







前言
本章我们将通过 LLaMA-Factory 具体实践大模型训练的三个阶段,包括:预训练、监督微调和偏好纠正。
大模型训练回顾
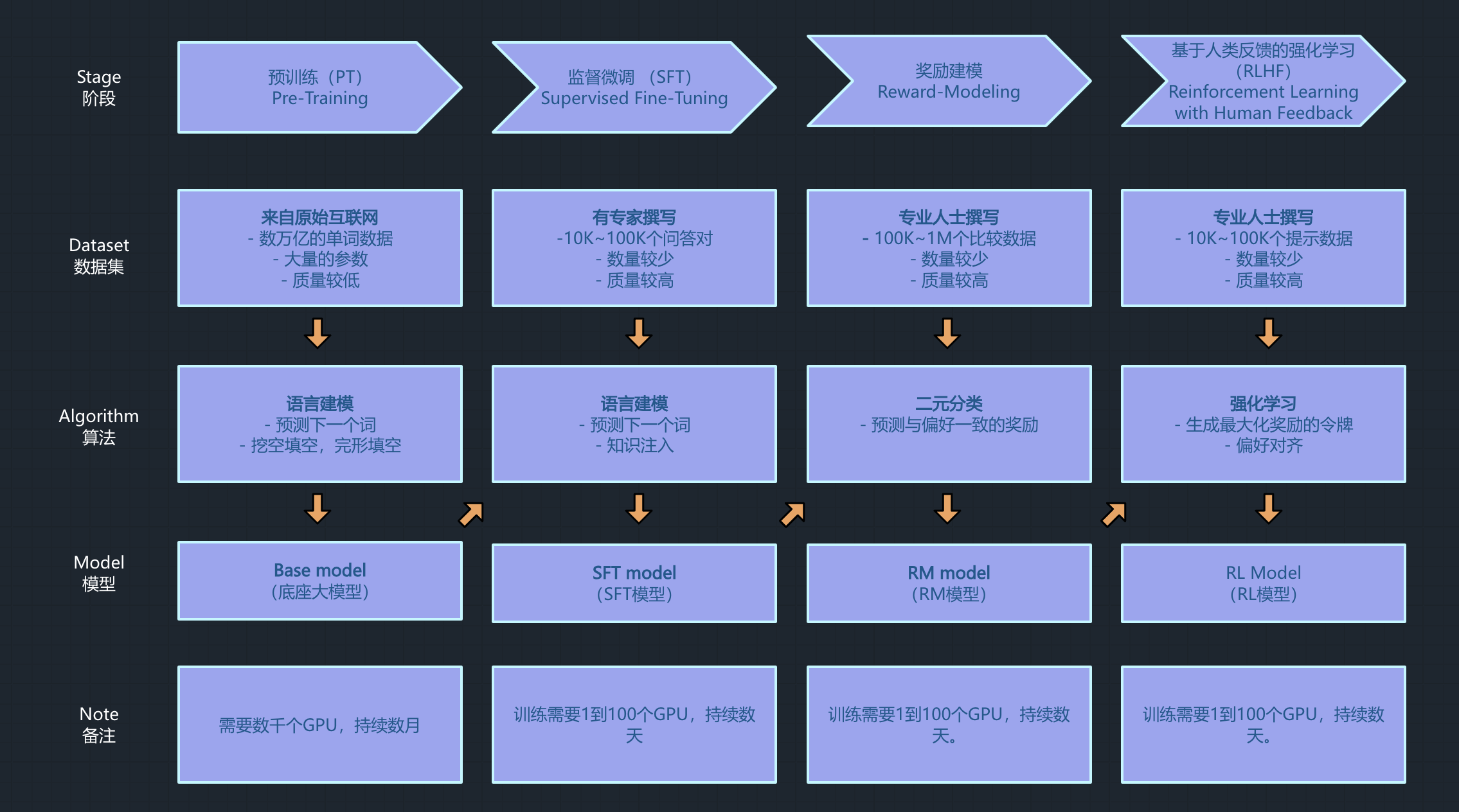
训练目标
训练一个医疗大模型
训练过程实施
准备训练框架
LLaMA Factory是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过Web UI界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架,GitHub星标超过2万。
运行环境要求
- 硬件:
- GPU:推荐使用24GB显存的显卡或者更高配置
- 软件:
- python:3.10
- pytorch:2.1.2 + cuda12.1
- 操作系统:Ubuntu 22.04
推荐选择DSW官方镜像:
modelscope:1.14.0-pytorch2.1.2-gpu-py310-cu121-ubuntu22.04
下载训练框架
第一步:登录ModelScope平台,启动PAI-DSW的GPU环境,并进入容器。
第二步:在容器中,通过命令行拉取代码。
