






前言
在上一章【课程总结】day27:大模型之初识RAG中,我们初步了解了RAG的基本概念和原理,并通过代码实践了一个简单的RAG流程。本章我们将基于RAG的基本流程,深入了解文档读取(LOAD)、文档切分(SPLIT)、向量化(EMBED) 和 存储(STORE) 的每个环节,并结合代码进行常见场景的实践。
RAG流程回顾
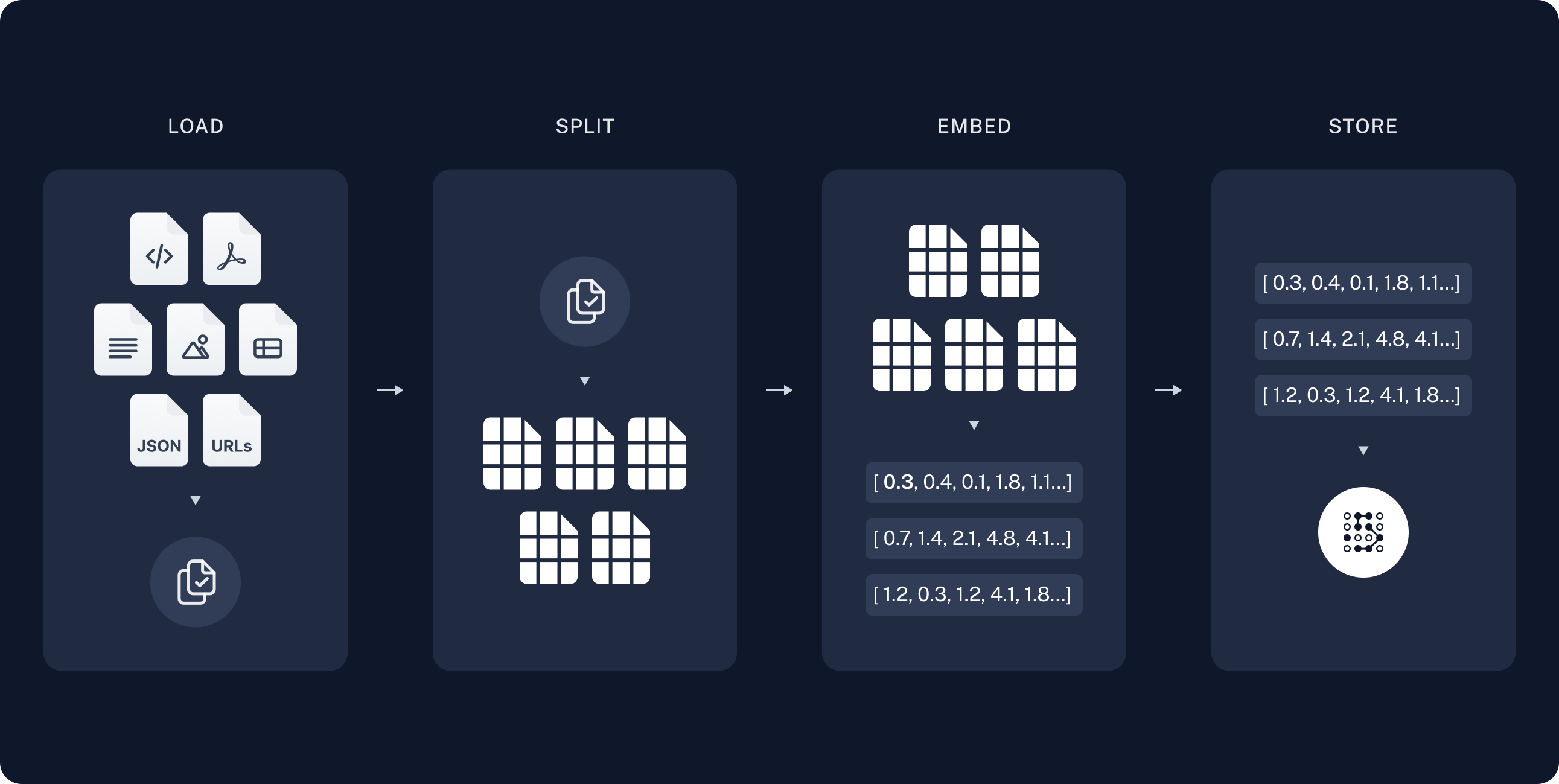
回顾RAG的流程如上所示,具体代码见RAG代码,本章不再赘述。
文档读取(LOAD)
简介:由于我们的知识广泛存在各类文档中,所以文档读取(LOAD)在RAG系统中承担着 获取数据 的职责。
常见文件:
- 文本文件(.txt)
- CSV(.csv)
- PDF(.pdf)
- Word 文档(.docx)
- Excel 工作簿(.xlsx)
- PPT 演示文稿(.pptx)
- HTML 文件(.html)
- Markdown 文件(.md)
常见的文件处理库:
- langchain_community.document_loaders
- 在langchain_community的API文档中有数十种文件的处理API,除了上述常见的文件之外,还有.srt字幕文件、.ipynb文件、代码片段等支持。
CSV文件加载器
CSVLoader函数说明
class langchain_community.document_loaders.csv_loader.CSVLoader(
file_path: Union[str, Path],
source_column: Optional[str] = None,
metadata_columns: Sequence[str] = (),
csv_args: Optional[Dict] = None,
encoding: Optional[str] = None,
autodetect_encoding: bool = False)
说明:
file_path:指定要加载的 CSV 文件的路径- 例如:“data/myfile.csv”
source_column(可选):指定哪一列作为数据的主要来源。- 例如:“text”
metadata_columns:指定哪些列应作为元数据加载。- 例如:[“name”, “age”]
csv_args(可选):自定义 CSV 加载的行为。- 例如:{“delimiter”: “;”, “header”: 0}(指定分隔符为分号,并将第一行作为表头)
示例
示例1:仅加载.csv文件示例:
from langchain_community.document_loaders import CSVLoader
students_loader = CSVLoader(file_path="testfiles/students.csv")
docs = students_loader.load()
docs
运行结果:
# [Document(metadata={'source': 'testfiles/students.csv', 'row': 0}, page_content='name: Tom\nage: 12\nscore: 77'),
# Document(metadata={'source': 'testfiles/students.csv', 'row': 1}, page_content='name: Jerry\nage: 11\nscore: 88'),
# Document(metadata={'source': 'testfiles/students.csv', 'row': 2}, page_content='name: Jim\nage: 12\nscore: 96')]
说明:
- metadata:文档元数据,包括文档来源、行号等,用来进行溯源使用。
- page_content:文档内容,即文本内容。
示例2:加载.csv文件指定列作为元数据:
from langchain_community.document_loaders import CSVLoader
students_loader = CSVLoader(file_path="testfiles/students.csv", metadata_columns=["name", "score"])
docs = students_loader.load()
docs
运行结果:
# [Document(metadata={'source': 'testfiles/students.csv', 'row': 0, 'name': 'Tom', 'score': '77'}, page_content='age: 12'),
# Document(metadata={'source': 'testfiles/students.csv', 'row': 1, 'name': 'Jerry', 'score': '88'}, page_content='age: 11'),
# Document(metadata={'source': 'testfiles/students.csv', 'row': 2, 'name': 'Jim', 'score': '96'}, page_content='age: 12')]
示例3:使用RAG链测试大模型的知识理解能力
from langchain_community.document_loaders import CSVLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate
from utils import get_qwen_models
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 连接大模型
llm, chat, embed = get_qwen_models()
# 读取.csv文件
students_loader = CSVLoader(file_path="testfiles/students.csv")
docs = students_loader.load()
# 向量化入库
vectorstore = Chroma.from_documents(documents=docs, embedding=embed)
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
prompt = ChatPromptTemplate.from_messages([
("human", """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:""")
])
# RAG 链
rag_chain = (
{"context": retriever | format_docs,
"question": RunnablePassthrough()}
| prompt
| chat
| StrOutputParser()
)
rag_chain.invoke(input="谁的成绩最高?")
