








LongAdder相比AtomicLong有哪些优势?
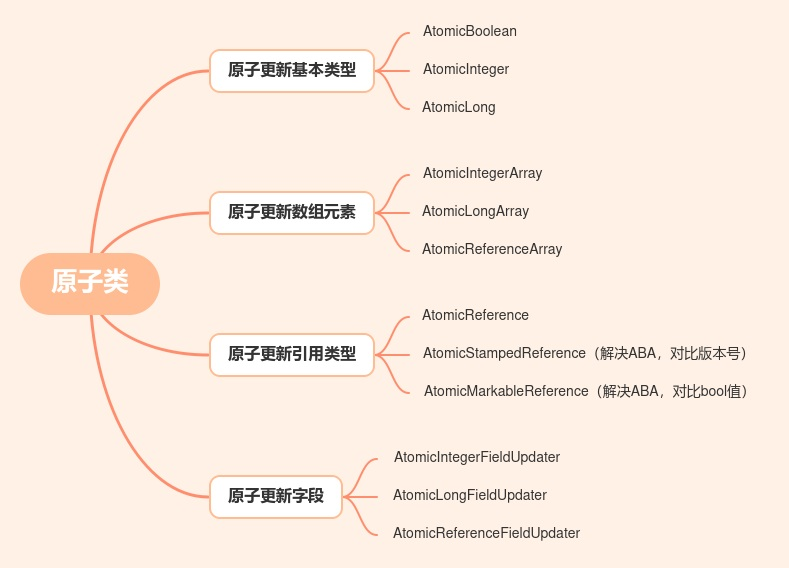
上一节我们分享了原子类一些常用的工具类,除此之外还提供了另外4个原子类。

这4个原子类和我们之前提到的原子类的设计思想不太一样,因此单开一节来分析
AtomicLong sum = new AtomicLong();
// 1
System.out.println(sum.incrementAndGet());
LongAdder sum1 = new LongAdder();
sum1.increment();
// 1
System.out.println(sum1);
可以看到使用方式差不多,但是LongAdder的性能比较高,因此阿里巴巴《Java开发手册》中也有如下建议

那么LongAdder是如何实现高性能的?
其实我们可以把对一个变量的cas操作,分摊到对多个变量的cas操作,这样就可以提高并发度,想获取最终的值时,只需要把多个变量的值加在一起即可。这就是LongAdder实现高并发的秘密
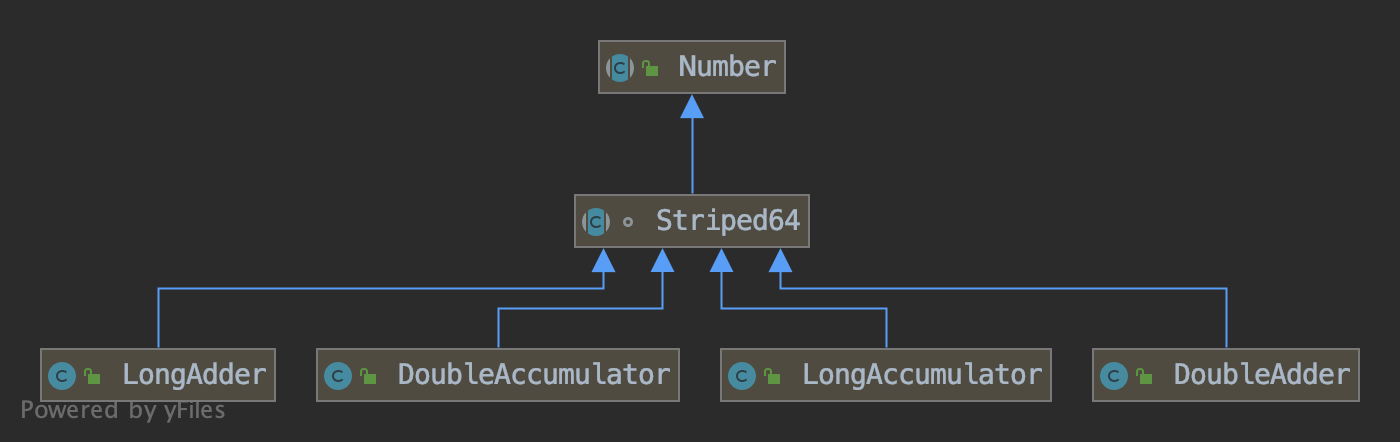
除去LongAdder外,还新提供了一个类LongAccumulator。LongAccumulator比LongAdder的功能呢更强大
LongAdder只能进行累加操作,并且初始值默认为0。而LongAccumulator可以自己定义一个二元操作符,并且可以传入一个初始值。
我们来看一下用LongAccumulator实现累乘的操作
LongAccumulator sum2 = new LongAccumulator((a, b) -> a * b, 1);
for (int i = 1; i < 5; i++) {
sum2.accumulate(i);
}
// 24
// 4 * 3 * 2 * 1
System.out.println(sum2);
除此之外还有DoubleAdder和DoubleAccumulator类
DoubleAdder的实现思路LongAdder类似,因为没有double类型的cas函数,所以DoubleAdder底层也是用long实现的,只不过多了long和double的相互转换
DoubleAccumulator的实现思路和LongAccumulator类似,只是多了一个二元操作符
LongAdder如何实现高性能的?
