






目录
Meta Learning – Gradient Descent as LSTM
Meta Learning - Train+Test as RNN
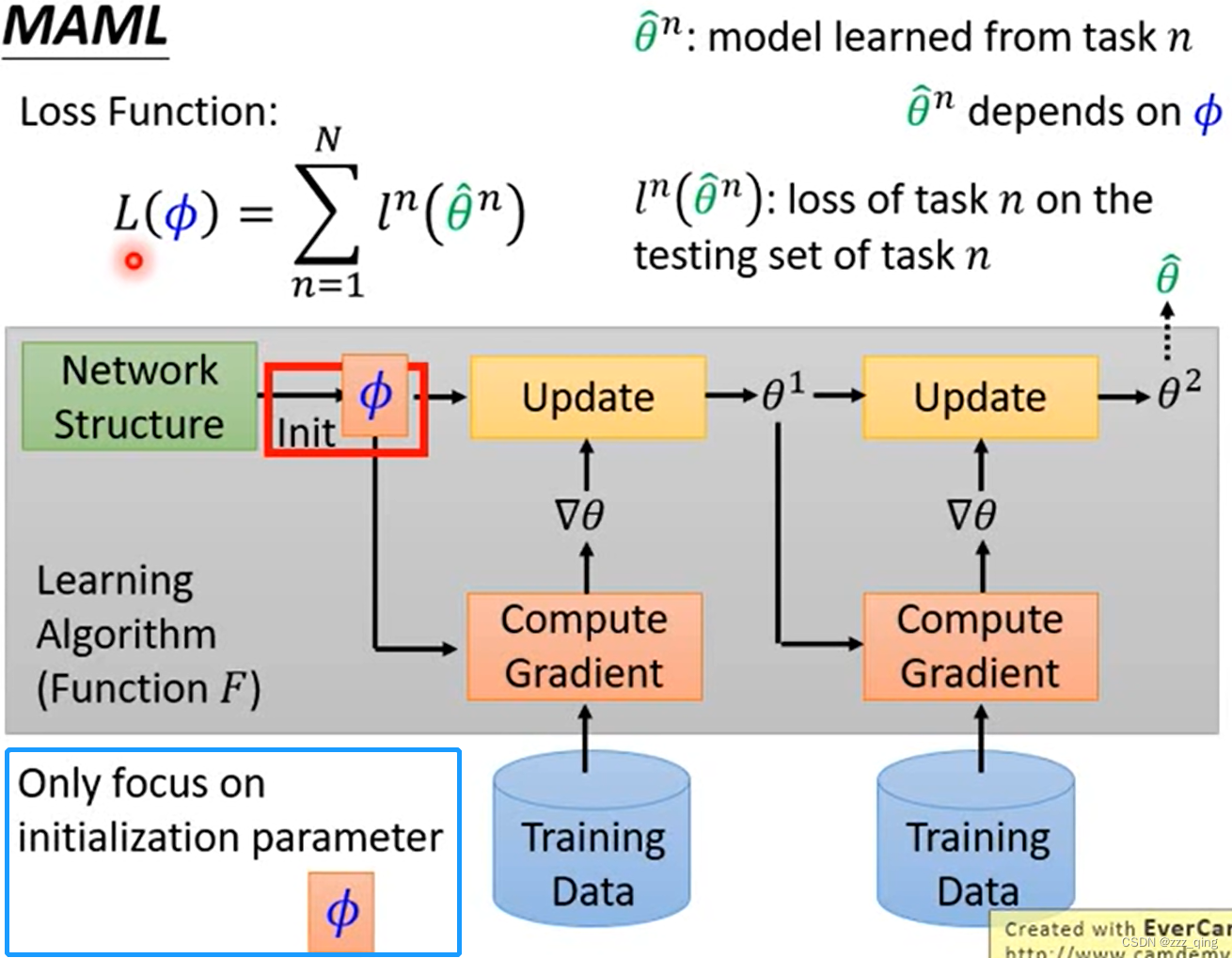
Meta Learning – MAML
Meta Learning:让机器自动找出learning algorithm
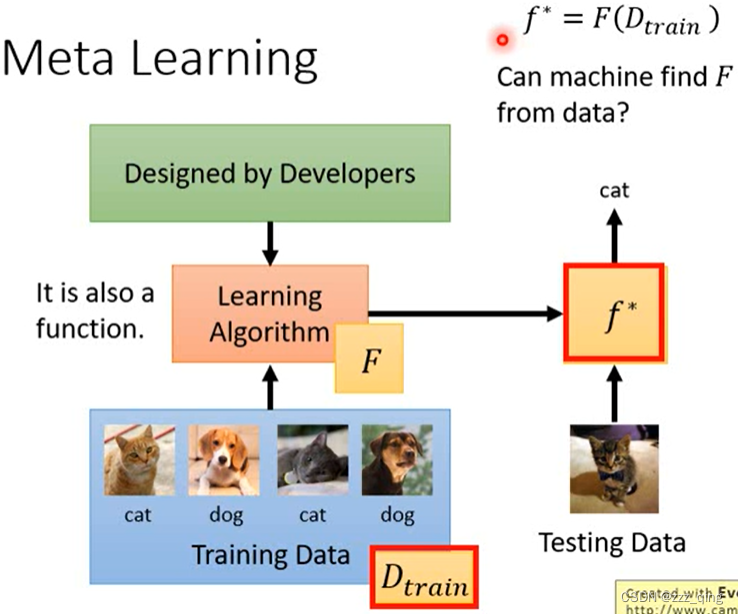
Meta Learning的三个步骤(前面笔记有写,这里简单复习一下):
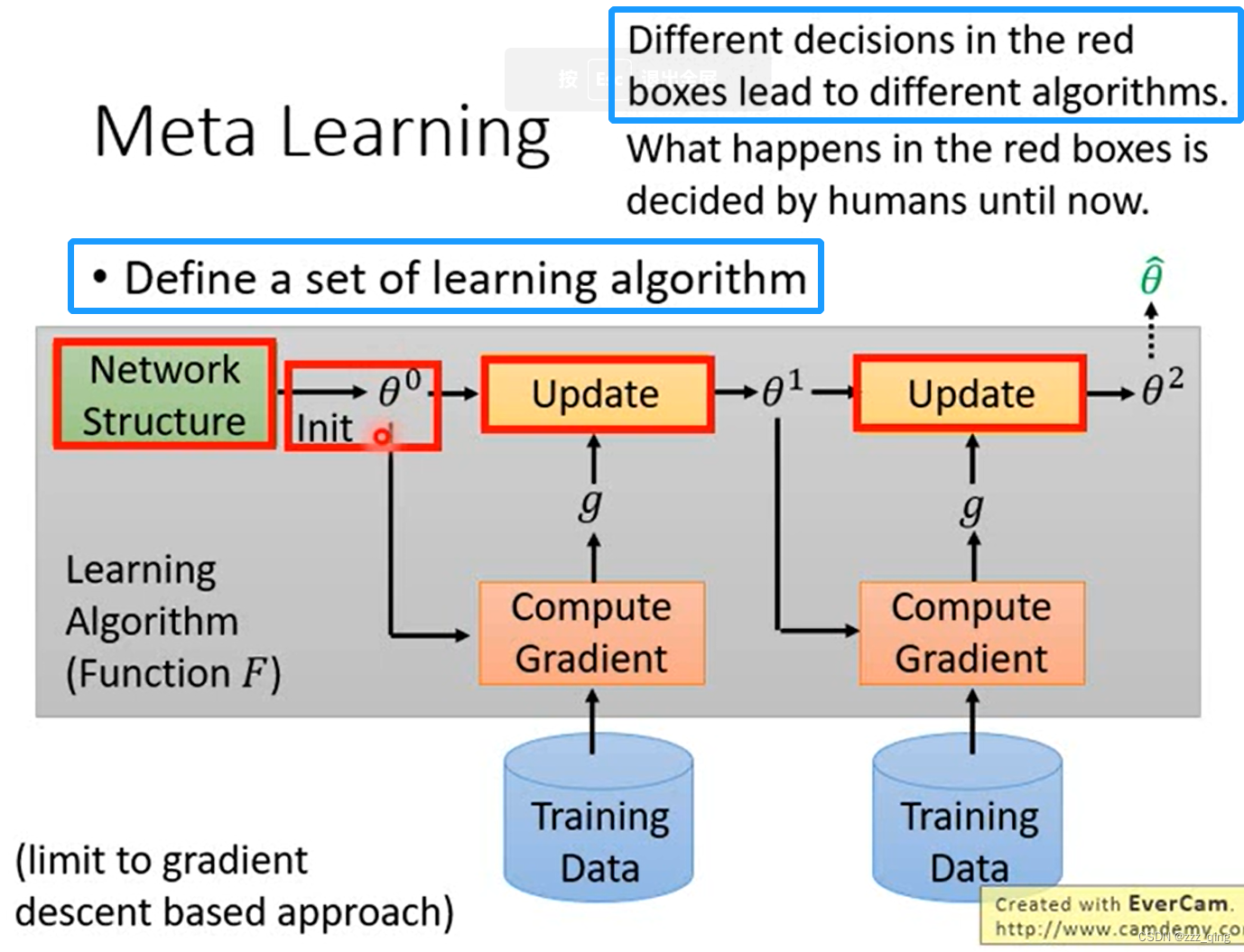
