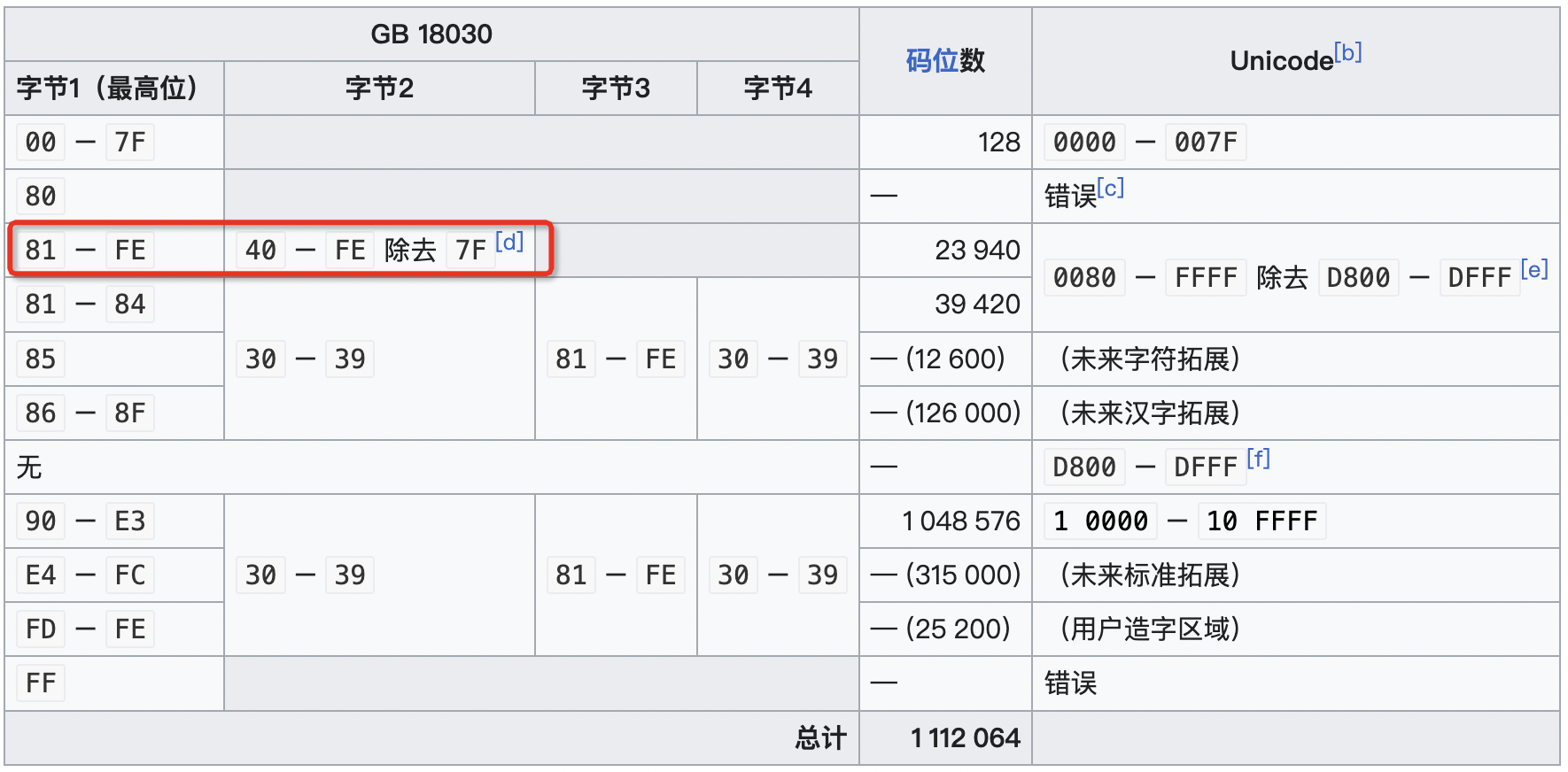
而 ISO-8859-1 是单字节拉丁字符集,这个区间的字符会集中在下图红框的范围内:
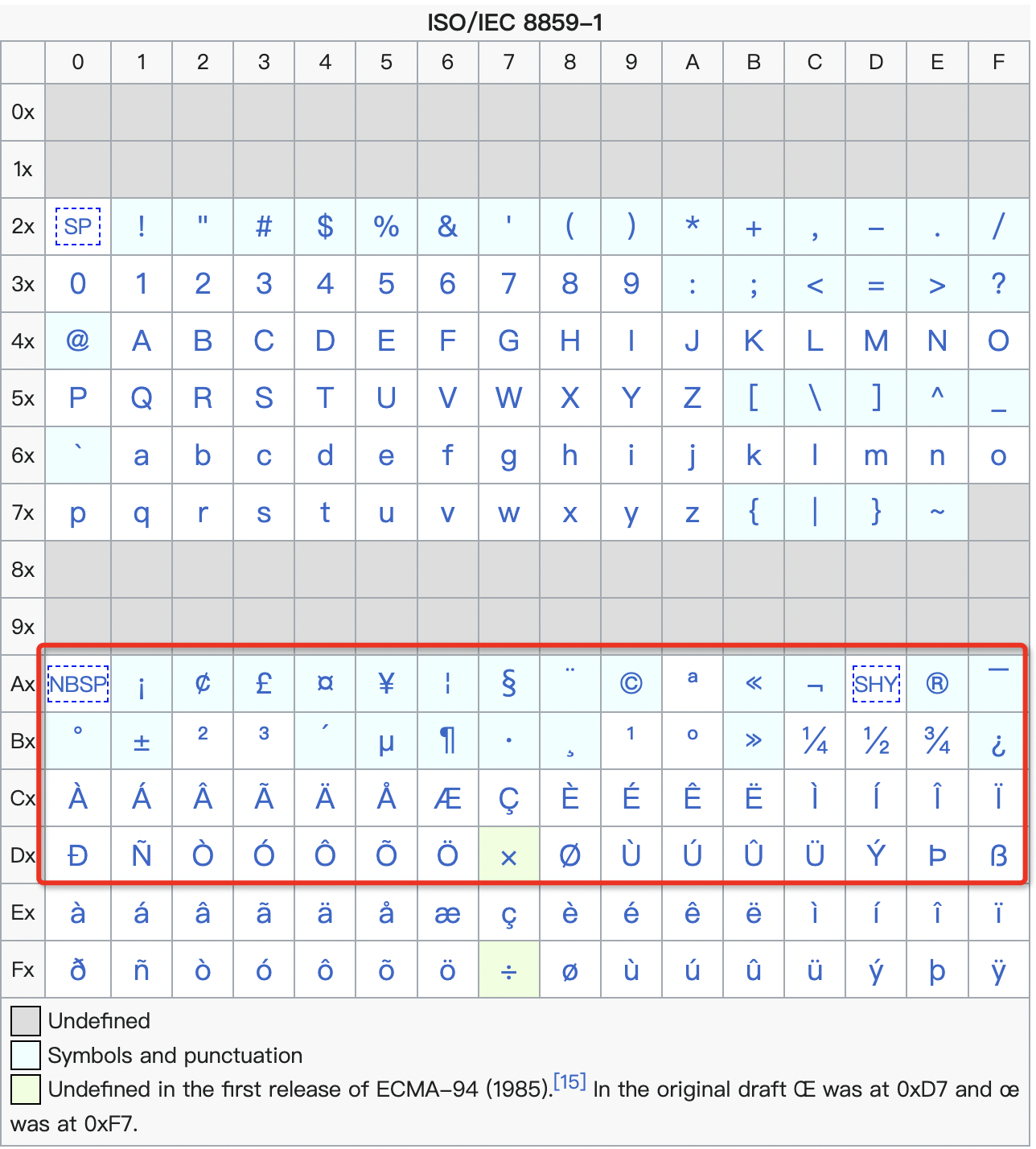
举个例子:汉字“我们”的 GB 18030 编码是“CED2 C3C7”,用 ISO-8859-1 来显示就是“CE D2 C3 C7”,于是变成了“ÎÒÃÇ”。
因此当出现这种形式的字符,就暗示了字符可能是被 GB 18030 被识别为了 ISO-8859-1
GB 18030 -> UTF-8
同样查表可知,GB 18030 中的常用中文字符一般是双字节的,首字节范围是 81-FE,次字节范围是 40-FE,而对于 UTF-8 而言,它是有纠错能力的,详见我的另一篇文章:为什么 UTF-8 比 GB 18030 编码有更好的容错性,规律如下:
- 如果这个 Unicode 码位位于 0000-007F 之间,则保持不变,也就是一个字节,因为不会大于 7F,因此字节最高位一定是 0
- 如果这个 Unicode 码位位于 0080-07FF 之间,这样的十六进制数最多可以表示成 11 位二进制数,将其看作 aaaaabbbbbb,然后转化成 110aaaaa,10bbbbbb 这样两个字节
