







目录
2.3.1 DCU软件栈(DCU ToolKit, DTK)
第三章内容请看:国产海光DCU&GPGPU异构编程实战(中)-CSDN博客
第四、五章内容请看:国产加速器海光DCU&GPGPU深算处理器异构编程实战(下)-CSDN博客
一、概述
本章节中,主要讲述了异构编程技术在科学计算领域中的应用,解释了为什么异构编程越来越受到重视以及学习异构编程的必要性。
1.1 处理器的异构化发展趋势
计算机系统的不断进步是人类最杰出的工程成就之一。现在人们手机的计算能力是阿波罗号使用的计算机能力的100万倍,达到这一个成就人类花费了50年的时间。其中这一演变的关键在于半导体行业的发展,以及它如何改进处理器的速度、功率和成本。
处理器是由晶体管组成的。晶体管是逻辑开关,用作从原始逻辑函数(如与、或、非)到复杂算术(浮点加法、正弦函数)、存储器(如 ROM、DRAM)等所有东西的构建模块。如果一个芯片上的晶体管越多,处理器的性能就越好,这就导致了后续的研究方向在如何将晶体管做的够小以及如何在有限的芯片面积上集成更多的晶体管。
1965 年,戈登 · 摩尔发现,集成电路中的晶体管数量每年翻一番。他预计这一趋势将持续至少十年。虽然有人认为,这与其说是一个定律,不如说是一个行业趋势,但它确实持续了大约 50 年,是历史上持续时间最长的人为趋势之一。但除了摩尔定律,还有一条不那么有名但同样重要的定律。它被称为登纳德缩放比例定律,由罗伯特 · 登纳德在 1974 年提出。虽然摩尔定律预测晶体管将逐年缩小,但登纳德问道:除了能够在单个芯片上安装更多晶体管之外,拥有更小的晶体管还有什么实际好处?他的观察结果是,当晶体管以 k 为倍数缩小时,电流也会降低。此外,由于电子移动的距离更小,我们最终得到的晶体管快了 k 倍,最重要的是——它的功率下降到 1/k^2。因此,总的来说,我们可以多装 k^2 个晶体管,逻辑函数将快大约 k 倍,但芯片的功耗不会增加。这50年中芯片在这两个定律的影响下性能按照预测不断的增长,这是一个美好的阶段。