step 1: Define a set of learning algorithm
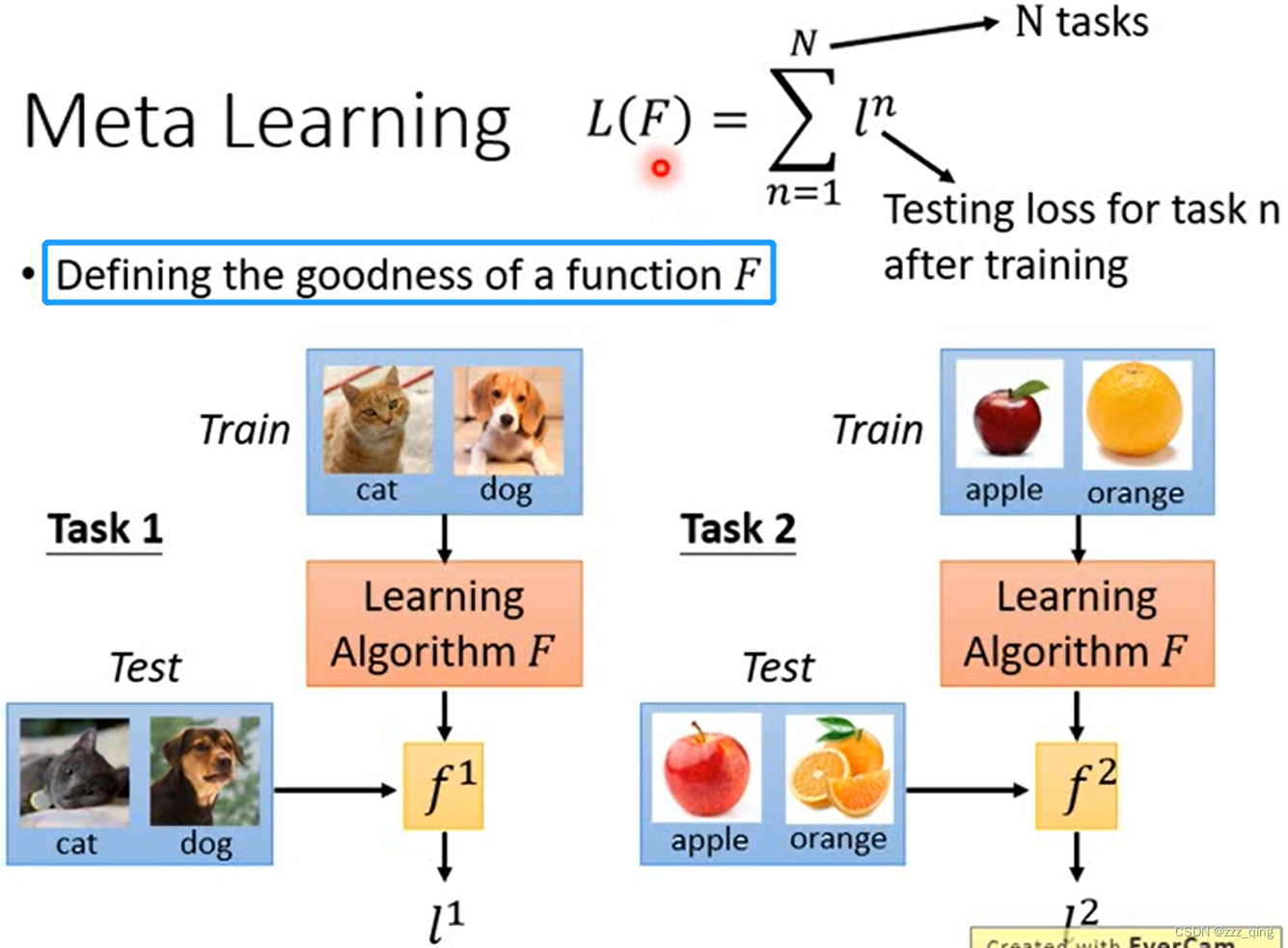
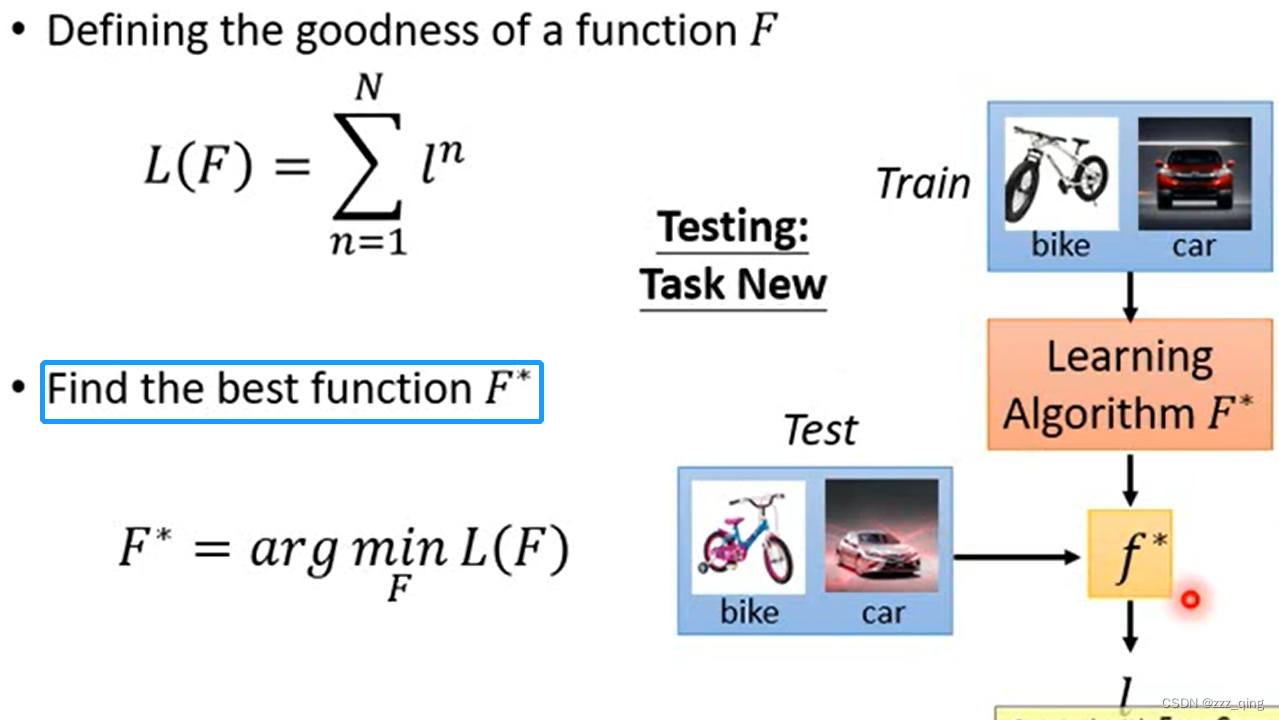
step 2: Defining the goodness of a function F
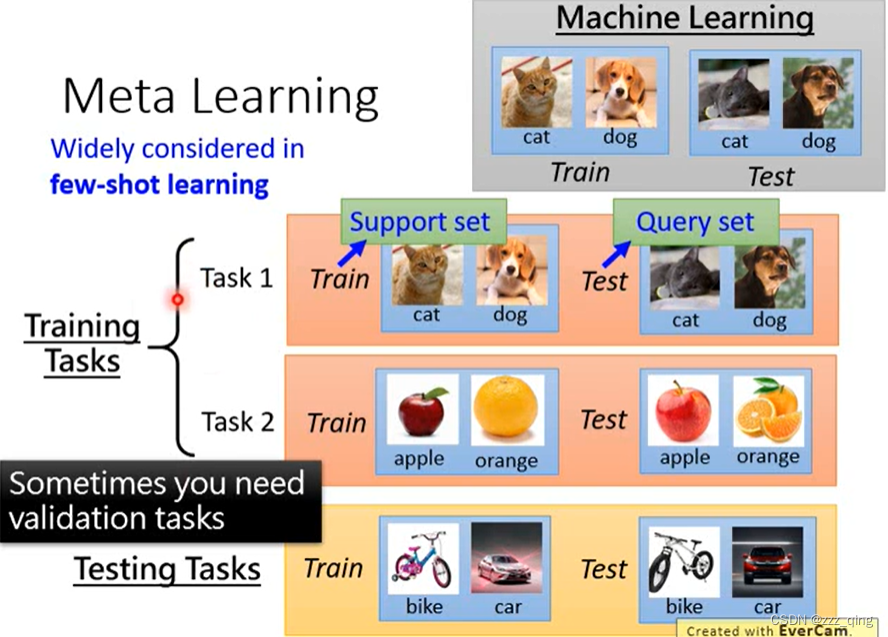
Meta Learning常常跟few-shot learning一起使用
step 3: Find the best function F*
下面介绍Meta Learning的两个technique:MAML、Reptile
