








Matrix and Tensor Decomposition in RecommenderSystems
阅读笔记(翻译)
2.MATRIX DECOMPOSITION
矩阵分解(matrix factorization)是将一个矩阵分解为多个矩阵相乘结果的过程,它对发掘参与实体(participating entities, 如用户和商品)的数据中的潜在关系有着重要意义。在简化形式中,矩阵分解方法仅用两个矩阵,这两个矩阵各自包含了用户特征因素(user-feature factor)间的相关性(correlation)与商品特征因素(item-featurefactor)间的相关性。
为预测一个用户对一部电影的评分(rating),我们可以计算电影和用户在图上的坐标[x, y]间的点积(dot product)。
下面介绍基本矩阵分解方法。第一种方法为特征值分解(Eigenvalue Decomposition)。这种方法将原矩阵分解为矩阵的标准型(canonical form)。第二种方法为非负矩阵分解(Non-Negative MatrixFactorization, NMF)。这种方法将原矩阵分解为两个较小的矩阵,且每个小矩阵的每个元素都非负。第三种方法为概率矩阵分解(Probabilistic MatrixFactorization, PMF)。这种方法适用于大型数据集。PMF方法在用了球形高斯先验(spherical Gaussian priors)的高度稀疏(very sparse)和不均衡(imbalanced)数据集上表现较好。第四种方法为概率潜在语义分析(Probabilistic Latent Semantic Analysis, PLSA)。源于潜在类别模型(latentclass model)的混合分解(mixture decomposition)是该方法的基础。最后一种方法为CUR Decomposition。这种方法confronts the problemof density in the factorized matrices(a problem that is faced on SVD method)。我们还会详细描述SVD和UV分解。我们将用目标函数(objectivefunction)衡量预测值与用户真实评分之间的误差,并将其的最小化。另外,目标函数还被加入了友情的约束来平衡推荐的质量(additional constraint offriendship is added in the objective function to leverage the quality ofrecommendations)。
最后,我们对比了SVD和UV分解算法,对结合了SVD的CF算法的表现进行了研究。
3.TENSORDECOMPOSITION
由于在许多情况下,数据为三元关系(ternary relation)(如SocialTagging Systems(STSs), Location-based social network(LBSNs)),许多一开始被设计成针对矩阵的推荐算法无法应用。高阶问题成为新的挑战。比如,STSs的三元关系可以被表示为三阶张量
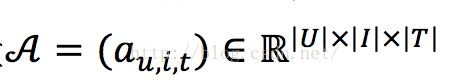
其中,
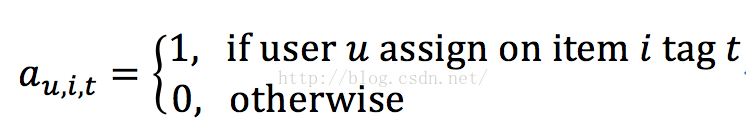
张量分解技术可被应用于发掘张量A中的潜在语义结构。基本的思想是将推荐问题转化成一个三阶张量完整化问题(third-order tensor completion problem)(通过预测A中为被观测到的实体)。
张量分解的第一种方法是Tucker 分解(TD)。这种方法是HOSVD的潜在张量分解模型(underlyingtensor factorization model)。TD将张量分解为一个矩阵集和一个小的core tensor。第二种方法为PARAFAC方法(PARAllelFACtor analysis),它和TD一样存在约束要求core tensor为对角的(diagonal)。第三种方法是PITF方法(PairwiseInteraction Tensor Factorization),它是TD的特例,在学习和预测上运行时间均为线性。第四种方法为低阶张量分解(Low-order Tensor Decomposition, LOTD)。
本文主要介绍的分解方法是高阶SVD(High OderSVD, HOSVD),它是SVD的延伸。特别的,我们会用一个小例子一步步来说明HOSVD的实现。然后,我们会说明当一个新的用户在我们的推荐系统注册时该如何更新HOSVD。我们还会讨论HOSVD如何与其他平衡推荐质量的方法相结合。最后,我们会提供在STSs的张量分解在真实数据集上的实验结果。我们还会讨论会用到的metric。我们的目标是说明影响算法效率的主要因素。
原文链接:http://dl.acm.org/citation.cfm?id=2959195
2.MATRIX DECOMPOSITION
矩阵分解(matrix factorization)是将一个矩阵分解为多个矩阵相乘结果的过程,它对发掘参与实体(participating entities, 如用户和商品)的数据中的潜在关系有着重要意义。在简化形式中,矩阵分解方法仅用两个矩阵,这两个矩阵各自包含了用户特征因素(user-feature factor)间的相关性(correlation)与商品特征因素(item-featurefactor)间的相关性。
为预测一个用户对一部电影的评分(rating),我们可以计算电影和用户在图上的坐标[x, y]间的点积(dot product)。
下面介绍基本矩阵分解方法。第一种方法为特征值分解(Eigenvalue Decomposition)。这种方法将原矩阵分解为矩阵的标准型(canonical form)。第二种方法为非负矩阵分解(Non-Negative MatrixFactorization, NMF)。这种方法将原矩阵分解为两个较小的矩阵,且每个小矩阵的每个元素都非负。第三种方法为概率矩阵分解(Probabilistic MatrixFactorization, PMF)。这种方法适用于大型数据集。PMF方法在用了球形高斯先验(spherical Gaussian priors)的高度稀疏(very sparse)和不均衡(imbalanced)数据集上表现较好。第四种方法为概率潜在语义分析(Probabilistic Latent Semantic Analysis, PLSA)。源于潜在类别模型(latentclass model)的混合分解(mixture decomposition)是该方法的基础。最后一种方法为CUR Decomposition。这种方法confronts the problemof density in the factorized matrices(a problem that is faced on SVD method)。我们还会详细描述SVD和UV分解。我们将用目标函数(objectivefunction)衡量预测值与用户真实评分之间的误差,并将其的最小化。另外,目标函数还被加入了友情的约束来平衡推荐的质量(additional constraint offriendship is added in the objective function to leverage the quality ofrecommendations)。
最后,我们对比了SVD和UV分解算法,对结合了SVD的CF算法的表现进行了研究。
3.TENSORDECOMPOSITION
由于在许多情况下,数据为三元关系(ternary relation)(如SocialTagging Systems(STSs), Location-based social network(LBSNs)),许多一开始被设计成针对矩阵的推荐算法无法应用。高阶问题成为新的挑战。比如,STSs的三元关系可以被表示为三阶张量
张量分解的第一种方法是Tucker 分解(TD)。这种方法是HOSVD的潜在张量分解模型(underlyingtensor factorization model)。TD将张量分解为一个矩阵集和一个小的core tensor。第二种方法为PARAFAC方法(PARAllelFACtor analysis),它和TD一样存在约束要求core tensor为对角的(diagonal)。第三种方法是PITF方法(PairwiseInteraction Tensor Factorization),它是TD的特例,在学习和预测上运行时间均为线性。第四种方法为低阶张量分解(Low-order Tensor Decomposition, LOTD)。
本文主要介绍的分解方法是高阶SVD(High OderSVD, HOSVD),它是SVD的延伸。特别的,我们会用一个小例子一步步来说明HOSVD的实现。然后,我们会说明当一个新的用户在我们的推荐系统注册时该如何更新HOSVD。我们还会讨论HOSVD如何与其他平衡推荐质量的方法相结合。最后,我们会提供在STSs的张量分解在真实数据集上的实验结果。我们还会讨论会用到的metric。我们的目标是说明影响算法效率的主要因素。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