- 如果这个 Unicode 码位位于 0800-D7FF 或 E000-FFFF 之间,这样的十六进制数最多可以表示成 16 位二进制数,将其看作 aaaabbbbbbcccccc,然后转化成 1110aaaa, 10bbbbbb, 10cccccc 这样三个字节
- 如果这个 Unicode 码位位于 10000-10FFFF 之间,这样的十六进制数最多可以表示成 21 位二进制数,将其看作 aaabbbbbbccccccdddddd,然后转化成 11110aaa, 10bbbbbb, 10cccccc, 10dddddd 这样四个字节
举个例子:汉字“我们”的 GB 18030 编码是“CED2 C3C7”,无论从哪个字符开始解析,都不符合 UTF-8 编码的规则,于是替换成了“?”。
因此 GB 18030 的中文字符到了 UTF-8 那里很容易就能识别出异常,于是用问号替代。因此当出现这种形式的乱码,就暗示了字符可能是被 GB 18030 被识别为了 UTF-8。
UTF-8 -> GB 18030
因为 UTF-8 独特的编码特性,以及对于中文字符一般又都是三字节的,所以不难发现中文字符在 UTF-8 编码中往往首字节以 E 开头,二三字节以 8、9、A、B 开头。这是因为三字节 UTF-8 编码会在首字节添加 1110,正好是 16 进制的 E,二三字节添加 10,范围则是 16 进制的 8-B。从上面的编码表看出这些字节在 GB 18030 同样是有效的中文字符,但会是不同的汉字,于是就出现了都是奇怪汉字的现象。