# 拉取代码
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
# 进入代码目录
cd LLaMA-Factory
# 安装依赖
pip install -e ".[torch,metrics]"
第三步:检查环境是否安装成功。
llamafactory-cli version
正常安装成功显示如下:

- 如果安装不成功,需要根据提示信息进行逐个问题解决。
- 一般情况下,在ModelScope平台中,一般会出现
Keras版本不匹配的问题,可以运行pip install tf-keras解决。
第四步:进行端口映射命令
由于阿里云平台的端口映射似乎存在问题,这会导致启动LLaMA Factory的Web界面显示异常,所以需要手动在命令行运行如下命令:
export GRADIO_SERVER_PORT=7860 GRADIO_ROOT_PATH=/${JUPYTER_NAME}/proxy/7860/
第五步:命令行下运行命令,启动WebUI界面
llamafactory-cli webui
启动后,点击返回信息中的http://0.0.0.0:7860,可以看到Web界面。
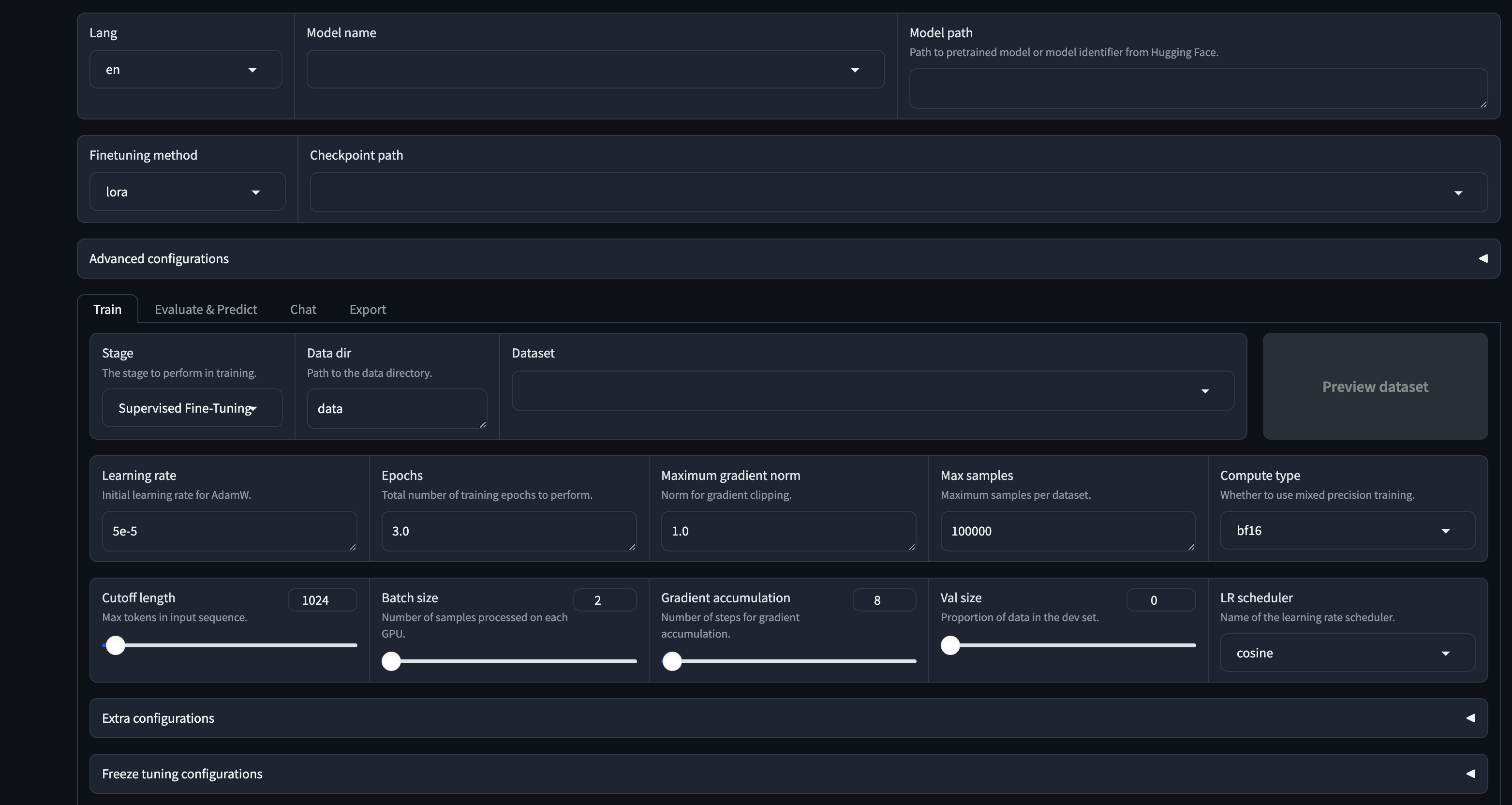
准备训练模型
选择模型
在开展大模型训练之前,由于我们不能从零开始训练一个大模型(时间及资源都不允许!),所以我们需要选择一个已经训练好的模型,作为基础模型进行训练。
在ModelScope平台,我们选择Qwen2-0.5B模型作为底座模型。
下载模型
第一步:拉取代码
git clone https://www.modelscope.cn/qwen/Qwen2-0.5B.git
第二步:在LLaMA-Factory下创建models目录,方便后续模型都维护在该目录下。
第三步:移动模型目录到LLaMA-Factory的models目录下。
LLaMA-Factory/
|-models/
|-Qwen2-0.5B/
验证模型
第一步:在LLaMA-Factory的WebUI界面,进行相关配置。
- Model name:
Qwen2-0.5B - Model path:
models/Qwen2-0.5B
models/Qwen2-0.5B对应下载模型第三步中的路径。由于Linux系统是大小写敏感,所以需要特别注意页面配置路径与实际路径大小写要保持一致。
第二步:切换Tab为 Chat , 点击 Load model按钮。
