






背景
最近一段时间微信公众号得到了众多网友的留言,微信编辑部的小编们欣喜若狂,在此感谢各位小伙伴们的厚爱。为了与大家进行互动交流,小编认真地查看每一条小伙伴们的留言,有问Fiddler抓包工具的问题,有问自动化selenium的问题,当然还有问小剪子去哪儿了,O(∩_∩)O~。小编决定这期的文章挑一个自动化方面大家都比较关心的问题进行解答:
问: Python 获取到Excel一列值后怎么用selenium录制的脚本中参数化,比如对登录用户名和密码如何做参数化?
答:可以使用xlrd读取Excel的内容进行参数化。当然为了便于各位小伙伴们详细的了解,小编一一介绍具体的方法。
Selenium的环境准备:
1.安装Java
2.安装Python2.7
3.安装pip
4.通过pip安装selenium
5.下载Selenium服务端并运行
搜狗测试公众号之前分享过类似内容,同时网上也有比较详细的教程,所以略过。如果小伙伴们不了解此处的内容,建议参考(http://www.cnblogs.com/fnng/archive/2013/05/29/3106515.html)
编写登录用例:
- Step1:访问http://www.effevo.com (打个广告effevo是搜狗自研发的项目管理系统,完全免费,非常好用)
- Step2:点击页面右上角的登录
- Step3:输入用户名和密码后登录
- Step4:检查右上角的头像是否存在
实现代码:
# encoding: utf-8
'''
Created on 2016年5月4日
@author: Dongming
'''
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
import time
browser = webdriver.Firefox()
browser.get("http://www.effevo.com")
assert "effevo" in browser.title
#点击登录按钮
browser.find_element_by_xpath(".//*[@id='home']/div/div[2]/header/nav/div[3]/ul/li[2]/a").click()
time.sleep(1)
browser.find_element_by_id('passname').send_keys('selenium0012@126.com')
browser.find_element_by_id('password').send_keys('test1234')
browser.find_element_by_xpath(".//*[@id='content']/div/div[6]/input").click()
time.sleep(2)
try:
elem = browser.find_element_by_xpath(".//*[@id='ee-header']/div/div/div/ul[2]/li/a/img")
except NoSuchElementException:
#if elem == None:
assert 0 , u"登录失败,找不到右上角头像"
browser.close()制作Excel文件:
下一步,我们要对以上输入的用户名和密码进行参数化,使得这些数据读取自Excel文件。我们将Excel文件命名为data.xlsx,其中有两列数据,第一列为username,第二列为password。
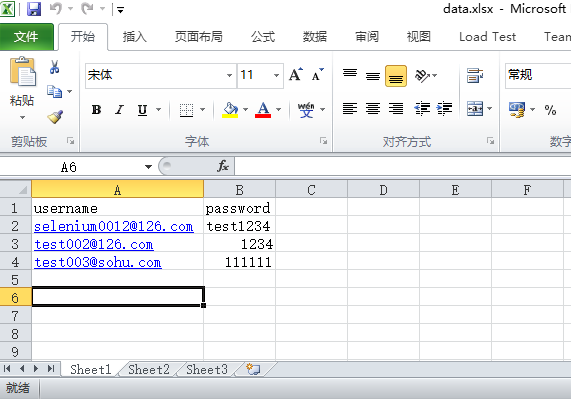
安装xlrd第三方库
Python读取Excel文件需要使用第三方的库文件xlrd,我们到python官网下载http://pypi.python.org/pypi/xlrd模块安装。
1.下载xlrd-0.9.4.tar.gz
2.解压该文件。由于该文件是用tar命令压缩的,所以建议windows用户用7zip解压,解压后内容如下:
3.命令行运行Setup.py文件:setup.py install
4.提示安装完毕后,我们就可以在python脚本中import xlrd了。
xlrd读取Excel文件:
xlrd库文件操作Excel的几个重要函数是
data = xlrd.open_workbook('excelFile.xls') #打开Excel文件读取数据
table = data.sheets()[0] #通过索引顺序获取获取一个工作表
table.row_values(i) # 获取整行的值(数组)
nrows = table.nrows #获取行数为了方便使用,我们把以上用到的函数封装为excel_table_byindex()函数。
实现代码:
import xlrd
def open_excel(file= 'file.xls'):
try:
data = xlrd.open_workbook(file)
return data
except Exception,e:
print str(e)
#根据索引获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的所以 ,by_index:表的索引
def excel_table_byindex(file= 'file.xls',colnameindex=0,by_index=0):
data = open_excel(file)
table = data.sheets()[by_index]
nrows = table.nrows #行数
colnames = table.row_values(colnameindex) #某一行数据
list =[]
for rownum in range(1,nrows):
row = table.row_values(rownum)
if row:
app = {}
for i in range(len(colnames)):
app[colnames[i]] = row[i]
list.append(app)
return list Excel数据参数化:
# encoding: utf-8
'''
Created on 2016年5月4日
@author: Dongming
'''
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
import time
import xlrd
#import xdrlib ,sys
def open_excel(file= 'file.xls'):
try:
data = xlrd.open_workbook(file)
return data
except Exception,e:
print str(e)
#根据索引获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的所以 ,by_index:表的索引
def excel_table_byindex(file= 'file.xls',colnameindex=0,by_index=0):
data = open_excel(file)
table = data.sheets()[by_index]
nrows = table.nrows #行数
colnames = table.row_values(colnameindex) #某一行数据
list =[]
for rownum in range(1,nrows):
row = table.row_values(rownum)
if row:
app = {}
for i in range(len(colnames)):
app[colnames[i]] = row[i]
list.append(app)
return list
def Login():
listdata = excel_table_byindex("E:\\data.xlsx" , 0)
if (len(listdata) <= 0 ):
assert 0 , u"Excel数据异常"
for i in range(0 , len(listdata) ):
browser = webdriver.Firefox()
browser.get("http://www.effevo.com")
assert "effevo" in browser.title
#点击登录按钮
browser.find_element_by_xpath(".//*[@id='home']/div/div[2]/header/nav/div[3]/ul/li[2]/a").click()
time.sleep(1)
browser.find_element_by_id('passname').send_keys(listdata[i]['username'])
browser.find_element_by_id('password').send_keys(listdata[i]['password'])
browser.find_element_by_xpath(".//*[@id='content']/div/div[6]/input").click()
time.sleep(2)
try:
elem = browser.find_element_by_xpath(".//*[@id='ee-header']/div/div/div/ul[2]/li/a/img")
except NoSuchElementException:
assert 0 , u"登录失败,找不到右上角头像"
browser.close()
if __name__ == '__main__':
Login()















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