举个例子:汉字“我们”的 UTF-8 编码是“E68891 E4BBAC”,用 GB 18030 解析的话是“E688 91E4 BBAC”,于是就变成了“鎴戜滑”。
因此当出现这种奇怪汉字形式的乱码,就暗示了字符可能是被 UTF-8 被识别为了 GB 18030。
UTF-8 -> ISO-8859-1
这种情况和第一种情况是非常像的,只不过 UTF-8 汉字字符字节区间和 GB 18030 的稍有不同,因此在 ISO-8859-1 中会主要落在下面 E 行区间:
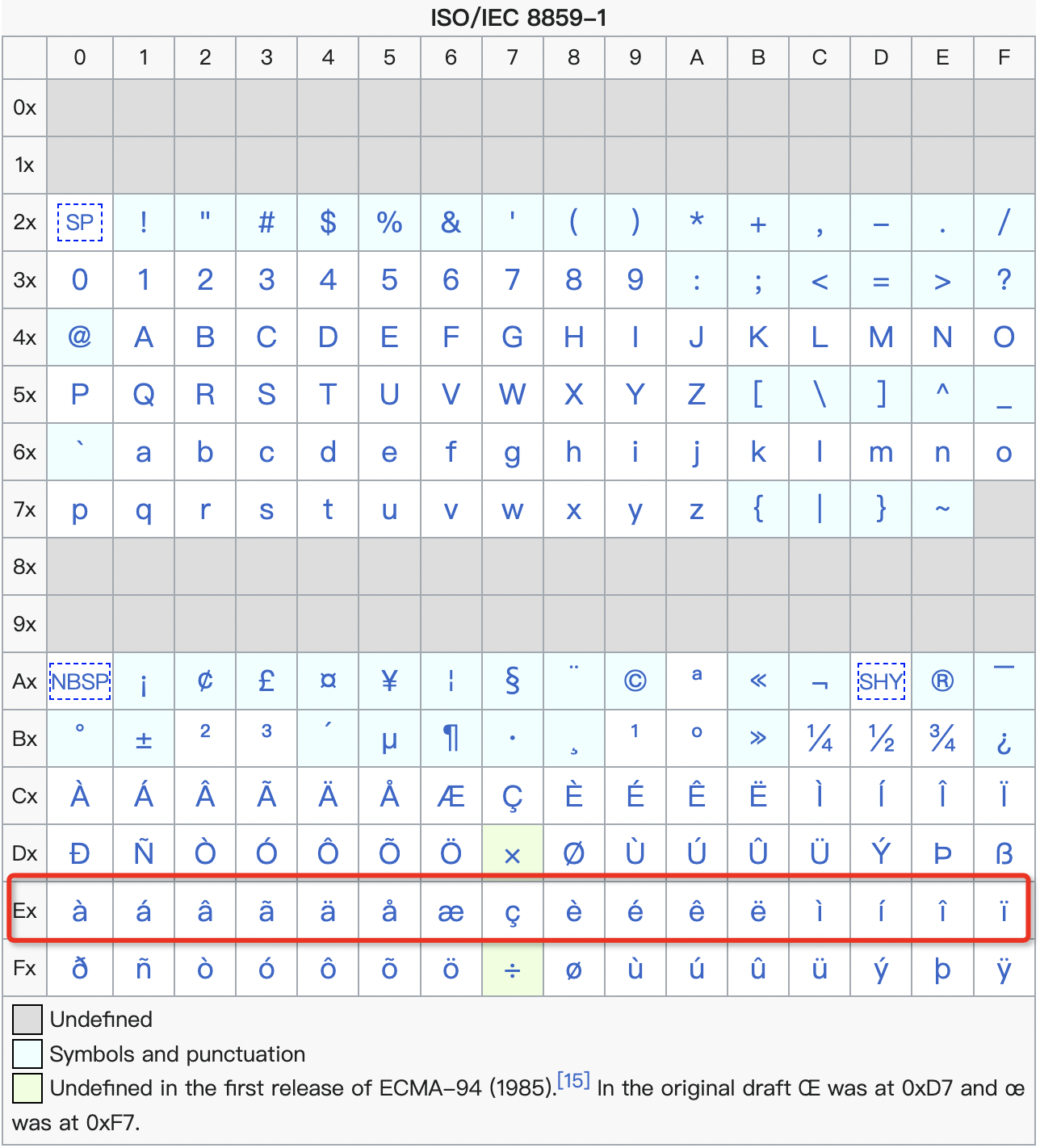
举个例子:汉字“我们”的 UTF-8 编码是“E68891 E4BBAC”,用 ISO-8859-1 来显示就是“E6 88 91 E4 BB AC”,于是变成了“我们”。
所以,当看到乱码中有这几个字符高频出现,往往暗示了字符可能是被 UTF-8 被识别为了 ISO-8859-1。
字符被错误的方式做了转码
上面讨论的字符虽然被显示错了,但仍是以另一种正确的格式编码的,下面讨论下字符被错误的方式做了转码,这种情况会难一些,甚至是不可逆的。为了更好地说明,举一个实际的例子:
有个用户按照如下方式创建表并写入数据:
create table testlatin (c1 varchar(100) charset latin1);
insert into testlatin values (x'E68891E4BBAC');
set names latin1;