模型加载成功后,会显示如下界面。
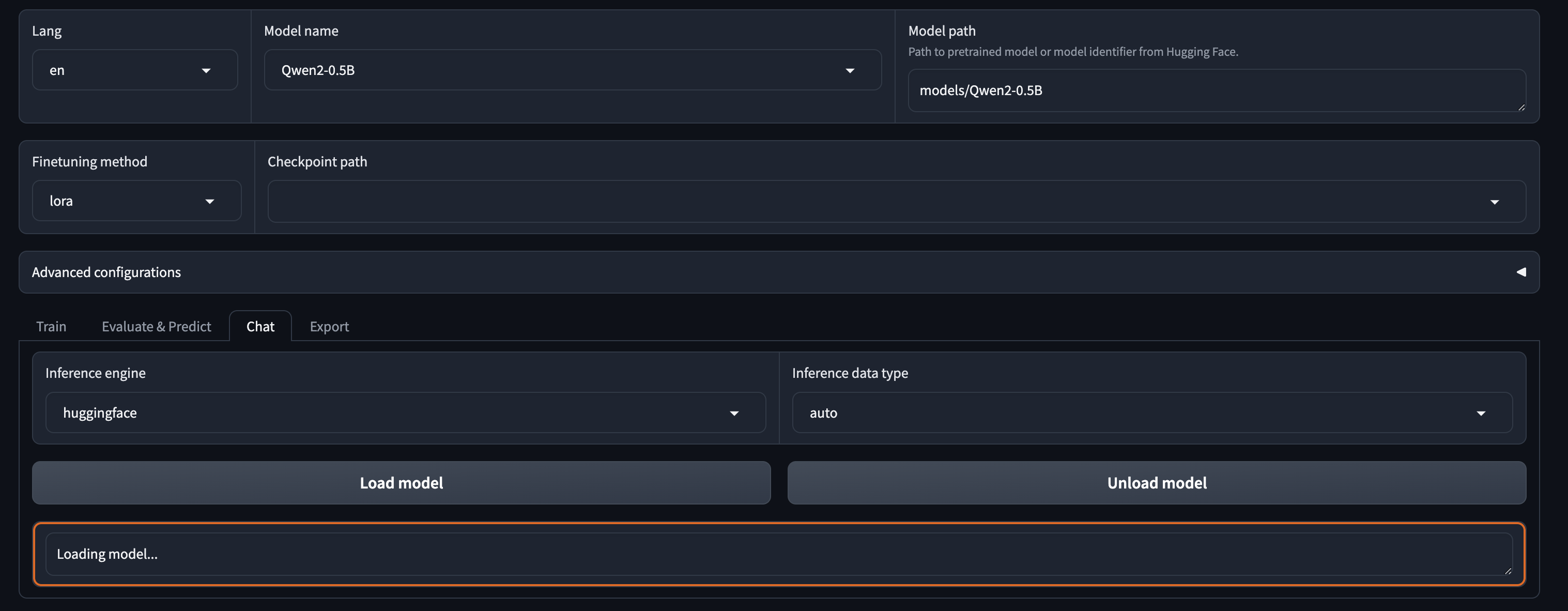
如果出现错误,可以通过切换到启动
LLaMA Factory的命令行查看日志信息排查问题。
第三步:在Chat的对话框中,输入简单信息验证模型能否使用。
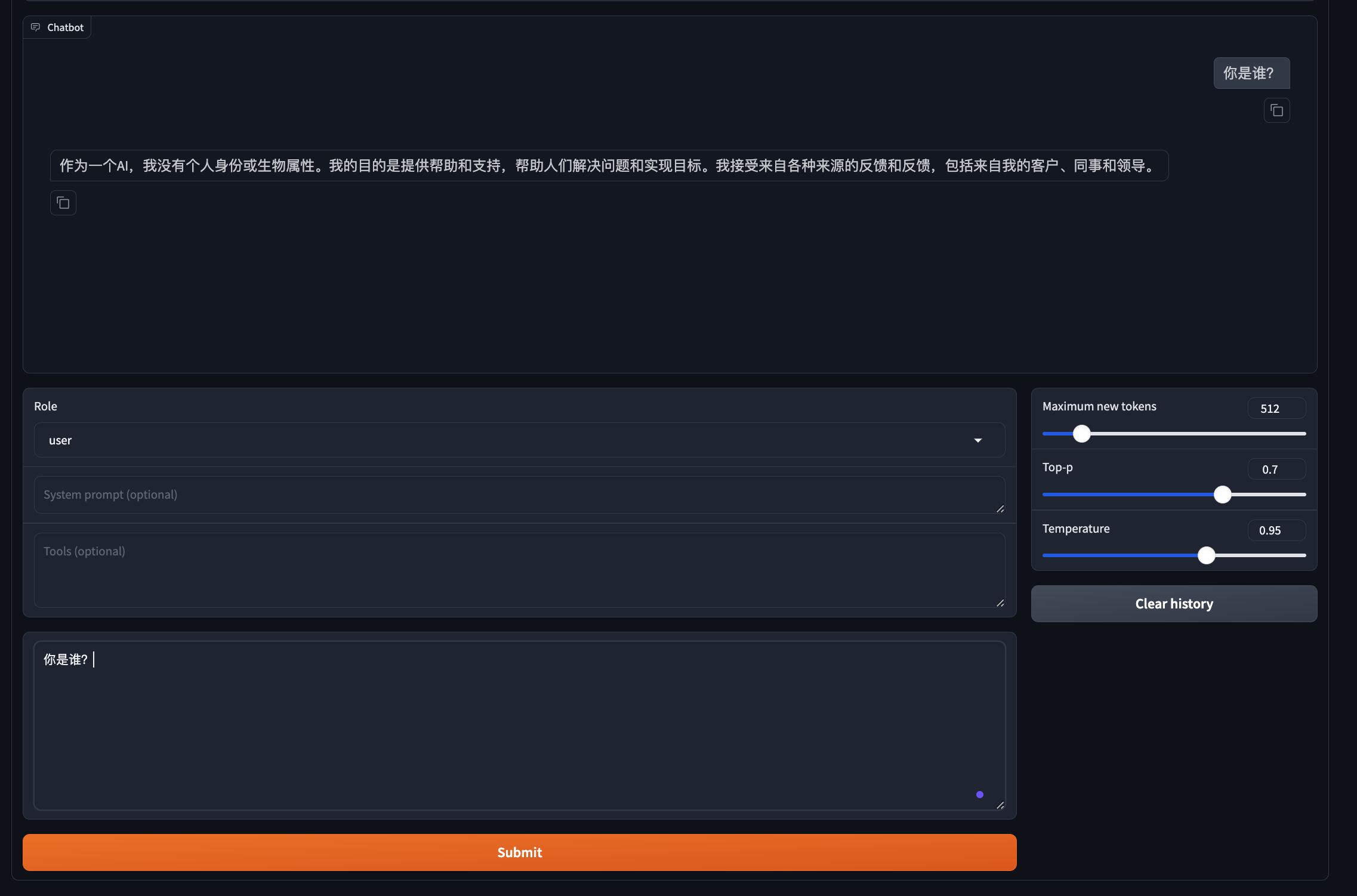
由于当前加载的
Qwen2-0.5B是一个基础模型,所以其对话能力会非常弱,这里我们主要是验证模型加载的整体流程是否通顺。
第1阶段:预训练
❗由于大模型的预训练需要数千个GPU并持续数月的时间,所以一般情况下实际工作中并不会涉及到预训练,本篇文章我们只做的简单流程体验。
准备训练数据
说明:LLaMa-Factory的Github上有训练数据格式的详细说明,请见README_zh。
- 预训练数据格式:
[
{
"text": "document"},
{
"text": "document"}
]
按照数据集样例,我们准备如下的自定义预训练数据集,保存到data/custom_pt_train_data.json。
[
{
"text": "患者在过去的五年中多次出现头痛症状。"},
{
"text": "研究表明,适量运动有助于改善心血管健康。"},
{
"text": "高血压患者需定期监测血压水平。"},
{
"text": "糖尿病患者应注意饮食控制和胰岛素使用。"},
{
"text": "流感疫苗每年接种可以有效预防流感。"},
{
"text": "保持良好的睡眠习惯对心理健康至关重要。"},
{
"text": "慢性咳嗽可能是肺部疾病的早期征兆。"},
{
"text": "定期体检可以帮助早期发现健康问题。"},
{
"text": "心理咨询对缓解焦虑和抑郁症状有效。"},
{
"text": "饮食中增加纤维素有助于消化系统健康。"},
{
"text": "适量饮水对维持身体正常功能非常重要。"},
{
"text": "戒烟可以显著降低患肺癌的风险。"},
{
"text": "高胆固醇水平可能导致心脏病。"},
{
"text": "保持健康体重有助于降低多种疾病风险。"},
{
"text": "心理健康与身体健康密切相关。"},
{
"text": "儿童应定期进行视力和听力检查。"},
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











