






异构计算技术与DTK异构开发套件
费林分类法:SISD SIMD MISD MIMD
指令流I和数据流D
MIMD不同存储结构:
- UMA均匀存储访问模型
- NUMA非均匀存储访问模型
- Cluster集群
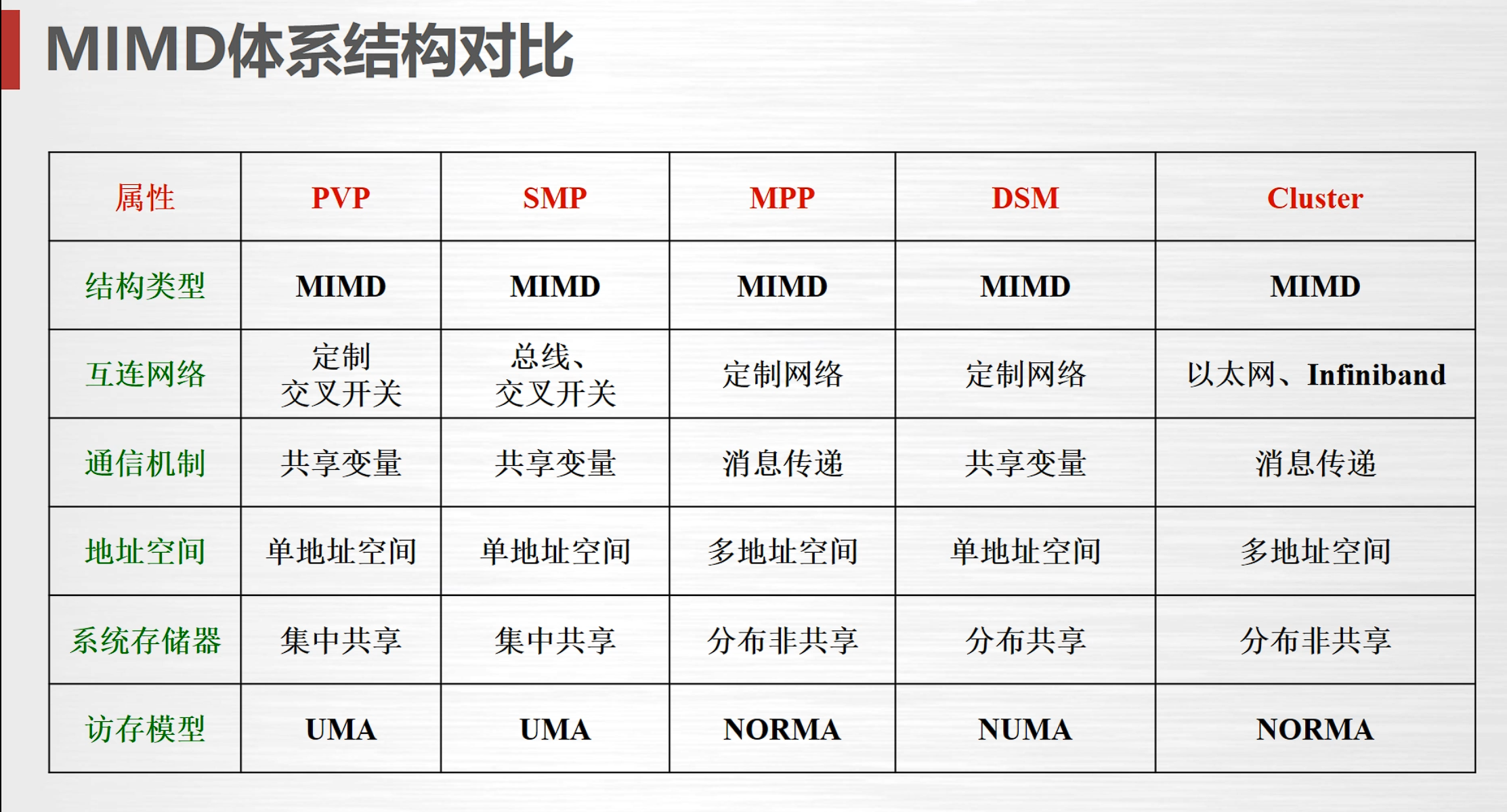
现在以Cluster为主
DTK异构开发套件
生态结构
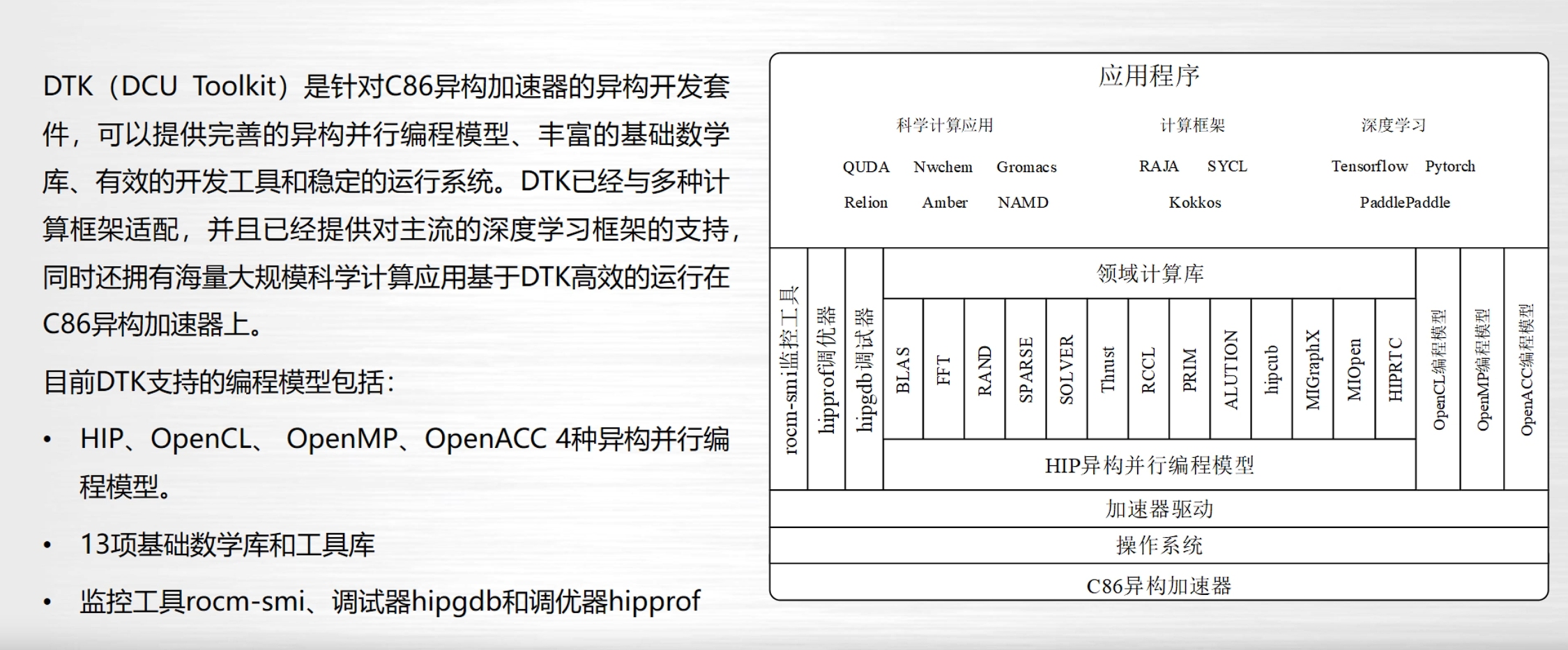
异构并行编程模型是什么
HIP(Heterogeneous-Compute Interface for Portability)
HIP是由AMD开发的一种编程模型,旨在提供跨AMD和NVIDIA GPU的可移植性。它允许开发者编写基于CUDA风格的代码,同时能够在不同厂商的GPU上运行。
- 特点:
- 类似CUDA的语法和编程风格,使得从CUDA到HIP的迁移相对容易。
- 支持AMD和NVIDIA的GPU,提供代码的跨平台可移植性。
- 提供高效的性能和低开销的API。
OpenCL(Open Computing Language)
OpenCL是由Khronos Group制定的一个开放标准,用于异构计算平台上的并行编程。它支持多种类型的计算设备,包括CPU、GPU、DSP等。
- 特点:
- 平台无关性,支持多种硬件厂商和设备类型。
- 基于C语言的编程模型,提供底层控制和优化能力。
- 支持任务并行和数据并行模型。
- 适用于广泛的应用领域,包括图像处理、机器学习和科学计算等。