LongAdder实现高并发的秘密就是用空间换时间,对一个值的cas操作,变成对多个值的cas操作,当获取数量的时候,对这多个值加和即可。
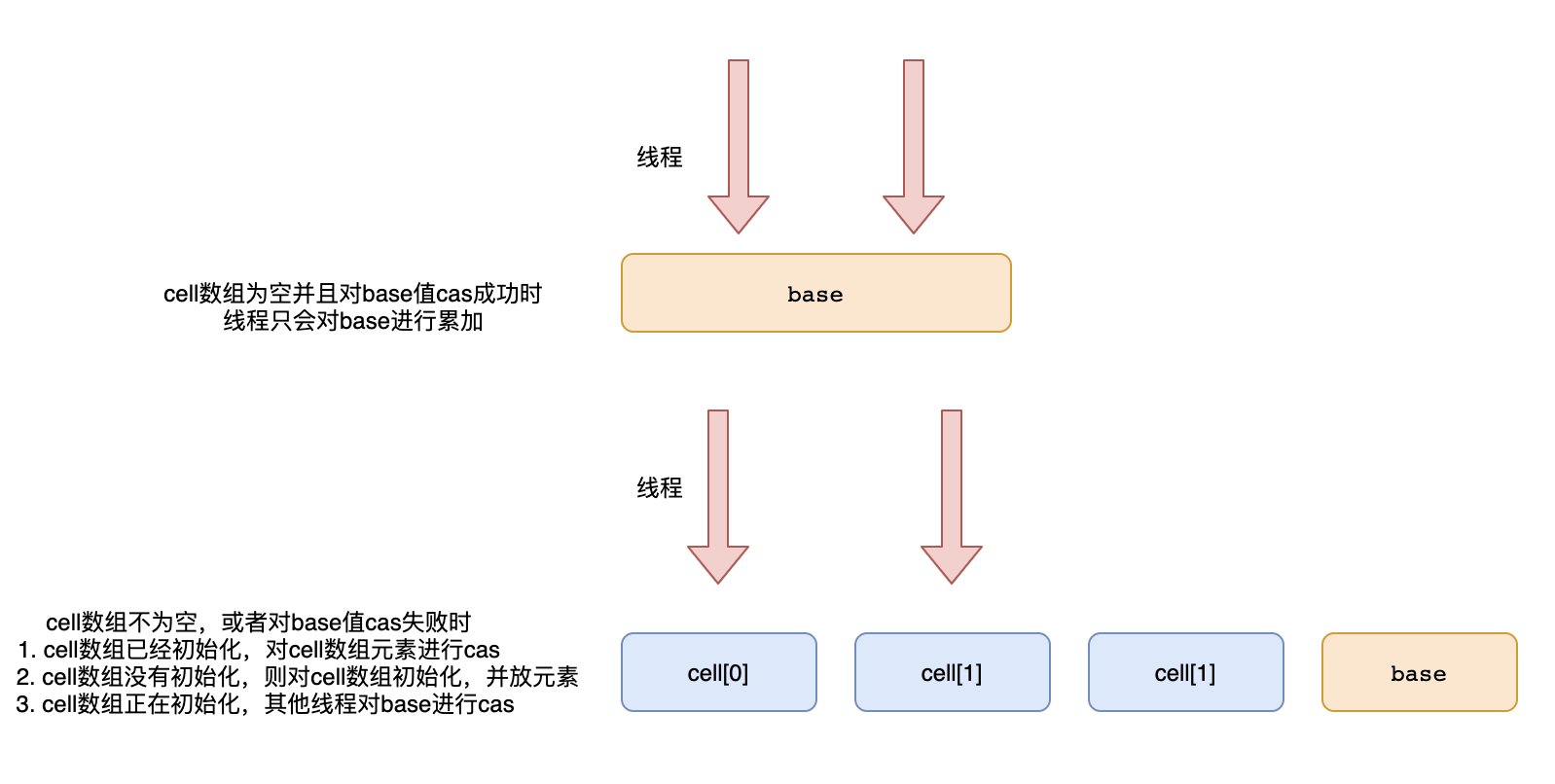
具体到源码就是
- 先对base变量进行cas操作,cas成功后返回
- 对线程获取一个hash值(调用getProbe),hash值对数组长度取模,定位到cell数组中的元素,对数组中的元素进行cas
其中对base值的操作是由Striped64的实现类来实现的,而对cell数组的操作则由Striped64来实现
增加数量
// LongAdder
public void increment() {
add(1L);
}
// LongAdder
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
// 数组为空则先对base进行一波cas,成功则直接退出
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
当数组不为空,并且根据线程hash值定位到数组某个下标中的元素不为空,对这个元素cas成功则直接返回,否则进入longAccumulate方法
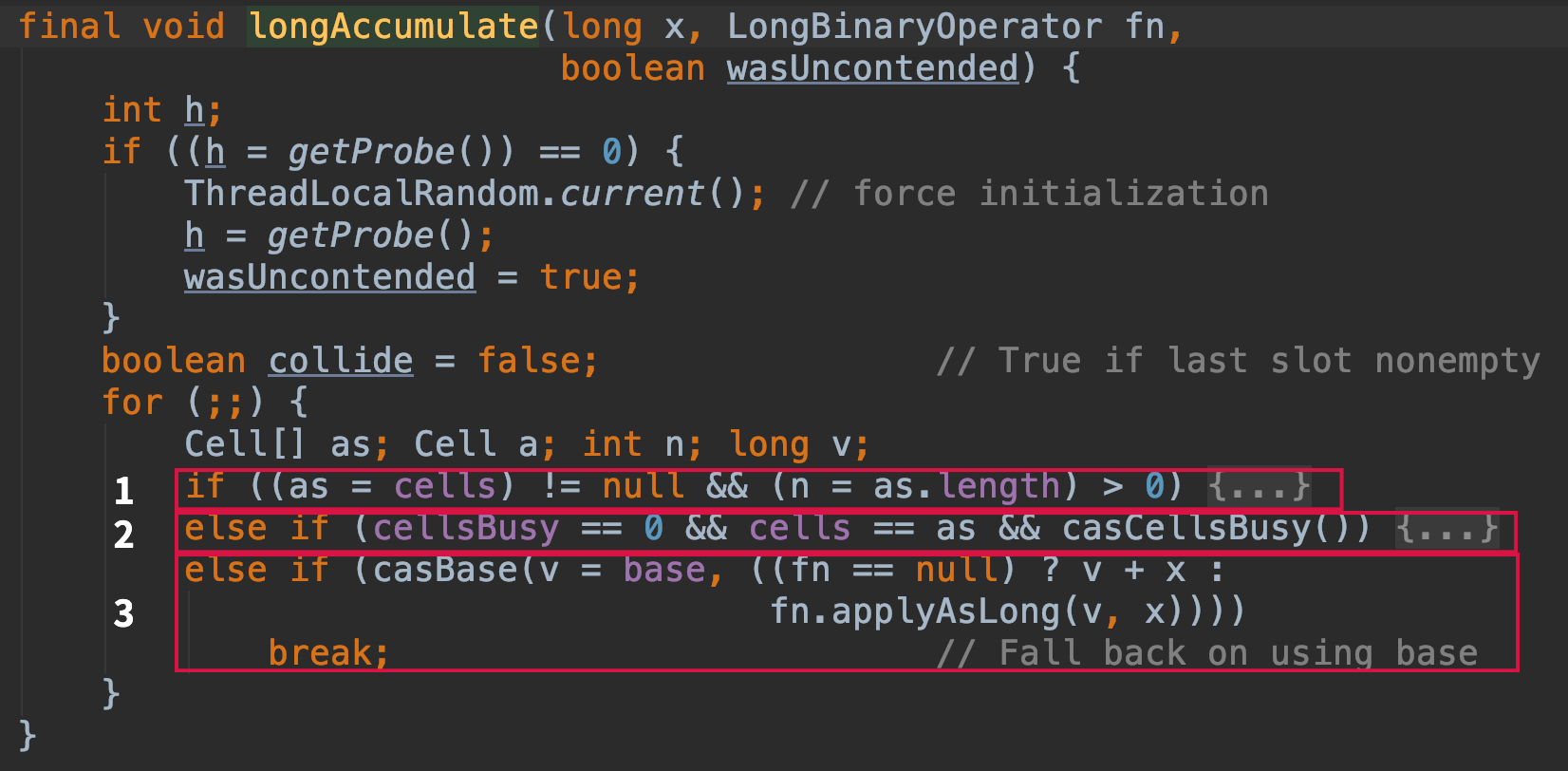
- cell数组已经初始化完成,主要是在cell数组中放元素,对cell数组进行扩容等操作
- cell数组没有初始化,则对数组进行初始化
- cell数组正在初始化,这时其他线程利用cas对baseCount进行累加操作
// Striped64
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
// 往数组中放元素是否冲突
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
// 有线程在操作数组cellsBusy=1
// 没有线程在操作数组cellsBusy=0
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
// // 和单例模式的双重检测一个道理
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
// 成功在数组中放置元素
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
// cas baseCount失败
// 并且往CounterCell数组放的时候已经有值了
// 才会重新更改wasUncontended为true
// 让线程重新生成hash值,重新找下标
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
// cas数组的值
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
// 其他线程把数组地址改了(有其他线程正在扣哦荣)
// 数组的数量>=CPU的核数
// 不会进行扩容
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
else if (!collide)
collide = true;
// collide = true(collide = true会进行扩容)的时候,才会进入这个else if
// 上面2个else if 是用来控制collide的
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
获取数量
base值+Cell数组中的值即可
// LongAdder