运行结果:
# 'Jerry的成绩最高,得了88分。'
TXT文件加载器
TXTLoader函数说明
class langchain_community.document_loaders.text.TextLoader(
file_path: Union[str, Path],
encoding: Optional[str] = None,
autodetect_encoding: bool = False)
说明:
file_path:指定要加载的文本文件的路径。encoding(可选):指定文本文件的编码格式,一般是"utf-8"
示例
from langchain_community.document_loaders import TextLoader
txt_loader = TextLoader(file_path="testfiles/测试文件.txt", encoding="utf8")
docs = txt_loader.load()
docs
运行结果:
[Document(metadata={'source': 'testfiles/测试文件.txt'}, page_content='大语言模型作为人工智能领域的重要技术之一,具有广泛的应用场景。以下是十个方面的应用场景及其详细描述:\n\n1. 机器翻译\n描述:大语言模型通过训练可以学习不同语言之间的语法和语义规则,实现自动翻译。这种技术已广泛应用于跨国企业沟通、国际合作等领域,如谷歌翻译等产品。尽管在处理长句子和歧义消解等方面仍面临挑战,但随着技术的发展,其准确性和流畅度不断提升。\n\n2. 智能客服与聊天机器人\n描述:大语言模型被用于开发智能客服助手和聊天机器人,能够理解用户的问题并提供相应的解决方案或转达给相关部门。这不仅提高了客服效率,还提升了用户体验。例如,通过自然语言处理技术,智能客服助手可以分析用户情感状态,及时发现问题并优化服务。\n\n3. 文本生成与创作\n描述:大语言模型能够生成符合语法规则的文章、新闻、小说等文本内容。通过学习大量文本数据,模型可以生成具有创造性和相关性的内容,广泛应用于新闻报道、广告营销等领域。此外,它还能根据给定主题或关键词生成文章,为创作者提供灵感和辅助。\n\n4. 情感分析\n描述:大语言模型通过分析文本中的情感倾向和情感表达,帮助企业了解客户反馈和情感状态,从而制定更精准的营销策略或优化客户服务。这种技术还可用于社交媒体监控,实时分析公众对某一主题或事件的情绪和反应。\n\n5. 自动问答系统\n描述:通过学习大量问题和答案,大语言模型能够自动生成符合语法规则的问题和答案。这种自动问答系统可应用于智能助手、搜索引擎等领域,为用户提供高效、准确的信息服务。结合知识图谱技术,问答系统的知识检索和推理能力得到进一步增强。\n\n6. 自动摘要与总结\n描述:大语言模型能够自动对文本进行摘要和总结,提取关键信息,帮助用户快速了解文本主旨和重点。这种技术在学术论文、新闻报道等领域具有重要应用价值,提高了信息获取的效率。\n\n7. 代码生成与自动化编程\n描述:大语言模型通过学习大量代码数据,可以理解编程语言的语法和逻辑规则,实现代码的自动生成。这有助于非技术用户生成基本代码,同时为专业编程人员提供辅助,加快开发进程。然而,在复杂任务中仍需人工审核和调整。\n\n8. 信息检索与推荐系统\n描述:大语言模型可应用于改善搜索引擎结果和内容推荐算法。通过分析用户查询意图和上下文信息,模型能够提供更准确、个性化的搜索结果和内容推荐,提升用户体验和满意度。\n\n9. 