




 FSRCNN通过改进SRCNN的缺陷,提升了图像超分辨率处理的速度和效率。它直接使用低分辨率图像作为输入,采用反卷积层进行上采样,取消了非线性映射层,引入了收缩、映射和扩展层,使用更小的滤波器和更深的网络结构。网络在不同放大倍数下训练和测试速度快,仅需调整反卷积层。
FSRCNN通过改进SRCNN的缺陷,提升了图像超分辨率处理的速度和效率。它直接使用低分辨率图像作为输入,采用反卷积层进行上采样,取消了非线性映射层,引入了收缩、映射和扩展层,使用更小的滤波器和更深的网络结构。网络在不同放大倍数下训练和测试速度快,仅需调整反卷积层。
FSRCNN改进了SRCNN在速度上存在的缺陷:
1.SRCNN在将低分辨率图像送进网络之前,会先使用双三次插值法进行插值上采样操作,产生与groundtruth大小一致的低分辨率图像,这样会增加了计算复杂度,因为插值后的图像相比原始的低分辨率图像更大,于是在输入网络后各个卷积层的计算代价会增大,从而限制了网络的整体速度。
2.非线性映射层的计算代价太高。
FSRCNN在SRCNN基础上做了如下改变:
1.FSRCNN直接采用低分辨的图像作为输入,不同于SRCNN需要先对低分辨率的图像进行双三次插值然后作为输入;2.FSRCNN在网络的最后采用反卷积层实现上采样;3.FSRCNN中没有非线性映射,相应地出现了收缩、映射和扩展;
4.FSRCNN选择更小尺寸的滤波器和更深的网络结构。
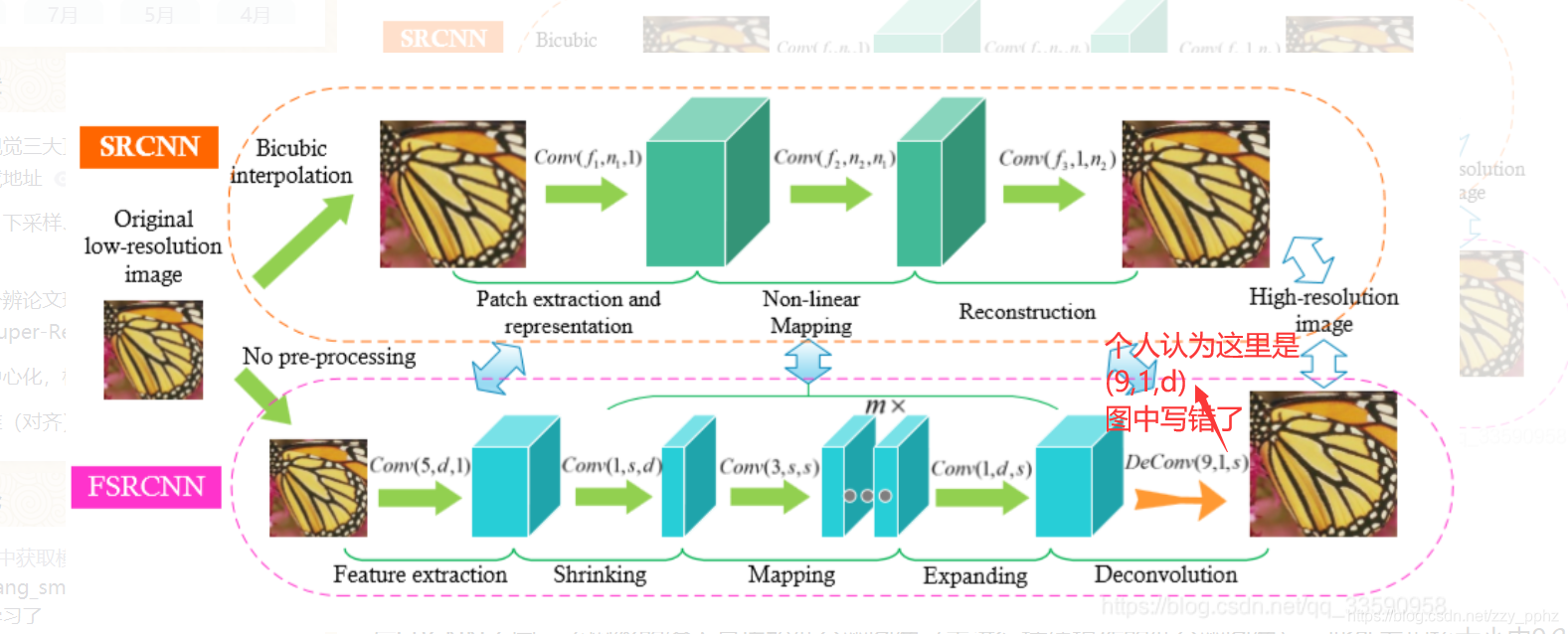
各个层的具体描述如下:
Feature Extraction
与SRCNN不同,该网络的输入是原始低分辨图像(未进行插值操作的低分辨图像),此外卷积核大小由99改为55。这是由于现在的输入图像尺寸变小了,还有在SRCNN中,其输入图像是经过原始低分辨率图像插值之后所得,所以不必用那么大的卷积核,在原始LR图像中用一个55的卷积核就可以获得在插值之后的LR图像中用99的卷积核几乎相同的信息(关于这一点的理解,我尚不太清楚,个人认为主要原因是输入图像尺寸变小导致卷积核尺寸变小),还有卷积核的个数是1,因为是在单通道(Y颜色通道)上进行比较。
Shrinking
这一层的主要作用是降维。由于低分辨率的特征维度(这里用d表示)太高,会极大的增加计算代价,所以采用此层,并设置卷积核尺寸为1*1。维度由d降到s(s远小于d)。
non-linear mapping
本文将在SRCNN中的mapping层分为m(表示mapping层的个数)个小mapping层,每个层的卷积核大小设置3*3,卷积核的数目设为s(降维后的特征维度)。
Expanding
该层的作用与Shrinking层相反,是为了扩张特征维度。之所以使用此层是因为直接使用低维的高分辨特征进行图像恢复的话,图像质量太差。具体的设置是:卷积核尺寸设为1*1,卷积核的数目设为d,与进行Feature extraction得到的特征维度一致。
Deconvolution
执行上采样操作,接受高分辨率特征,输出最终的超分辨结果。具体设置是,卷积核大小设为9*9,卷积核的个数为1,因为输入的是单通道图像。
网络中其他一些设置包括:将每一层的损失函数设为PReLU。不使用ReLU主要是为了避免在ReLU中由零梯度导致的“dead features”。损失函数使用均方误差。参数优化使用随机梯度下降。
图中mapping那里,不是说生成了m个,是进行了m次s个通道到s个通道的映射,比如s1到s2,s2到s3这样,到最后还是生成s个通道的特征图。具体可以看代码。
model构建代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