不幸的是大约在 2000 年,登纳德缩放比例定律开始崩溃。具体来说,随着频率的提升,电压停止以相同的速率下降,功率密度速率也是如此。如果这种趋势持续下去,芯片发热问题将不容忽视。然而,强大的散热方案还不成熟。因此,供应商无法继续依靠提高 CPU 频率来获得更高的性能,需要想想其它出路例如多核心CPU。
单个应用是以连续指令流的形式编写的,如果CPU同时运行四个应用,理论上计算性能也能提升四倍。因此,解决方案不是加快单个处理器的速度,而是将芯片分成多个相同的处理内核,每个内核执行其指令流。多核执行的方式还常见于GPU 中,这是因为GPU当中拥有很多的简单计算核心(相比与CPU来说)。通常来讲,GPU 侧重于图形应用,因为图形图像(例如视频中的图像)由数千个像素组成,可以通过一系列简单且预先确定的计算来独立处理。从概念上来说,每个像素可以被分配一个线程,并执行一个简单的迷你程序来计算其行为(如颜色和亮度级别),每个线程可以单独放置在一个计算核心中运行。高度的像素级并行使得开发数千个处理内核变得很自然。
但是到了 2010 年前后,事情变得更加复杂:登纳德缩放比例定律走到了尽头,因为晶体管的电压接近物理极限,无法继续缩小。虽然以前可以在保持相同功率预算的情况下增加晶体管数量,但晶体管数量翻倍意味着功耗也翻倍。此时,我们的芯片上有多少晶体管并不重要只要有功耗限制,能够同时运行的晶体管数量是固定的,芯片的其余部分必须断电,这种现象也被称为暗硅。
暗硅本质上是摩尔定律终结的大预演——对处理器制造商来说,时代变得具有挑战性。一方面,计算需求飞速增长:智能手机变得无处不在,而且拥有强大的计算能力,云服务器需要处理越来越多的服务。另一方面,人工智能重新登上历史舞台,并以惊人的速度吞噬计算资源。暗硅成为晶体管芯片发展的障碍,因此,当我们比以往任何时候都更需要提高处理能力时,这件事却变得比以往任何时候都更加困难。
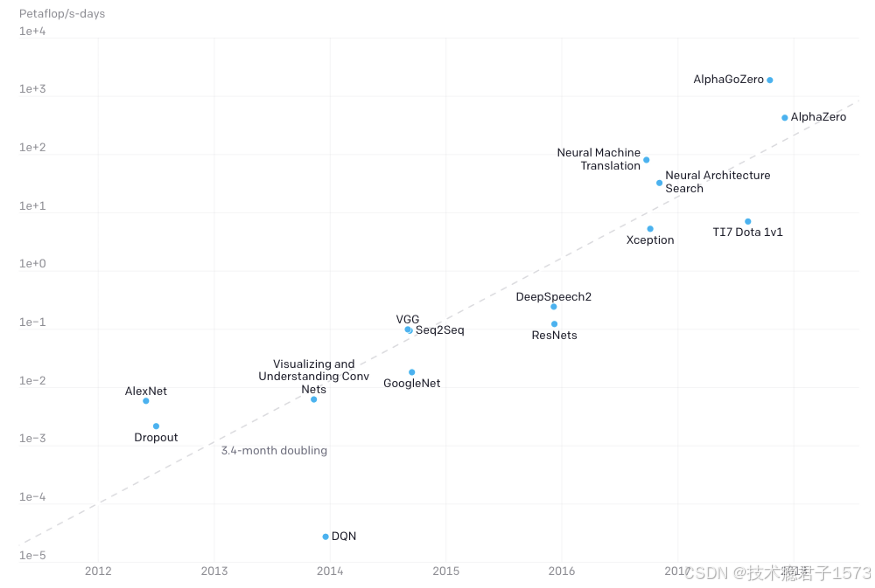
图 1-1 人工智能计算量