生物医学研究\n描述:在生物医学领域,大语言模型可用于分析基因组数据、蛋白质相互作用等,加速药物发现和新疗法的研究。例如,通过预测基因变异的功能影响,研究者能够更全面地分析人类基因组的潜在风险和治疗靶点。\n\n10. 语音识别与生成\n描述:大语言模型在语音识别和语音生成方面也展现出巨大潜力。通过将语音转录为文本或将文本转化为语音,该技术使得人们与计算机的交互更加自然和便捷。这对于有听力或视觉障碍的人群尤为重要,有助于他们更好地理解和享受音视频内容。\n\n综上所述,大语言模型在多个领域都具有广泛的应用前景和巨大的价值潜力。随着技术的不断进步和完善,我们有理由相信大语言模型将在未来的人工智能领域发挥更加重要的作用。')]
PDF文件加载器
PyMuPDFLoader函数说明
class langchain_community.document_loaders.pdf.PyMuPDFLoader(
file_path: str, *,
headers: Optional[Dict] = None,
extract_images: bool = False,
**kwargs: Any)
说明:
extract_images:指示是否从 PDF 中提取图像。如果设置为 True,将尝试提取 PDF 中的所有图像。- 使用前需要安装相关依赖:
pip install PyMuPDF
示例
from langchain_community.document_loaders import PyMuPDFLoader
pdf_loader = PyMuPDFLoader(file_path="testfiles/测试文件.pdf")
docs = pdf_loader.load()
docs
运行结果:
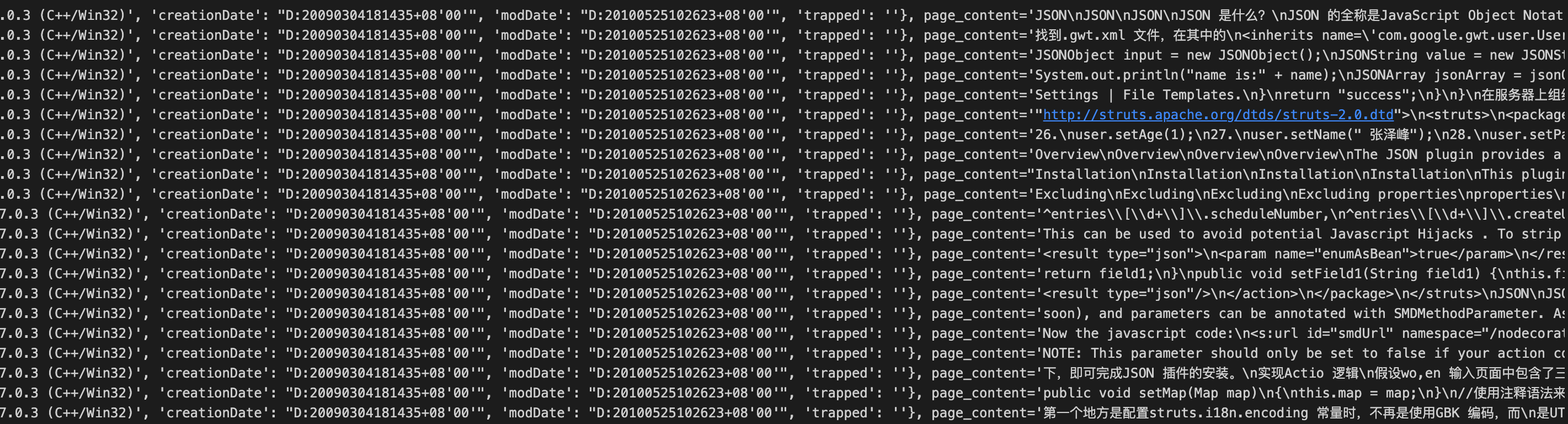
# metadata数据详情
metadata={'source': 'testfiles/测试文件.pdf',
'file_path': 'testfiles/测试文件.pdf',
'page': 0, 'total_pages': 21,
'format': 'PDF 1.6',
'title': 'JSON 是什么?',
'author': '番茄花园',
'subject': '',
'keywords': '',
'creator': 'WPS Office 个人版',
'producer': 'PDFlib 7.0.3 (C++/Win32)',
'creationDate': "D:20090304181435+08'00'",
'modDate': "D:20100525102623+08'00'", 'trapped': ''
}
原始PDF文件如下:

说明:通过对比可以看到
- pagecontent与PDF文件内容一致。
- metadata数据有比较多的字段,例如:format,title,author,subject,keywords,creator,producer,creationDate,modDate等。
EXCEL文件加载器
UnstructuredExcelLoader函数说明
class langchain_community.document_loaders.excel.UnstructuredExcelLoader(
file_path: Union[str, Path],
mode: str = 'single',
**unstructured_kwargs: Any)
说明:
- 使用前需要安装相关依赖:
pip install unstructured。
示例
from langchain_community.document_loaders import UnstructuredExcelLoader
excel_loader = UnstructuredExcelLoader(file_path="testfiles/测试文件.xlsx", encoding="utf8")
docs = excel_loader.load()
docs
运行结果:

原始文件:
PPT文件加载器
UnstructuredPowerPointLoader函数说明
class langchain_community.document_loaders.powerpoint.UnstructuredPowerPointLoader(
file_path: Union[str, List[str], Path, List[Path]], *,
mode: str = 'single',
**unstructured_kwargs: Any)
说明:
- 使用前需要安装相关依赖:
pip install python-pptx。
示例
from langchain_community.document_loaders import UnstructuredPowerPointLoader
ppt_loader = UnstructuredPowerPointLoader(file_path="testfiles/测试文件.pptx", mode="single")
docs = ppt_loader.load()
docs[0].page_content
运行结果:

原始文件:

说明:
- 通过对比,可以看到PPT中的文字会被提取出来,图片会被清洗掉。
WORD文件加载器
UnstructuredWordDocumentLoader函数说明
class langchain_community.document_loaders.word_document.UnstructuredWordDocumentLoader(
file_path: Union[str, List[str], Path, List[Path]], *,
mode: str = 'single',
**unstructured_kwargs: Any)
说明:
- 使用前需要安装相关依赖:
pip install python-docx。
示例
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
word_loader = UnstructuredWordDocumentLoader(file_path="testfiles/测试文件.docx", mode="single")
docs = ppt_loader.load()
docs
运行结果:

原始文件:
MARKDOWN文件加载器
UnstructuredMarkdownLoader函数说明
class langchain_community.document_loaders.markdown.UnstructuredMarkdownLoader(
file_path: Union[str, List[str], Path, List[Path]], *,
mode: str = 'single',
**unstructured_kwargs: Any)
- 使用前需要安装相关依赖:
pip install markdown。