MAML

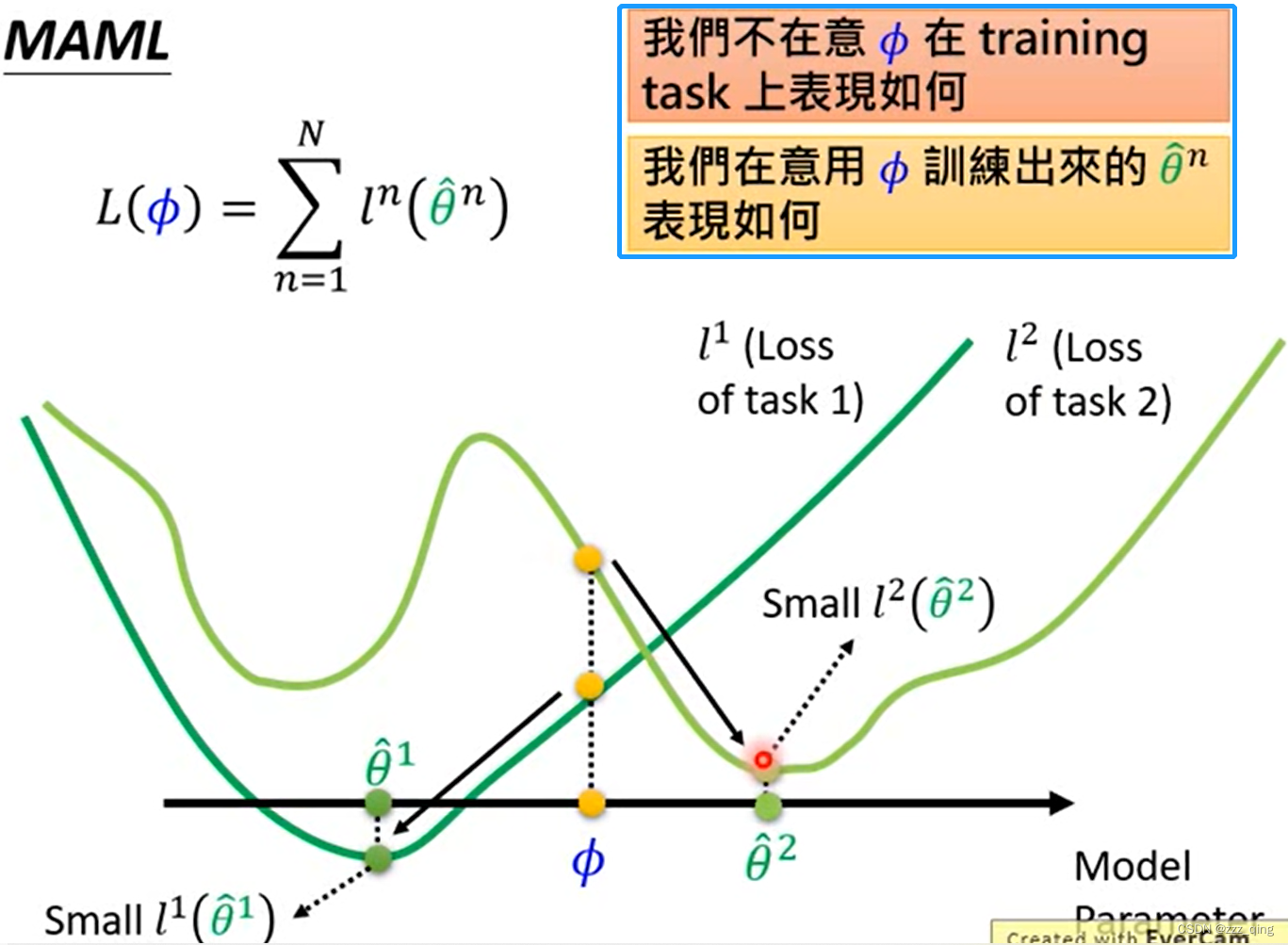
评价Φ的好坏:如下图,Φ本身拿去做task1和task2没有很强,但是Φ拿去做训练以后(用task1和task2的data做训练后)变得很强,那它就是一个好的Φ
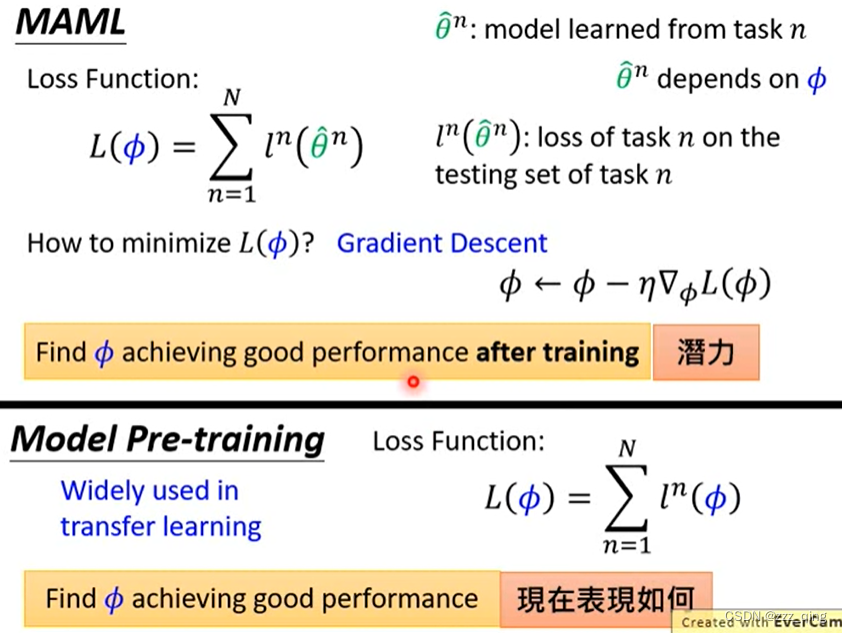
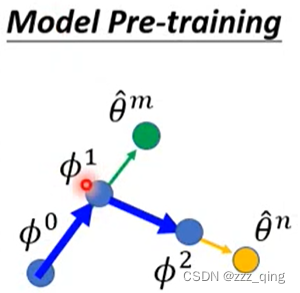
MAML v.s. Model Pre-training
MAML在实作的时候,training algorithm通常只做一次update,理由如下:
- Fast ... Fast ... Fast ...