自从新一代芯片被暗硅束缚以来,计算机行业就开始把精力放到了硬件加速器上。他们的想法是:如果不能再增加晶体管,那就好好利用现有的晶体管吧。具体怎么做呢?答案是:专门化。
传统的 CPU 被设计成通用的,它们使用相同的硬件结构来运行我们所有应用。但是在图形处理中,计算问题往往是一些相似且简单的大量问题,如果把这些问题也放在CPU中会使得CPU应顾不暇,所以将特定的图形处理问题交给GPU来,让CPU去调配GPU来进行计算,CPU可以继续专注于自己擅长的事情。这种同时使用CPU和GPU的程序称为异构程序。
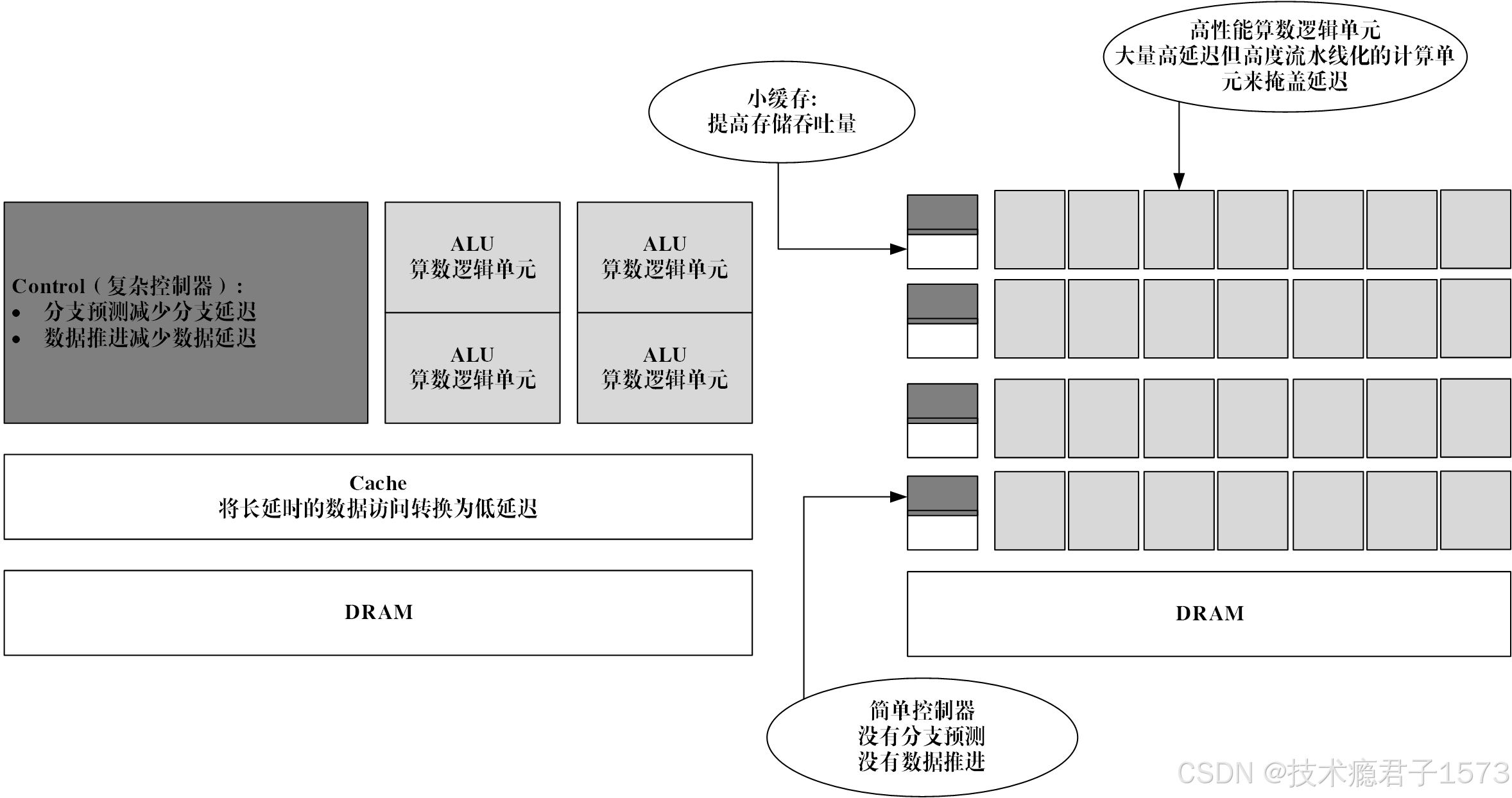
图 1-2 CPU和GPU硬件逻辑图
随着这种异构组合应用的不断发展,GPU从最早的图形处理设备,慢慢发展为通用的异构计算设备。从核心芯片的架构角度来看,CPU是以低延迟为导向的计算单元,通常由专为串行处理而优化的几个核心组成,而GPU是以吞吐量为导向的计算单元,由数以千计的更小、更高效的核心组成,专为并行多任务设计。CPU和GPU设计思路的不同导致微架构的不同。CPU的缓存大于GPU,但在线程数,寄存器数和SIMD(单指令多数据流)方面GPU远强于CPU。微架构的不同最终导致CPU中大部分的晶体管用于构建控制电路和缓存,只有少部分的晶体管完成实际的运算工作,其功能模块很多,擅长分支预测等复杂操作。GPU的流处理器和显存控制器占据了绝大部分晶体管,而控制器相对简单,擅长对大量数据进行简单操作,拥有远胜于CPU的强大浮点计算能力。因此,在相同的晶体管数量下,GPU相对CPU峰值会高一个量级以上,功耗与晶体管的数量成正比,因此GPU的性能功耗比也会比CPU高一个量级以上。因此,以GPGPU为主要计算部件的异构系统将会是解决功耗墙最好的方案。本文所介绍的DCU也是GPGPU计算部件中的一种,它具有与通用GPU类似的架构以及编程方法。