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
需要注意的是,调用sum()返回的数量有可能并不是当前的数量,因为在调用sum()方法的过程中,可能有其他数组对base变量或者cell数组进行了改动
// AtomicLong
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
而AtomicLong#getAndIncrement方法则会返回递增之后的准确值,因为cas是一个原子操作
最后告诉大家一个小秘密,jdk1.8中ConcurrentHashMap对元素个数的递增和统计操作的思想和LongAdder一摸一样,代码基本相差无几,有兴趣的可以看看。
计数用synchronized,AtomicLong,还是LongAdder?
在很多系统中都用到了计数的功能,那么计数我们应该用synchronized,AtomicLong,LongAdder中的哪一个呢?来跑个例子
public class CountTest {
private int count = 0;
@Test
public void startCompare() {
compareDetail(1, 100 * 10000);
compareDetail(20, 100 * 10000);
compareDetail(30, 100 * 10000);
compareDetail(40, 100 * 10000);
}
/**
* @param threadCount 线程数
* @param times 每个线程增加的次数
*/
public void compareDetail(int threadCount, int times) {
try {
System.out.println(String.format("threadCount: %s, times: %s", threadCount, times));
long start = System.currentTimeMillis();
testSynchronized(threadCount, times);
System.out.println("testSynchronized cost: " + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
testAtomicLong(threadCount, times);
System.out.println("testAtomicLong cost: " + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
testLongAdder(threadCount, times);
System.out.println("testLongAdder cost: " + (System.currentTimeMillis() - start));
System.out.println();
} catch (Exception e) {
e.printStackTrace();
}
}
public void testSynchronized(int threadCount, int times) throws InterruptedException {
List<Thread> threadList = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
threadList.add(new Thread(()-> {
for (int j = 0; j < times; j++) {
add();
}
}));
}
for (Thread thread : threadList) {
thread.start();