- Good to truly train a model with one step.
- When using the algorithm, still update many times.
- Few-shot learning has limited data.
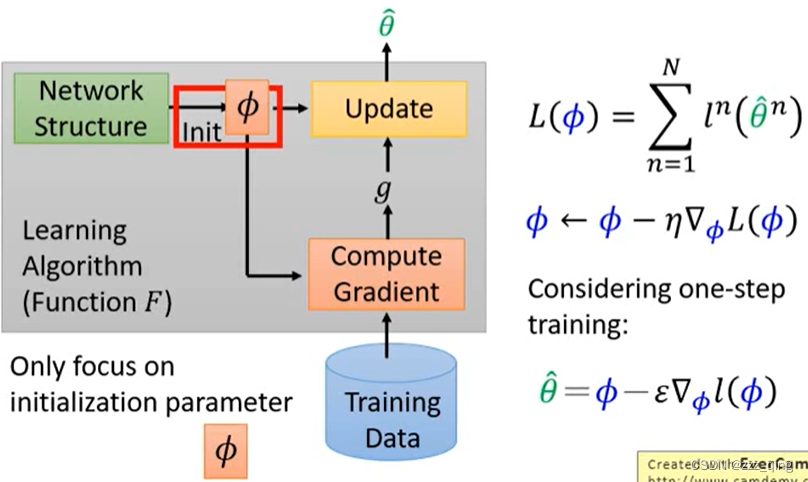
MAML - Real lmplementation: MAML走两步gradient,用第二步gradient去update参数Φ
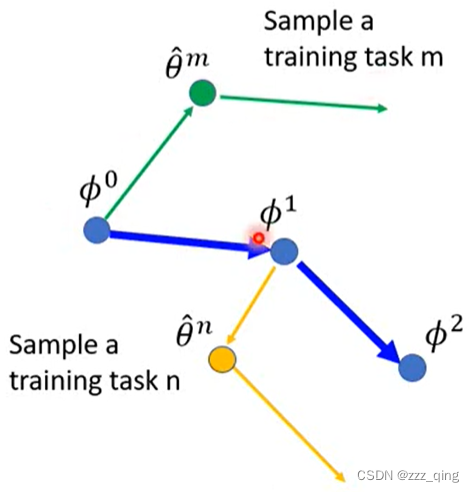
对比下pre-training:往当前Φ在training task上算出来的gradient方向移动
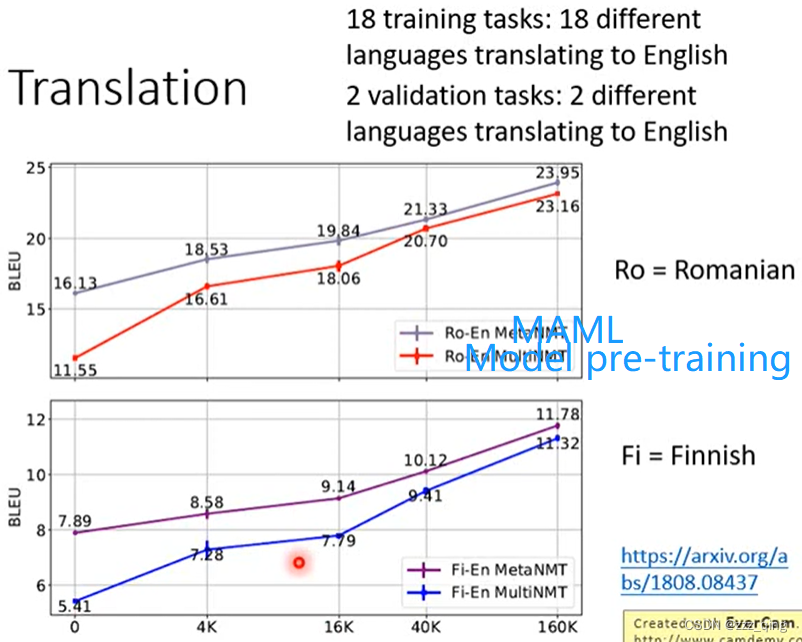
把MAML实作在translation的任务上,结果如下图。MAML比pre-training效果好,尤其是在训练资料量少的时候。
Reptile
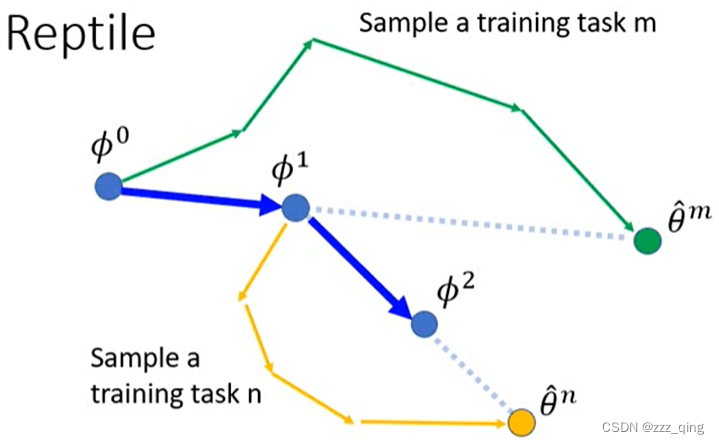
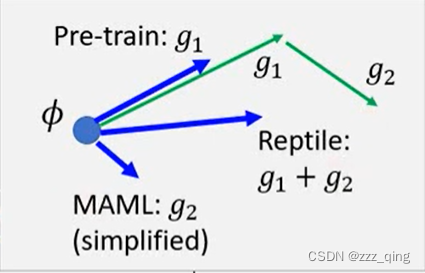
Reptile和MAML、pre-train的不同:
下图是Reptile、MAML、pre-train实作在Omniglot上的结果,可以看到meta learning的方法效果明显好于pre-train的方法:

Meta Learning – Gradient Descent as LSTM
Review Recurrent Neural Network:

Review LSTM:
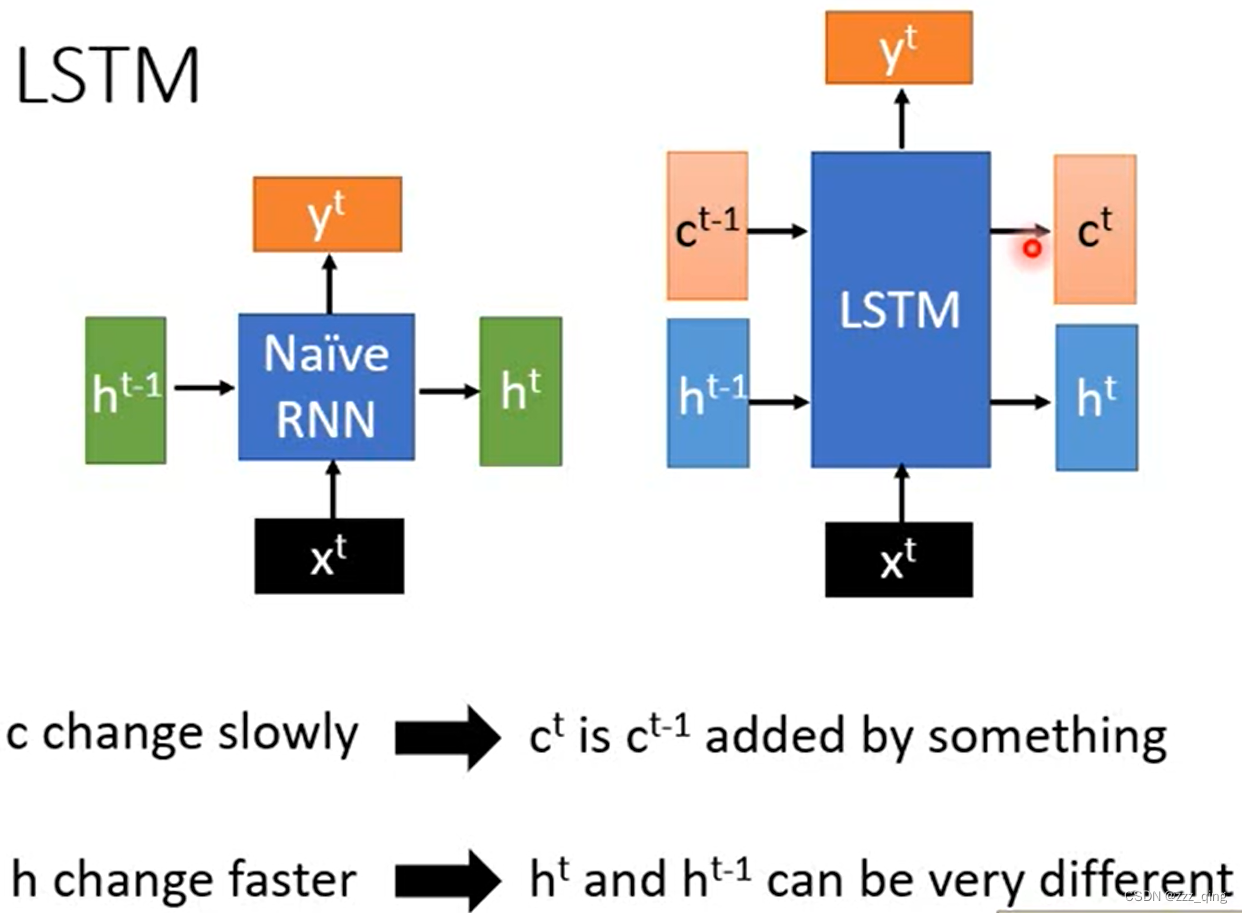
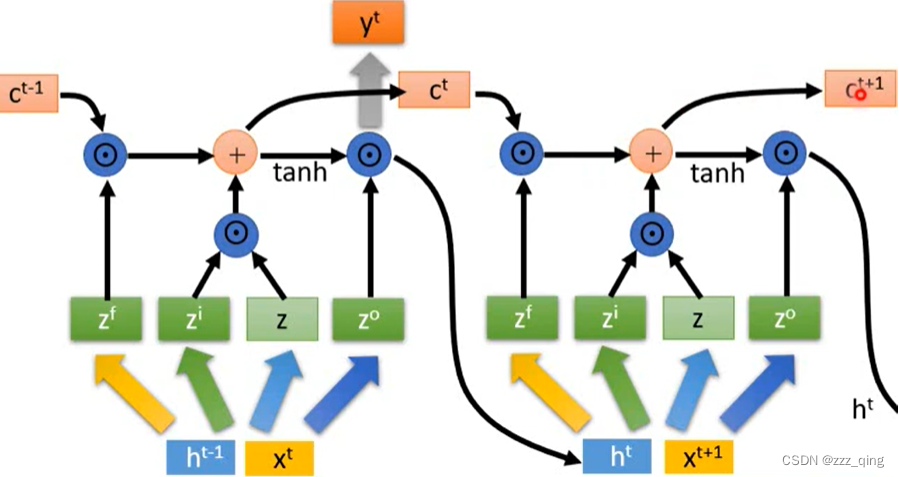
LSTM和gradient descent的式子有相似之处:
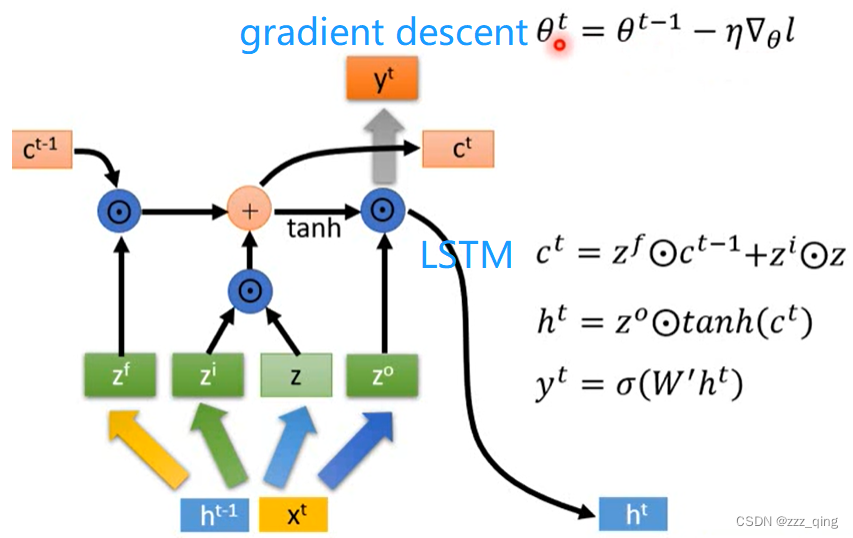
LSTM for Gradient Descent:
LSTM memory cell中的值,就是network的参数
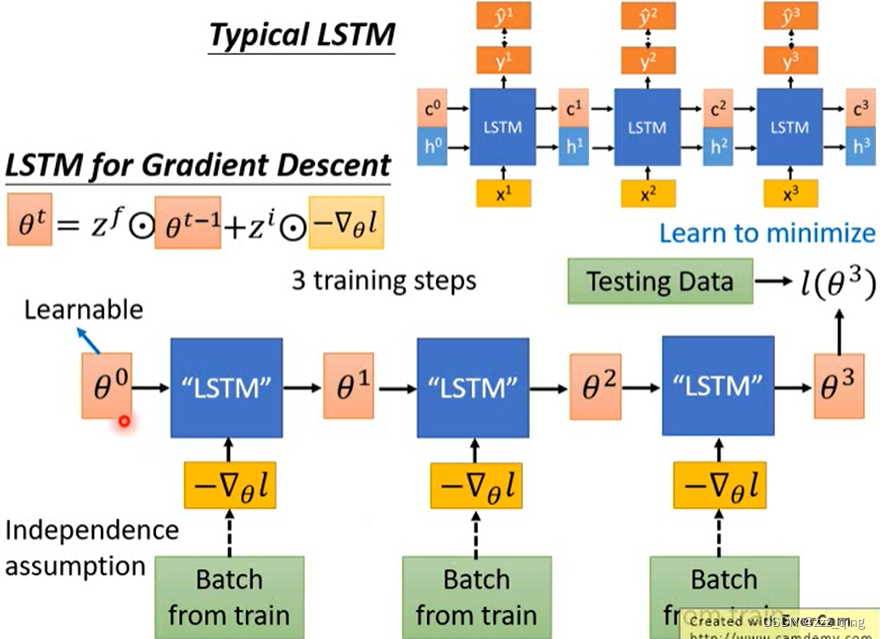
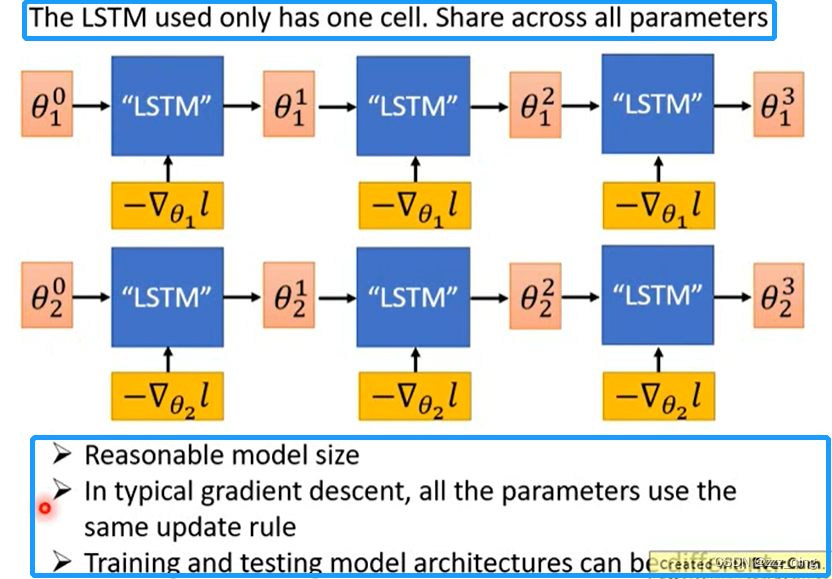
LSTM for Gradient Descent在实作上,因为LSTM的memory cell不可能开的太大(1024个memory cell就算比较多的了),而network的参数通常有几万到几十万个,所以在实作上LSTM只开一个cell,所有的network参数都通过相同的LSTM训练出来:
Meta Learning – Metric-based
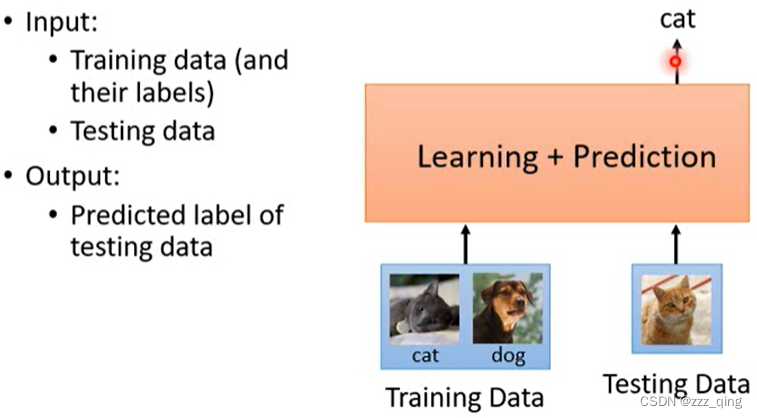
Metric-based是一个比较crazy的idea,它希望输入training data和testing data,能够直接输出predicted label of testing data:
后面都以Face Verification这个task为例,它是一个few-shot learning的task:
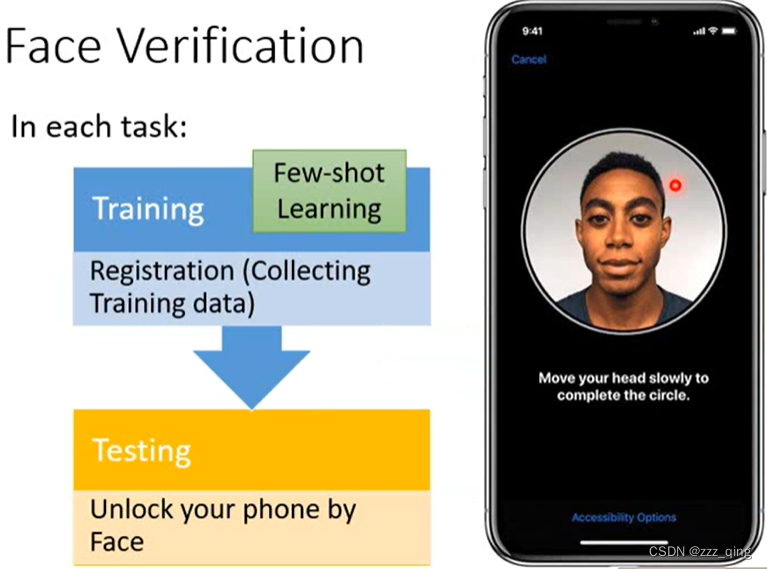
Face Verification可以当做一个meta learning的任务做:

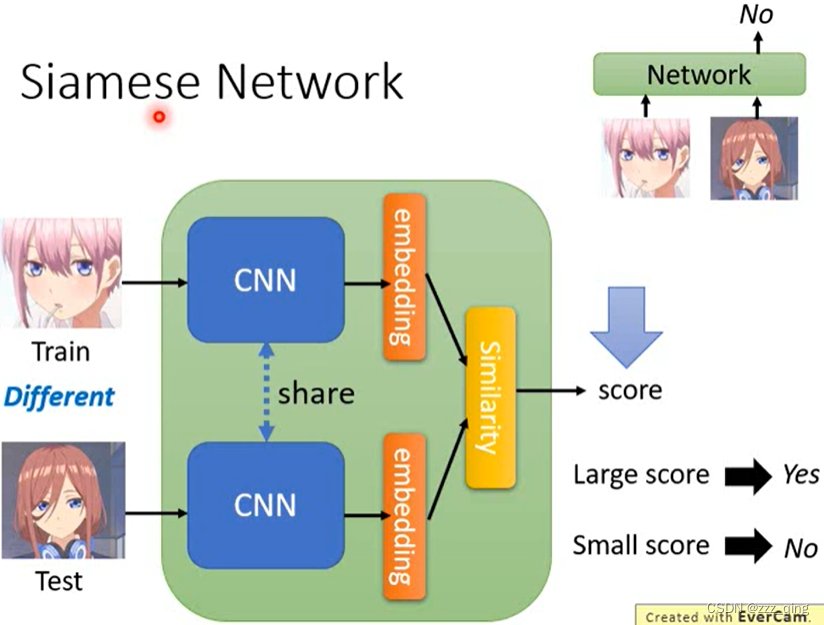
对于上面图片中的network,我们要训练这个network能够同时做训练和测试。实际上这个network的架构最常见的设计叫做Siamese Network(可以理解为孪生网络):
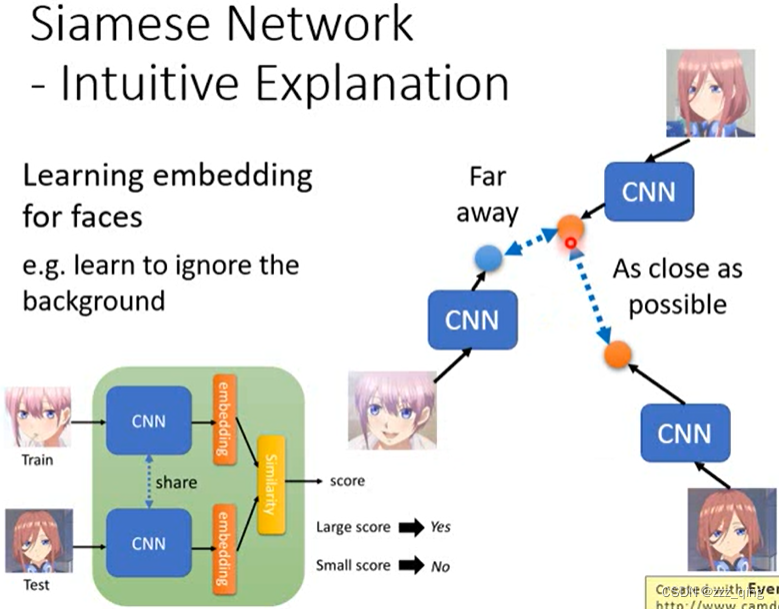
Siamese Network - Intuitive Explanation(当做一个binary classification的problem去理解)