select c1,hex(c1) from testlatin;
+--------+--------------+
| c1 | hex(c1) |
+--------+--------------+
| 我们 | E68891E4BBAC |
+--------+--------------+
到这里,我们创建了一个表,其中的 C1 字段是 latin1 字符集,然后以 UTF-8 编码的方式插入中文字符“我们”,请注意这种用法是不规范的,但却在很多用户那里广泛使用。用户的初衷是让数据库只保存字符的二进制编码,由应用自身来做编码和解码,这确实增加了灵活性,比如不同字符集甚至可以都存进去,但是这种混存会给以后的运维、迁移带来隐患。
另外这里 set names latin1 其实是对数据库做了欺骗,作用和 Db2 LUW 中的 db2set DB2CODEPAGE=819 功能类似,使得数据库误以为写入和读取(本例只用到了读取)的字符集和存储的字符集一样,让数据库不要去做转换,当然这里终端字符集必须设置成 UTF-8,以保证输入和显示(这里只用到显示)的字符集是 UTF-8 的。
若干年后,用户在创建新一代数据库的时候,为了规范,决定统一使用 UTF-8 字符集的数据库,并通过 CDC 类软件将数据同步到了新的数据库,然后查询的是否发现是这样的:
select c1,hex(c1) from testutf8;
-- CDC 同步后
+--------+--------------+