在DCU平台上,HIP是一个类似CUDA的显式异构编程模型。因此,非常有必要系统的学习如何在DCU上进行程序开发,以及如何将现有的应用程序按照计算机系统的发展方向进行改造和优化,提升应用性能,本书将会逐步展开相关内容的介绍。
1.2 异构计算与人工智能的发展
人工智能毫无疑问是当今科技领域最热门的技术之一,人工智能技术已经逐渐从实验室的研究走向了产业化,进入到了人们的日常生活中。继互联网和移动互联网引发第三次工业革命之后,以大数据驱动的人工智能技术正在推动第四次工业革命,这场技术革命的核心是网络化、信息化与智能化的深度融合,人工智能的时代正在到来。
人工智能的概念早在1956年提出,经历了孕育、形成和发展3个阶段。在人工智能出现至今经历过几次寒冬,自深度学习算法出现后,近几年进入了快速爆发期。1957年,罗森布拉特发明感知机,是机器学习人工神经网络理论中神经元的最早模型;1967年,计算机可以通过KNN最近邻算法进行简单的模式识别;当然在人工智能的起步期后段,由于计算能力的限制,进入了第一次寒冬。20世纪70年代中期开始,人工智能进入了以专家系统为代表的”知识期“,专家系统的能力来自于它们存储的专业知识,知识库系统和知识工程成为了80年代AI研究的主要方向,由于资源投入的缩减,知识获取困难和无法大规模扩展等因素,人工智能进入第二次低谷。之后人工智能进入了多元的发展周期,出现了决策树、Boosting和SVM等多种算法,1997年,IBM的计算机深蓝战胜了国际象棋世界冠军。从2006年神经网络专家Hinton提出神经网络深度学习算法之后,开启了深度学习在学术界和工业界的浪潮,例如无人驾驶汽车的上路、AlphaGo运用深度学习战胜围棋冠军和GPT3超大自然语言模型等等。
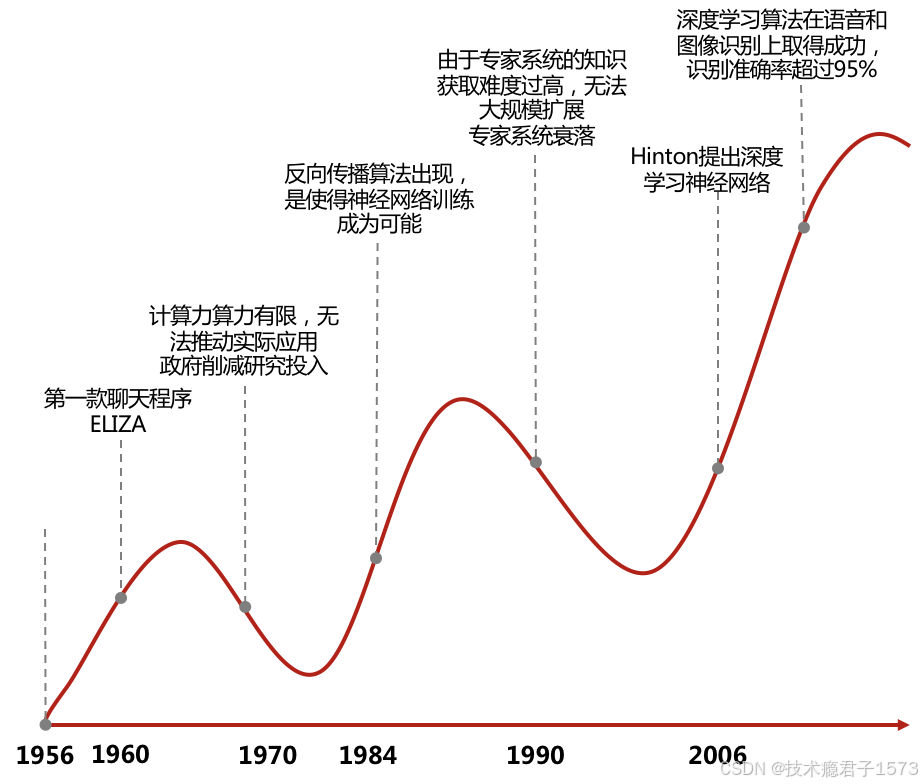
图 1-3 AI应用发展过程