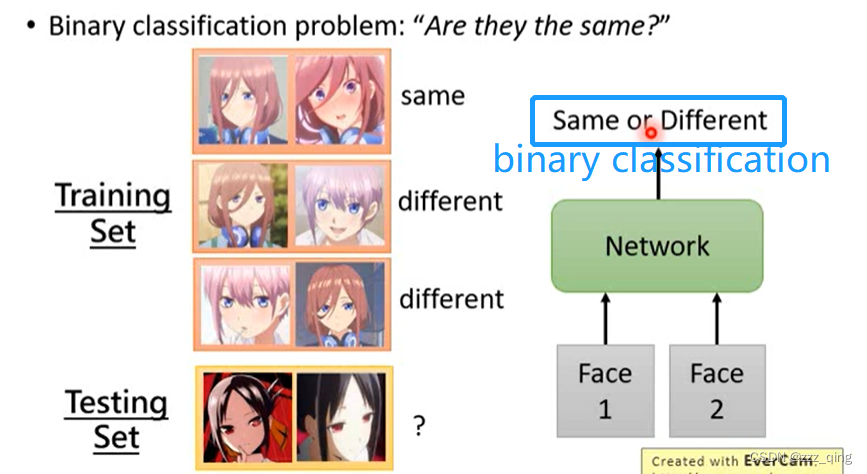
上面都是做的Verification的任务,即可以当成binary classification的任务,下面介绍如何做identification的任务,即N-way Few/One-shot Learning的任务。
N-way Few/One-shot Learning任务举例:
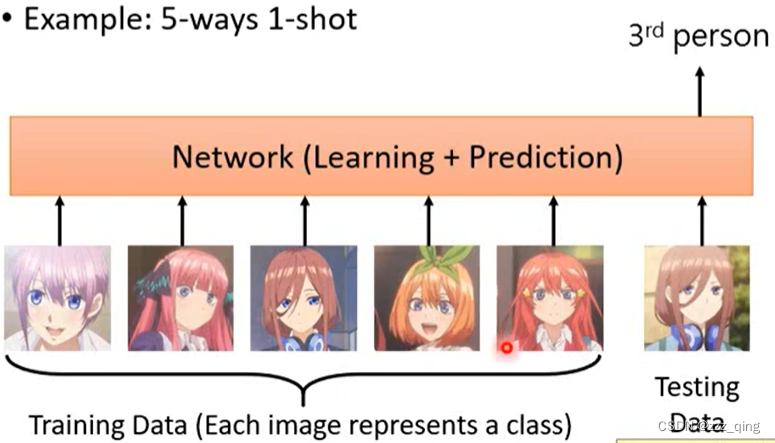
这种任务的network架构如何设计?下面给出三个文献上的做法:
① Prototypical Network
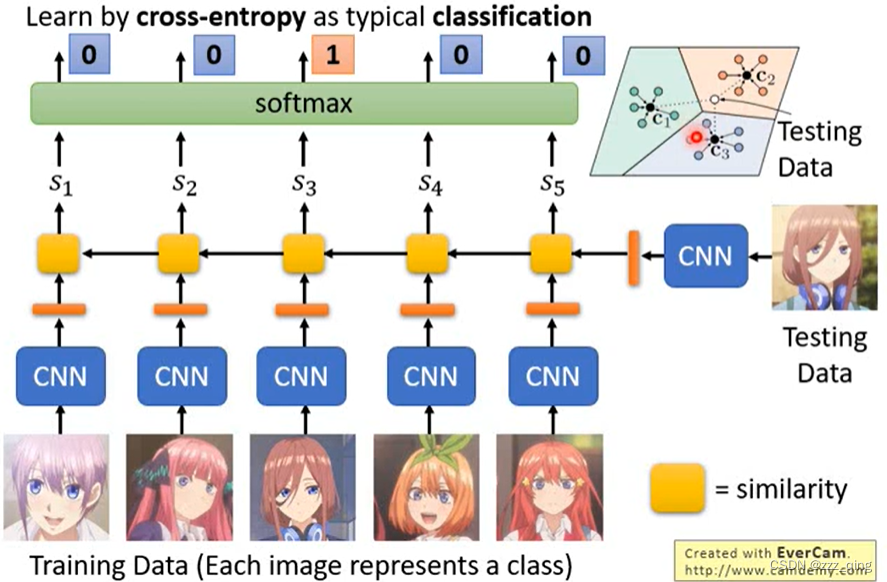
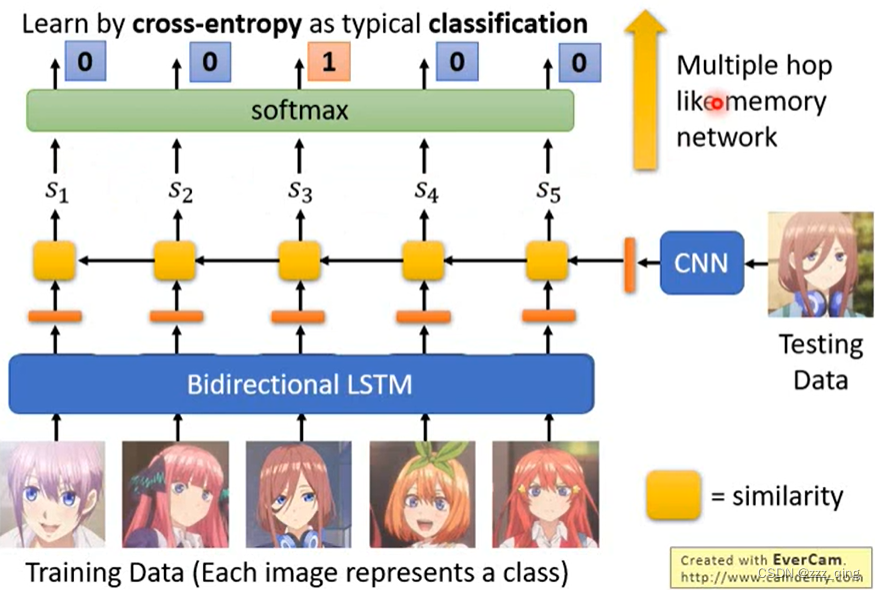
② Matching Network
这个network和Prototypical Network很类似,它们最大的区别在于Prototypical Network把training data的每一张图片都分开处理,Matching Network用一个bidirectional LSTM接收所有的training data。
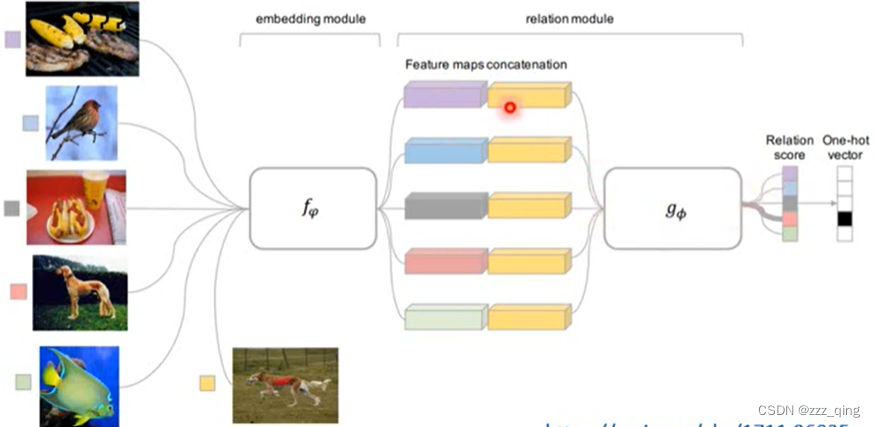
