







LeetCode周赛第315&317场记录
第315场周赛值得学习的点不是很多,这里只是简单地总结一下。
前三题都非常简单,两道middle题都是关于数字反转的,使用标准库函数首先将其转为字符串,翻转过来之后再stoi返回即可高效地完,核心代码如下,其余的部分都是暴力法即可:
int reverseNumber(int Num) // 反转一个数字的函数,使用标准库实现
{
string S = to_string(Num);
reverse(S.begin(), S.end());
return stoi(S);
}
第316场周赛因为要开组会,没有打。
接下来是317场周赛的部分:
6220. 可被三整除的偶数的平均值

第一题很简单,但是要注意的地方在于我们要求平均数的数字必须满足以下两个条件:
1.可以被3整除
2.必须是偶数
另外要注意,如果没有这样的数字,那么计数值为0,但不可以除以0。
完整的代码如下:
class Solution {
public:
int averageValue(vector<int>& nums)
{
int Sum = 0, Counter = 0;
for(auto Each : nums)
if((Each % 3 == 0) && (Each % 2 == 0))
{
Sum += Each;
++Counter;
}
return Counter == 0 ? 0 : (Sum / Counter);
}
};
6221. 最流行的视频创作者
第二题主要考查阅读理解能力对数据进行处理和排序,思路上没有什么难度,稍微有点费代码,直接给出含有注释的代码:
class Solution {
public:
vector<vector<string>> mostPopularCreator(vector<string>& creators, vector<string>& ids, vector<int>& views) {
int n = creators.size(), MaxViews = 0;
vector<vector<string>> Ans;
vector<string> TopCreators; // 总播放量最高的创作者集合,可能不止一个
unordered_map<string, long long> ViewCounter;// 创作者和他们对应的播放量总量
unordered_map<string, pair<string, int>> TopVideos; //创作者和他们对应的最高播放次数的作品
for(int i = 0 ; i < n ; ++i)
{
ViewCounter[creators[i]] += views[i]; // 累计创作者播放总量
if(TopVideos.count(creators[i]) == 0) // 如果当前创作者播放量最高的视频没被记录
TopVideos[creators[i]] = make_pair(ids[i], views[i]);
else if(TopVideos[creators[i]].second < views[i]) // 或者已经被记录但是新的作品播放量更高
TopVideos[creators[i]] = make_pair(ids[i], views[i]);
else if(TopVideos[creators[i]].second == views[i] && TopVideos[creators[i]].first > ids[i]) // 或者播放量一样多但是新的作品名字字典序更小
TopVideos[creators[i]] = make_pair(ids[i], views[i]); // 这三种情况都应该将新的记录插入哈希表
else continue;
}
/* 找出播放总量最高的创作者,可能不止一个 */
for(auto iter = ViewCounter.begin() ; iter != ViewCounter.end() ; ++iter)
{
if(iter->second > MaxViews)
{
TopCreators.clear();
TopCreators.push_back(iter->first);
MaxViews = iter->second;
}
else if(iter->second == MaxViews)
TopCreators.push_back(iter->first);
}
/* 将这几个播放量最高的创作者的代表作加入答案,至此结束 */
for(auto& Each : TopCreators)
Ans.push_back({Each, TopVideos[Each].first});
return Ans;
}
};
6222. 美丽整数的最小增量

这道题我一开始使用的是暴力法,但是这样一定会超时,因为这道题最终的答案可能会很大,超过
1
0
8
10^8
108。所以这道题使用暴力法从0开始一点点试下去一定会超时,这是一个基本的分析。
这道题还是应该使用模拟+贪心来解决,贪心的思路在比赛时我也想到了,但是我当时不知道该怎么处理进位,其实只需要对原先的数字+1就可以了,这在以下的代码中会集中展示。
class Solution {
/*以下这个函数用来计算一个数字中各个数位上的数字之和,很简单*/
int getBitSum(long long x) // at most 12 times
{
int Ans = 0;
while(x)
{
Ans += (x % 10);
x /= 10;
}
return Ans;
}
public:
long long makeIntegerBeautiful(long long n, int target) {
long long Ans = 0, Base = 1;
/*贪心法:如果当前剩余数字各位之和仍大于target,那么循环继续*/
while(getBitSum(n) > target)
{
Ans += (10 - (n % 10)) * Base; // Ans应该保证与原先的n相加之后每一位上都可以向更高位进位,比如原先n的某位是1,那么Ans对应位应该是9
n /= 10; // 本质是模拟加法运算过程,这个数字加上Ans的运算完成之后n的当前位一定为0,对结果没有贡献,那么直接删除这一位
n++; // 因为还有向更高位的进位,所以对n加一
Base *= 10; // Base乘10,因为下一位一定要在更高位
}
return Ans;
}
};
这道题总的代码量不大,但思路其实还是很巧妙的。
6223. 移除子树后的二叉树高度

这道题还是挺难的,需要两趟DFS,第一趟DFS是为了求每个子树的高度,并且记录在哈希表里。第二趟DFS就是为了求出删去每个子树时剩余部分的最大高度,结果也记录在一张哈希表里,随后就是直接回答查询即可。
这里直接给出灵茶山艾府的代码,作为记录:
lass Solution {
public:
vector<int> treeQueries(TreeNode *root, vector<int> &queries) {
unordered_map<TreeNode*, int> height; // 每棵子树的高度
function<int(TreeNode*)> get_height = [&](TreeNode *node) -> int {
return node ? height[node] = 1 + max(get_height(node->left), get_height(node->right)) : 0;
};
get_height(root);
int res[height.size() + 1]; // 每个节点的答案
function<void(TreeNode*, int, int)> dfs = [&](TreeNode *node, int depth, int rest_h) {
if (node == nullptr) return;
++depth;
res[node->val] = rest_h;
dfs(node->left, depth, max(rest_h, depth + height[node->right]));
dfs(node->right, depth, max(rest_h, depth + height[node->left]));
};
dfs(root, -1, 0);
for (auto &q : queries) q = res[q];
return queries;
}
};
上面这段代码中最难想的地方在rest_h这个量,这个变量中记录的是裁剪掉当前节点为根的子树之后,剩余二叉树的深度。之所以要引入这个变量,是因为在向更深的子树前进时需要考虑到之前的情况,看如下这样的一种情况:
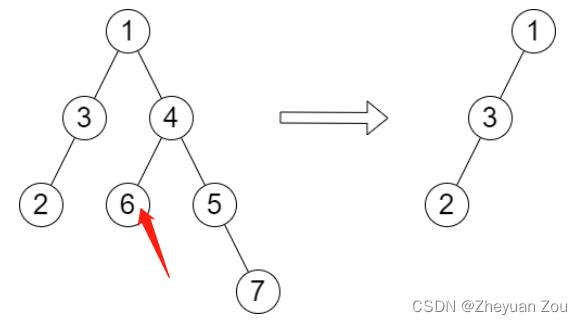
注意在求裁剪掉6号节点之后二叉树的高度时,它应该同时考虑到之前1-3-2构成的子树,但是这个子树的高度只有4号节点知道,在4号节点向更深的节点出发时,应该将之前子树的结果传递6号节点。6号节点在1-3-2和1-4-5-7构成的子树中找到更大值,这才是6号节点的结果值。

















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









