



 GPT-4是一款强大的多模态语言模型,能处理文本和图片输入,展现出接近人类的表现。经过RLHF微调,其在专业基准测试中与人类表现相当。训练稳定性和可预测性增强,且在安全性方面有所提升,但仍有局限性。大语言模型如GPT-4将对工作场所产生重大影响,尤其在代码编写和批判性思考领域。
GPT-4是一款强大的多模态语言模型,能处理文本和图片输入,展现出接近人类的表现。经过RLHF微调,其在专业基准测试中与人类表现相当。训练稳定性和可预测性增强,且在安全性方面有所提升,但仍有局限性。大语言模型如GPT-4将对工作场所产生重大影响,尤其在代码编写和批判性思考领域。
导言
OpenAI发布的GPT4技术报告重点介绍了GPT4的能力有多么强大,以及安全方面的考虑,但是对训练和提升方法只字未提。Pytorch Lightning框架的创始人William Falcon说GPT-4的technical report其实就告诉大家We use python。
GPT-4和之前所有的模型都不一样的地方,是它可以接受图片作为输入,GPT-4可以允许用户去定义任何一个视觉或语言的任务。总的来说,GPT-4相比之前的GPT系列的模型,它的提升如下:
1. GPT-4是一个多模态模型,能接受文本/图片的输入,输出是纯文本。
2. GPT-4基本能达到类人的表象。
2. GPT-4在许多真实场景中不如人类强大,但在各种专业和学术基准测试中表现出与人类想当的性能。
3. GPT-4训练前所未有的稳定,可以准确地预测模型训练的结果(通过小规模训练的模型,准确预估大模型的结果,具体预测效果见图1)。
训练
GPT-4和之前的GPT模型一样,也是用预测文章中下一个词的方式去训练的。为了和人类的意图尽可能保持一致,用RLHF方法把模型微调了一下。
模型的能力看起来好像是从预训练的过程中得到的,后续的RLHF地微调并不能提高在考试上的成绩。模型的能力是靠堆数据、堆算力,然后用简单的language modeling loss。RLHF是用来对模型做控制,让模型更能知道我们的意图。
预测scaling
GPT-4模型关键问题是如何构建一个深度学习的infra,然后能准确地扩大上去。
Open AI研发出一套整体的infra和优化的方法,可以在多个尺度的实验上达到稳定的可以预测的行为,预测结果如下图。图一中,绿点是GPT-4,黑点是之前用较少算力训练的模型,横坐标是算力,可以通过较少算力的loss对GPT-4的loss做出精准的预测。
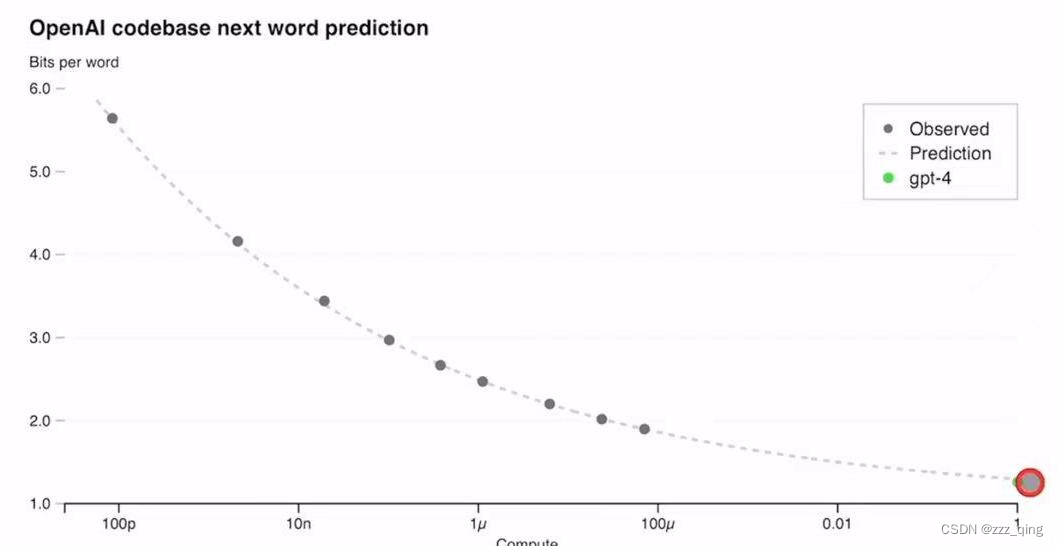 图1
图1
能力