| c1 | hex(c1) |
+--------+--------------+
| 我们 | C3A6C288C291C3A4C2BBC2AC |
+--------+--------------+
这是因为源端数据是 latin1 的,CDC 在转换的时候感知不到里面实际存的是 UTF-8 编码字符,仍然按照 latin1 的方式转成 UTF-8,我们看看 E68891E4BBAC 在 latin1 里面是什么字符:
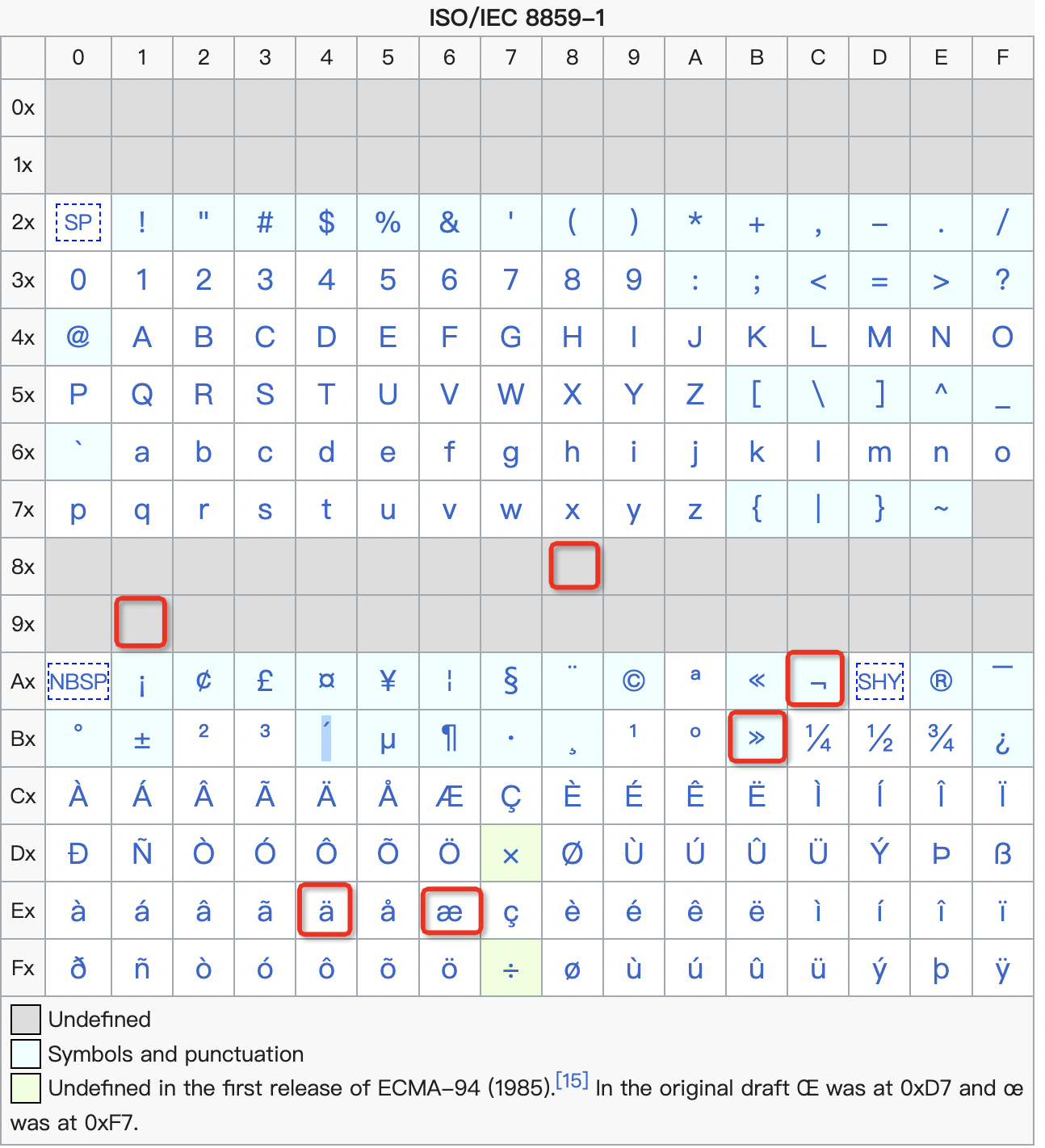
果然,这些字符就是显示出来的字符 我们,并且转成了 UTF-8 的编码,也就是 C3A6C288C291C3A4C2BBC2AC。
这样一来,这些中文字符经过二次编码和转码,完全失去了其原来的样子,这类问题就比较难查,需要调查源和目标两端的字符集设置,大胆猜想,小心求证。
实际案例中发现,如果上述例子是 GB 18030 或者 UTF-8 编码存入,哪怕目标端也是 latin1,CDC 转码的时候还会将 88、91 这种 latin1 无效字符转成 3F,也就是“问号”,因为这涉及到 CDC 类软件对于无效字符的处理方式,这样一来就又增加了问题的复杂度。


















 2487
2487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