③ Relation Network
在few-shot learning中常常遇到的问题是训练资料很少,所以我们可以让机器去generate训练资料。generator是和network一起被learn出来的。
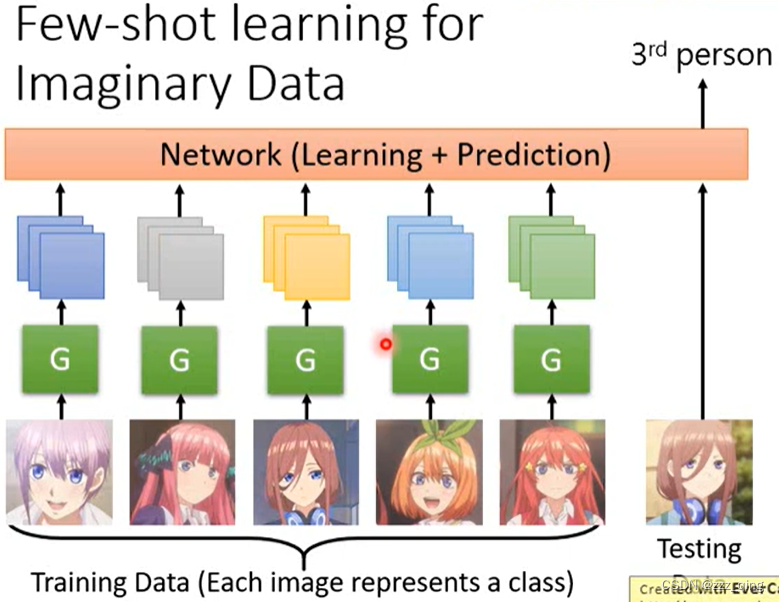
Meta Learning - Train+Test as RNN
在上面使用过的Metric-based approach的方法,使用的是专门设计过的network architecture。Can we use general network architecture?
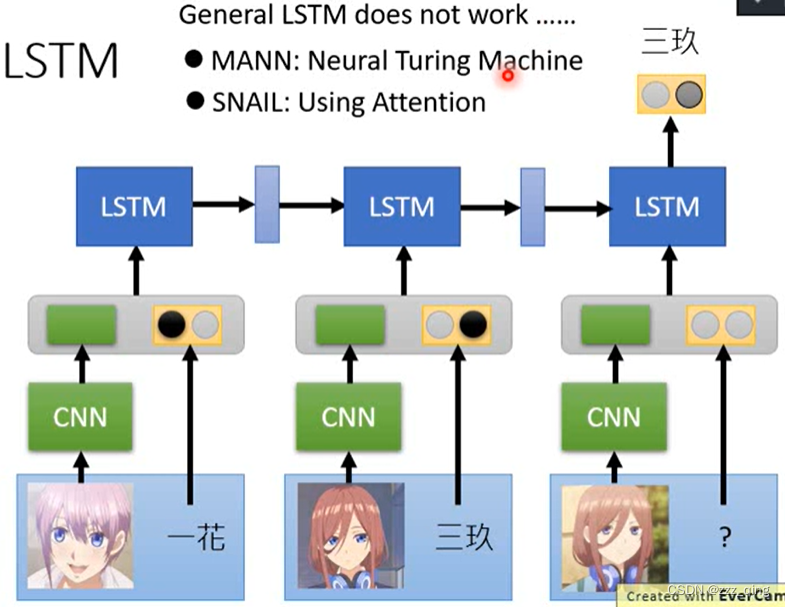
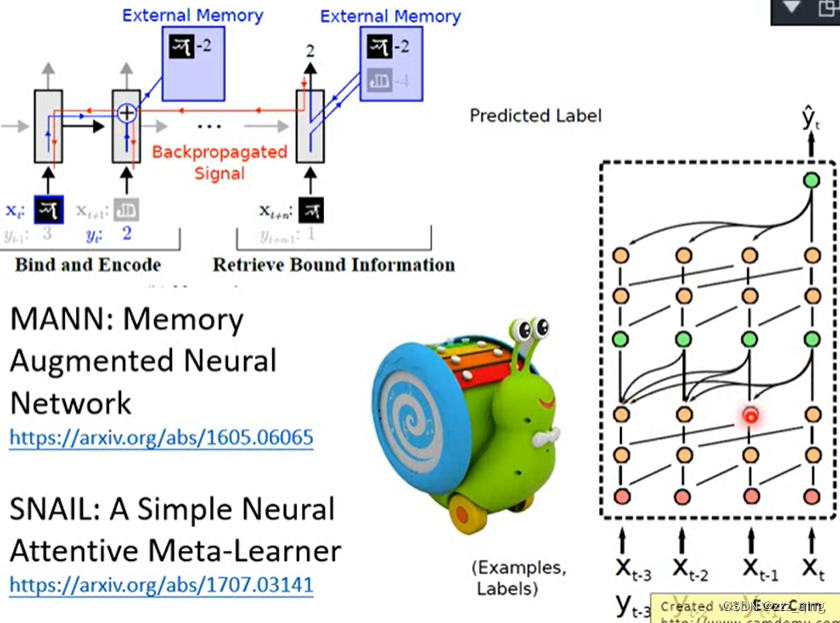
用一般的LSTM train不起来,修改LSTM架构(比较知名的有MANN、SNAIL)后可以train起来:
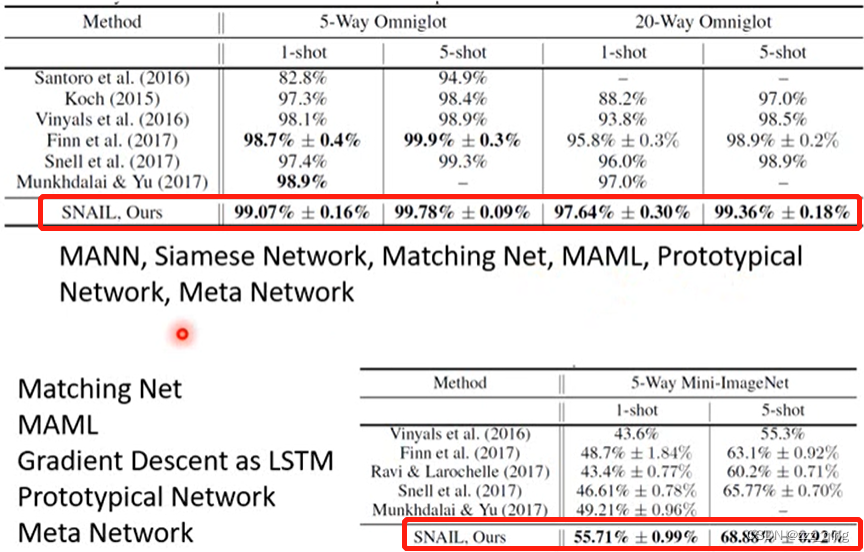
文献上结果表明SNAIL效果比较好:















 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