OpenMP(Open Multi-Processing)
OpenMP是用于多平台共享内存并行编程的API,主要针对多核CPU系统。通过使用编译指令、库例程和环境变量,OpenMP允许程序员在现有的C、C++和Fortran代码中添加并行化支持。
- 特点:
- 使用简单,易于在现有代码中添加并行化支持。
- 提供线程级并行控制,适合共享内存多处理器系统。
- 支持循环并行化、任务并行和数据并行。
- 主要用于多核CPU环境,但也可以在一些GPU环境中使用。
OpenACC(Open Accelerators)
OpenACC是为异构计算设计的一种并行编程标准,旨在简化在CPU和GPU等加速器上开发并行程序的过程。通过添加编译指令,开发者可以快速将现有代码并行化。
- 特点:
- 易于使用,允许逐步并行化现有代码。
- 支持不同类型的加速器,包括GPU和其他专用硬件。
- 提供高级抽象,减少手工优化和设备特定代码的需求。
- 适用于科学计算、高性能计算等领域。
数学库
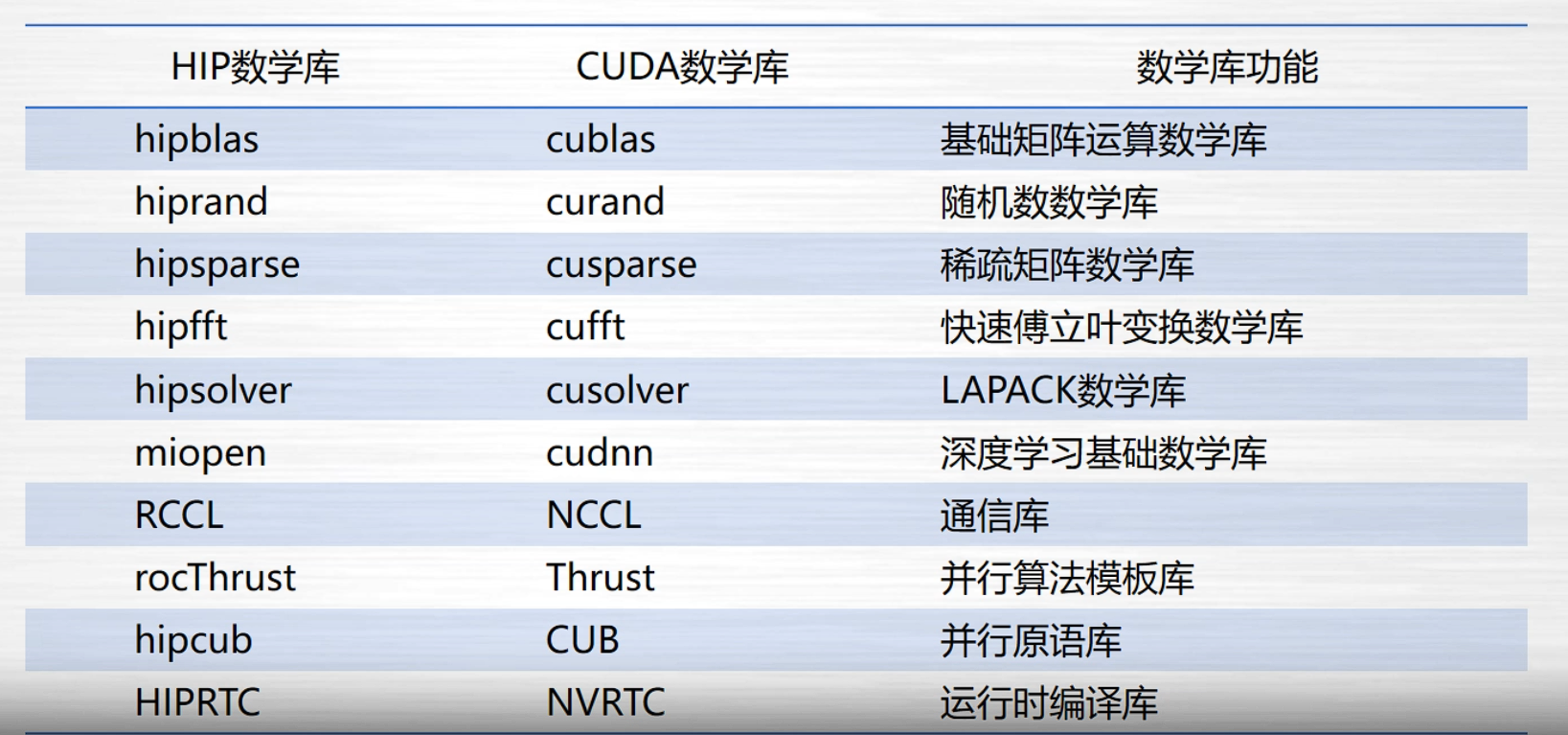
CUDA风格和HIP风格是什么
CUDA(Compute Unified Device Architecture)
CUDA是由NVIDIA开发的一种并行计算平台和编程模型,允许开发者利用NVIDIA GPU进行通用计算。CUDA提供了C/C++扩展,开发者可以编写在GPU上执行的内核函数(kernel)。
- 特点:
- 内核函数:使用