在平常对话中,GPT3.5和GPT4区别非常小。区别随着任务难度的增加慢慢体现出来。GPT-4更加可靠,更加有创造力,能够处理更加细微的人类的指示。
1.测试GPT-4的考试能力,如下图:
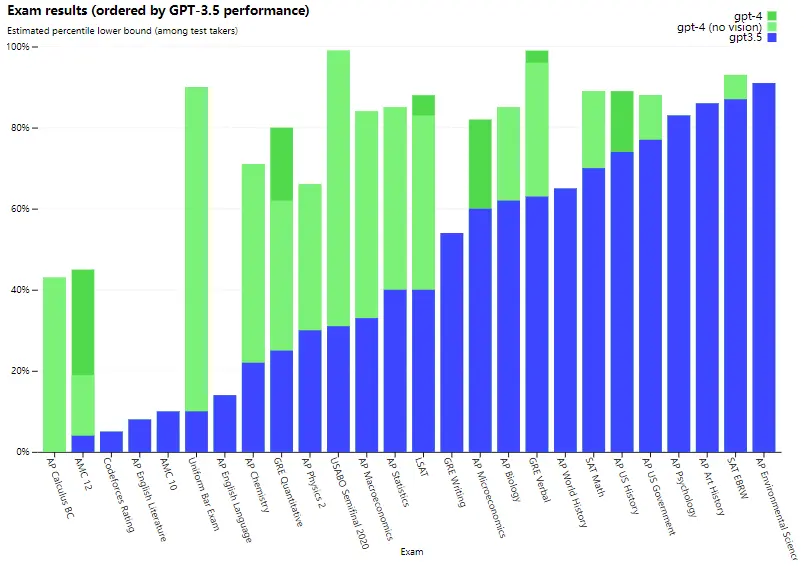
在一些GPT3.5表现很差的考试上,GPT-4进步显著。
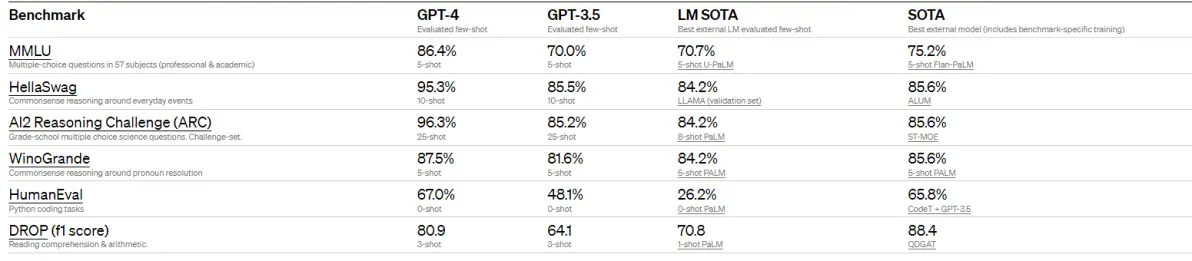
2.OpenAI在传统的Benchmark上测试GPT-4的性能,跟之前的language mode(GPT-3.5、LM SOTA、SOTA)相比全面碾压,测试结果如图:
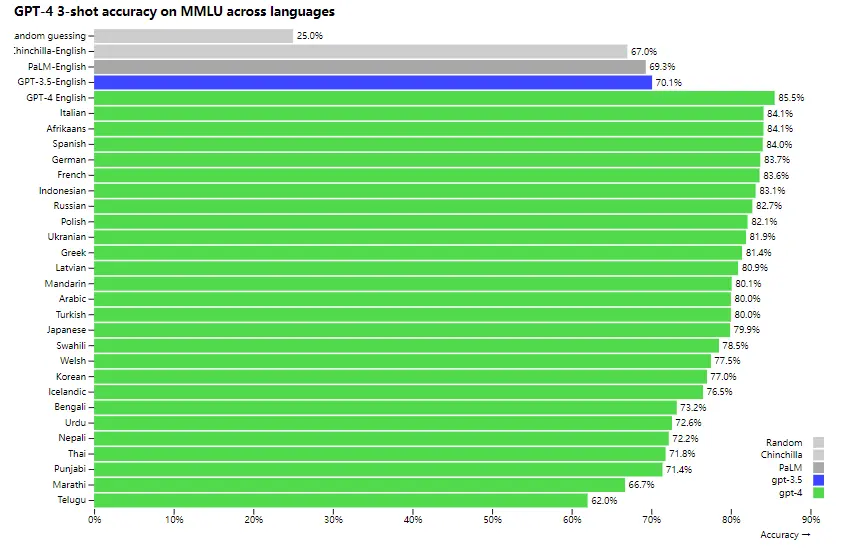
3.证明GPT-4在多语言上的能力,如图:
局限性
GPT-4和之前的GPT系列的模型还有外面的别的模型相比,安全性已经大幅提高,但还不是完全可靠。在内部对抗性事实评估中,GPT-4的得分比最新的GPT3.5高出40%。
危害
Red Teaming 利用人力、利用GPT-4自己去提升safety的要求,GPT-4比GPT-3.5能少回答82%的问题,采取的两个缓解措施具体如下
1. 找各领域专家进行对抗测试,希望让模型学会哪些该回答、哪些不该回答、拒绝不合理的要求。
2. 新增了安全方面的奖励分数,由模型的一个分类器提供,分类器用于评估提示词是否安全。很难保证模型不输出危险内容,但是判断模型输出是否危险是比较容易的。
影响
OpenAI和其他的研究者做了一个报告(arXiv:2303.10130),大概80%的美国的劳动力,他们平时工作中10%的任务会因为这个大语言模型的到来而受到影响。19%的工人会有50%的工作可能被影响。
大语言模型带来的影响和science以及critical thinking的技能反向相关。
而写代码、写文章这些技能点和大语言模型冲突。
Yann LeCun的报告中指出,现在的大语言模型还是有很多地方需要改进。大语言的性能非常amazing,但也会犯一些非常愚蠢的错误,而且大语言模型对真实世界一无所知。接下来的路怎么走,AGI到底怎么做,其实还是一个悬而未决的问题。对于NLP领域、CV领域研究的范式改变了,但research仍然可以继续做,现在正是一切的开始,作为相关领域的研究者,应该保持一颗平常心,坚持学习新技术并探索他们的改进方向。
本文根据B站GPT-4论文精读视频所写,B站视频链接如下:

















 6534
6534




 到【灌水乐园】发言
到【灌水乐园】发言