示例
from langchain_community.document_loaders import UnstructuredMarkdownLoader
md_loader = UnstructuredMarkdownLoader(file_path="testfiles/测试文件.md", mode="single")
docs = md_loader.load()
docs
运行结果:

原始文件:

HTML文件加载器
UnstructuredHTMLLoader函数说明
class langchain_community.document_loaders.html.UnstructuredHTMLLoader(
file_path: Union[str, List[str], Path, List[Path]], *,
mode: str = 'single',
**unstructured_kwargs: Any)
说明:
- model可以设置为’elements’,表示将HTML元素作为文档进行切分。
示例
from langchain_community.document_loaders import UnstructuredHTMLLoader
html_file = "testfiles/测试文件.htm"
html_loader = UnstructuredHTMLLoader(file_path=html_file, mode="single")
docs = html_loader.load()
docs[0].page_content
运行结果:

原始文件:
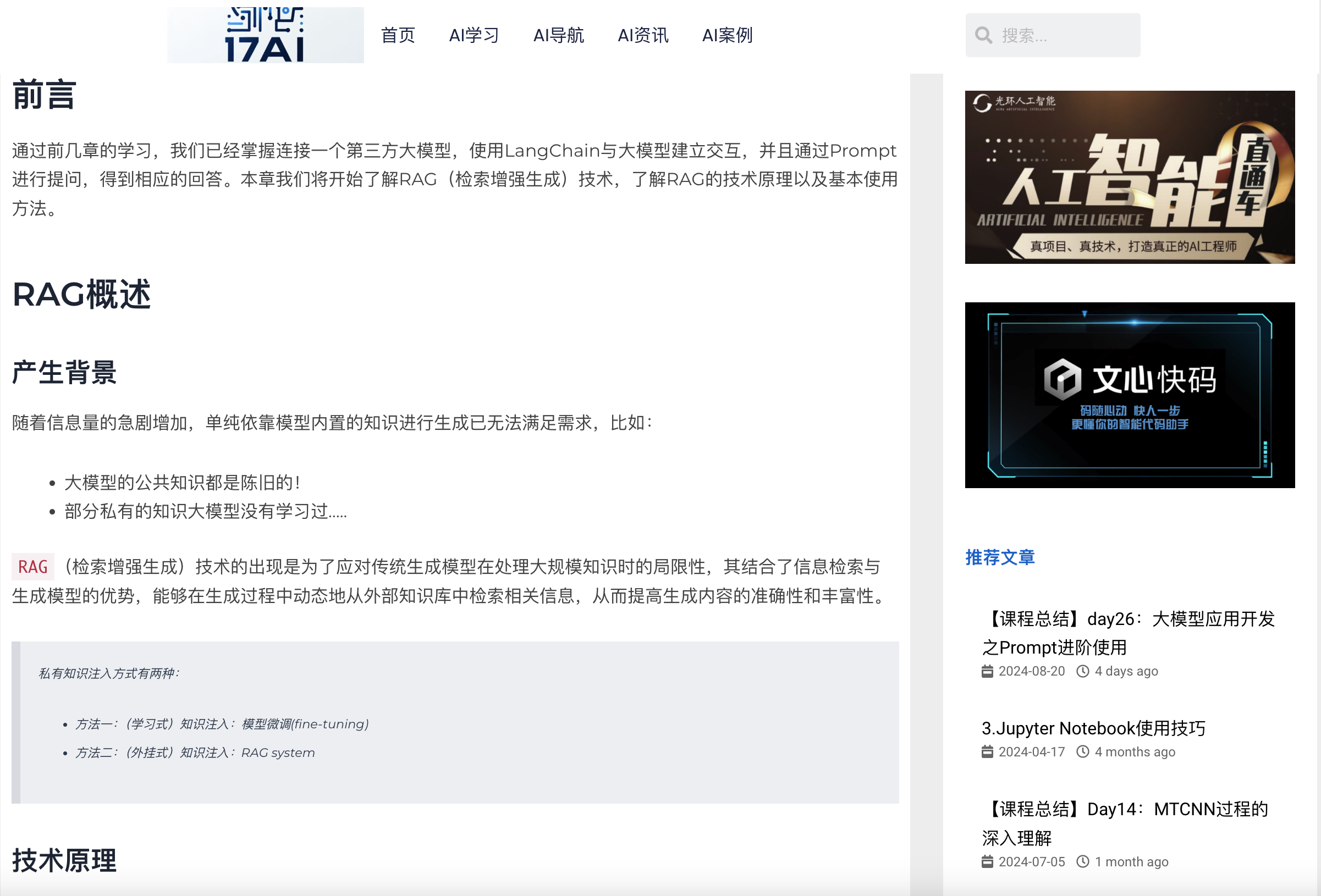
补充说明:
如果将上面的mode改为mode=“elements”,运行如下,但是得到内容对于建立知识库没有太大帮助。
SQL文件加载器
SQLDatabaseLoader函数说明
class langchain_community.document_loaders.sql_database.SQLDatabaseLoader(
query: Union[str, Select],
db: SQLDatabase, *,
parameters: Optional[Dict[str, Any]] = None,
page_content_mapper: Optional[Callable[[...], str]] = None,
metadata_mapper: Optional[Callable[[...], Dict[str, Any]]] = None,
source_columns: Optional[Sequence[str]] = None,
include_rownum_into_metadata: bool = False,
include_query_into_metadata: bool = False)
说明:
query:指定要执行的 SQL 查询。- 例如:query = “SELECT * FROM documents”
db: 指定要连接的 SQL 数据库实例。parameters(可选):可选参数,用于传递 SQL 查询的参数,以便于动态查询。- 例如:parameters = {“id”: 1}
page_content_mapper(可选):可选的映射函数,用于处理查询结果中的每一行,返回格式化后的内容。metadata_mapper(可选):可选的映射函数,用于处理查询结果中的每一行,返回元数据字典。- 例如:metadata_mapper=lambda row: {“id”: row[‘id’], “created_at”: row[‘created_at’]}
