






On-policy v.s.Off-policy
- On-policy: The agent learned and the agent interacting with the environment is the same.
- Off-policy: The agent learned and the agent interacting with the environment is different.
Issue of Importance Sampling:
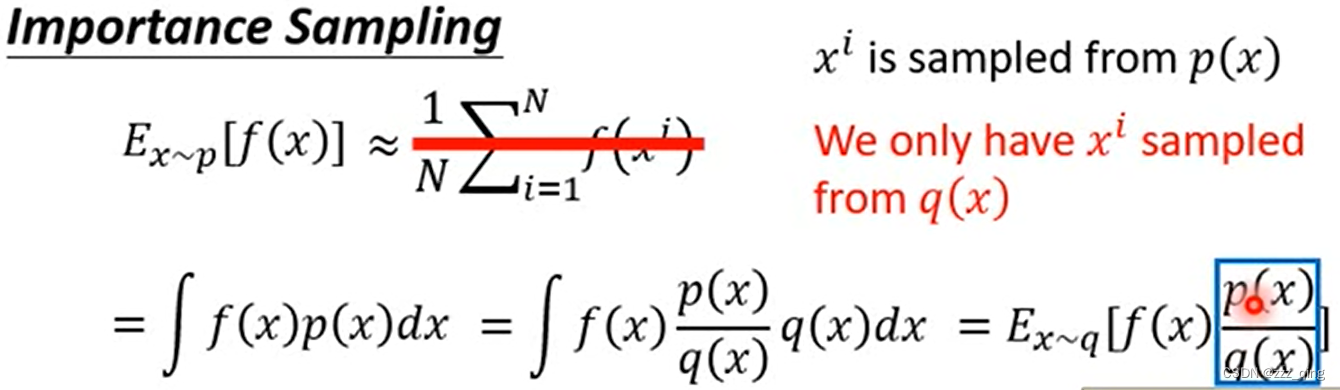
尽管q可以是任意的,但是q和p不能相差太多。如下图,VARx~p和VARx~q计算公式的第一项(即两个红框圈出来的地方)不同,如果q和p差别很大,p(x)/q(x)的值很大或很小,VARx~p和VARx~q就会相差很大。当sample的data不够多的时候,结果有可能出现很大的偏差:
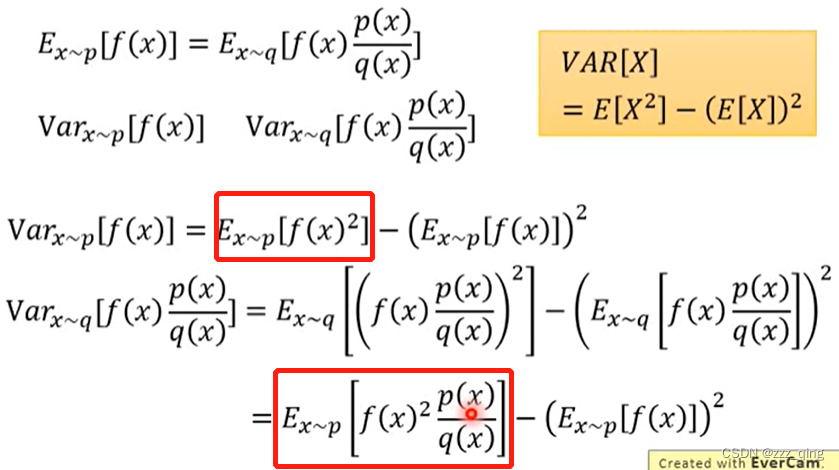
例如下图,当sample次数不够的时候,左式和右式可能会有很大的差距:
下面把Importance Sampling用在off-policy的case:


Importance Sampling要求Pθ和Pθ'不能差太多(即上面提到的q和p不能相差太多),这两个distribution差太多的话,important sampling的结果就会不好。如何避免它们差太多——PPO。

PPO计算公式中的KL diversions,它所计算的θ和θ'之间的距离并不是参数上的距离,而是它们behavior上的距离。
在做RL的时候,之所以考虑的不是参数上的距离,而是action上的距离,是因为很有可能对actor来说,参数的变化跟action的变化不是完全一致的。有时候参数小小的变了一下,output的行为就变很多,或者参数变很多,但output的行为没什么改变。我们真正在意的是actor它的行为上的差距。
PPO algorithm:

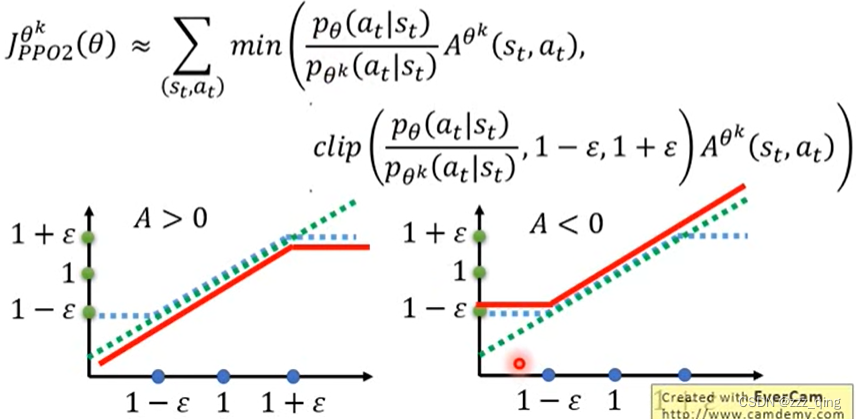
PPO2 algorithm:
min()这部分式子,能够让Pθ和Pθ'的差距不会太大。implement PPO2比implement PPO简单一点。















 1318
1318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