__global__修饰符定义的函数可以在GPU上执行。 - 线程和块:通过指定线程数和块数来管理并行执行,通常使用
<<<grid, block>>>语法。 - 内存管理:需要显式管理主机(CPU)和设备(GPU)之间的内存传输。
- 库支持:丰富的库和工具链,例如cuBLAS、cuFFT等。
- 专有性:专为NVIDIA GPU设计,不适用于其他GPU厂商。
- 内核函数:使用
HIP(Heterogeneous-Compute Interface for Portability)
HIP是由AMD开发的一种编程模型,旨在提供与CUDA兼容的代码,使得代码能够在AMD和NVIDIA的GPU上运行。HIP主要是为了解决跨平台的可移植性问题。
- 特点:
- 兼容性:HIP的语法和风格与CUDA非常相似,允许从CUDA代码到HIP代码的轻松迁移。
- 内核函数:使用
__global__修饰符定义的函数可以在GPU上执行,与CUDA相同。 - 线程和块:同样使用
<<<grid, block>>>语法来指定线程数和块数。 - 内存管理:与CUDA类似,需要管理主机和设备之间的内存传输。
- 可移植性:支持在AMD和NVIDIA的GPU上运行,提供跨平台的代码复用。
- 工具支持:提供hipify工具,可以自动将CUDA代码转换为HIP代码。


















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