近年来,人工智能的理论和技术都得到了飞速的发展,在视频监控、语音识别、图像分割、自然语言处理等领域都取得了突破,随着人工智能技术的发展,在国内,大批的高校、研究所和企业进入了智能化的浪潮中。中国科学院各大研究所以及清华大学等高校也都已经开始了人工智能相关学科的建设以及人才培养工作。智能驾驶、智能诊疗、智慧安防等领域已经逐渐进入到了人们的视野中,大量的智能化设备已经进入到了人们的生活中,大大提高了生活的便利性与舒适性。在新型冠状病毒抗疫过程中,人工智能技术在疫情的监控分析、药物筛选、防控救治等方面发挥了及其重要的作用。随着5G高速移动通信网络技术的发展,设备之间的互连将更迅速便捷,对自动驾驶、VR/AR等更多的人工智能应用的落地提供了技术保障。
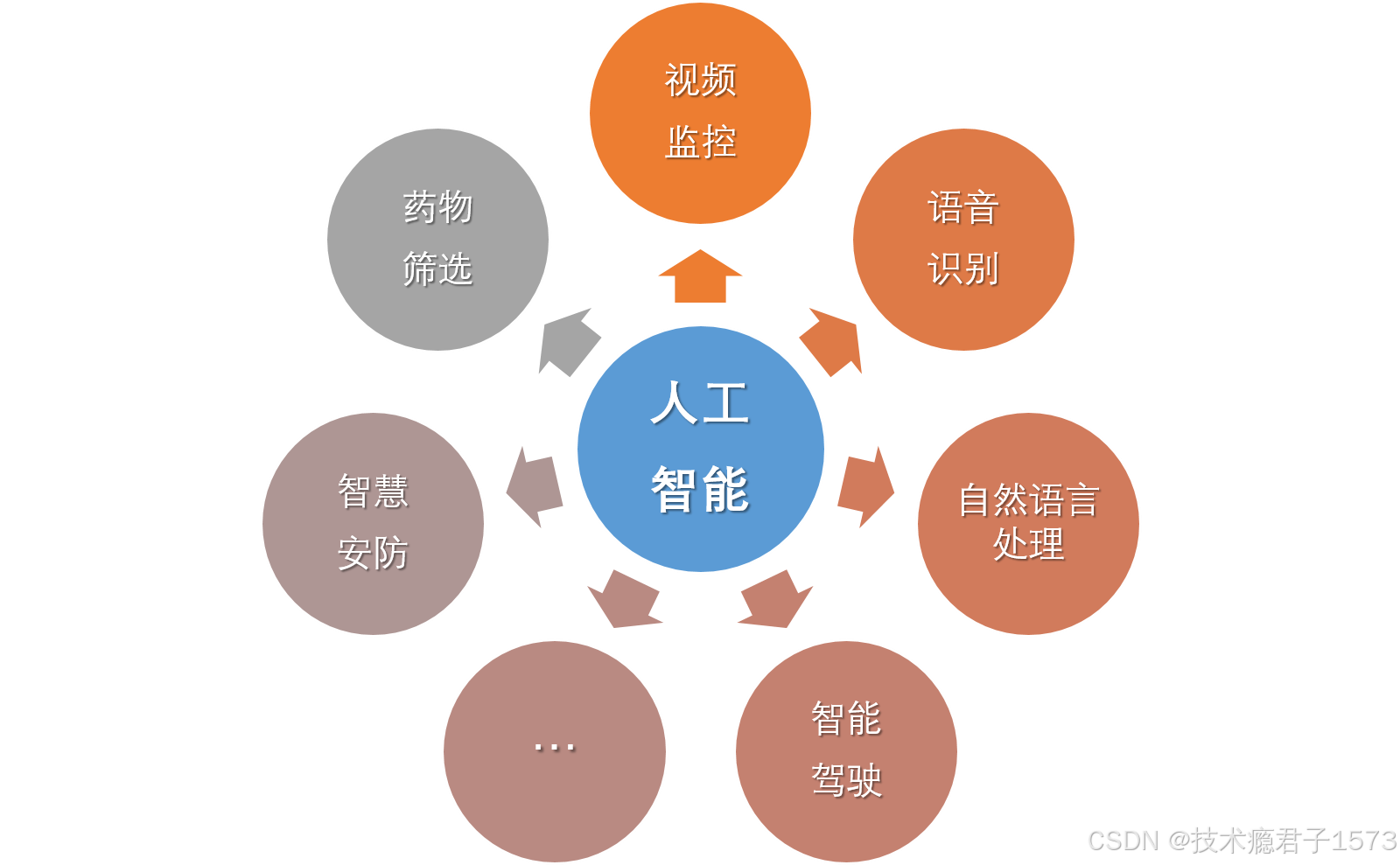
图 1-4 人工智能领域
人工智能的发展离不开三大驱动力,算法、算力以及数据,近些年出现了许多人工智能的颠覆性进展,北京智源人工智能研究院也对2020年的人工智能技术进行了总结,以OpenAI发布的全球最大的预训练模型GPT-3、DeepMind的AlphaFold2破解蛋白质结构预测问题、深度势能分子动力学研究获得戈登贝尔奖、DeepMind等在量子化学领域的发展、美国贝勒医学院通过动态颅内电刺激实现的高效“视皮层打印”、清华大学提出的类脑计算完备性概念及计算系统层次结构、北京大学实现的基于相变存储器的神经网络高速训练系统、MIT用19个类脑神经元实现控制自动驾驶汽车、Google和Facebook提出的SIMCLR和MoCo两个全新的无监督表征学习算法和康内尔大学提出可缓解检索排序马太效应问题的无偏公平排序模型作为最重要的十大技术进展。
目前人工智能技术已经从基于数据的联网时代、基于算力的云计算时代发展到了基于模型的AI时代,将数据进行深度挖掘提升为超大规模的预训练模型。国内在超大规模预训练模型上也启动了研发工作,以智源为代表的中文超大规模预训练预研模型文源、超大规模多
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3979
3979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