}
for (Thread thread : threadList) {
thread.join();
}
}
public synchronized void add() {
count++;
}
public void testAtomicLong(int threadCount, int times) throws InterruptedException {
AtomicLong count = new AtomicLong();
List<Thread> threadList = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
threadList.add(new Thread(()-> {
for (int j = 0; j < times; j++) {
count.incrementAndGet();
}
}));
}
for (Thread thread : threadList) {
thread.start();
}
for (Thread thread : threadList) {
thread.join();
}
}
public void testLongAdder(int threadCount, int times) throws InterruptedException {
LongAdder count = new LongAdder();
List<Thread> threadList = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
threadList.add(new Thread(()-> {
for (int j = 0; j < times; j++) {
count.increment();
}
}));
}
for (Thread thread : threadList) {
thread.start();
}
for (Thread thread : threadList) {
thread.join();
}
}
}
threadCount: 1, times: 1000000
testSynchronized cost: 187
testAtomicLong cost: 13
testLongAdder cost: 15
threadCount: 20, times: 1000000
testSynchronized cost: 829
testAtomicLong cost: 242
testLongAdder cost: 187
threadCount: 30, times: 1000000
testSynchronized cost: 232
testAtomicLong cost: 413
testLongAdder cost: 111
threadCount: 40, times: 1000000
testSynchronized cost: 314
testAtomicLong cost: 629
testLongAdder cost: 162
并发量比较低的时候AtomicLong优势比较明显,因为AtomicLong底层是一个乐观锁,不用阻塞线程,不断cas即可。但是在并发比较高的时候用synchronized比较有优势,因为大量线程不断cas,会导致cpu持续飙高,反而会降低效率
LongAdder无论并发量高低,优势都比较明显。且并发量越高,优势越明显
参考博客
[1]https://www.cnblogs.com/thisiswhy/p/13176237.html
















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