source_columns(可选):可选参数,指定要从查询结果中提取的列名。include_rownum_into_metadata:指示是否将行号包含在元数据中。include_query_into_metadata:指示是否将执行的 SQL 查询包含在元数据中。- 使用前需要安装相关依赖:
pip install sqlalchemy。
示例
from langchain_community.document_loaders import SQLDatabaseLoader
from langchain_community.utilities import SQLDatabase
from sqlalchemy import create_engine
# 创建 SQLite 数据库引擎,指定数据库文件的路径
engine = create_engine(url="sqlite:///testfiles/students.db")
# 使用创建的引擎实例化 SQLDatabase 对象
db = SQLDatabase(engine=engine)
# 创建 SQLDatabaseLoader 实例,指定要执行的 SQL 查询
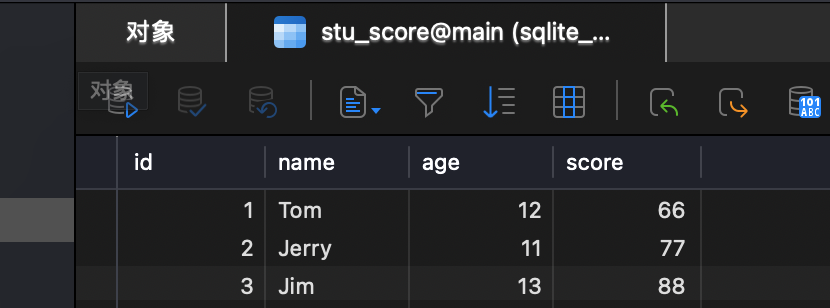
sql_loader = SQLDatabaseLoader(query="SELECT * FROM stu_score;", db=db,
include_query_into_metadata=True,
include_rownum_into_metadata=True)
docs = sql_loader.load()
docs
运行结果:

原始文件:
以上只是对各类文件加载器的简单梳理,在实际应用中需要进行进一步的封装,例如:
- 封装为class方式
- 以文件后缀名自动判断调用的加载器
- 添加更多回溯信息
- …
在开源项目QAnything(网易的一款开源RAG系统)中,该项目中的qanything_kernel有着比较详细的封装,可以参考。
文档切分(SPLIT)
按照字符切分
CharacterTextSplitter类说明
class langchain_text_splitters.character.CharacterTextSplitter:
def __init__(self, chunk_size: int, chunk_overlap: int = 0):
说明:
- chunk_size:指定每个文本片段的最大字符长度。
- chunk_overlap:指定相邻文本片段之间的重叠字符数。重叠可以帮助保持上下文的一致性。
示例
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
text_loader = TextLoader(file_path="testfiles/测试文件.txt", encoding="utf8")
docs = text_loader.load()
# 字符级文本切分器
spliter = CharacterTextSplitter(separator = '\n\n', chunk_size=128, chunk_overlap=32)
results = spliter.split_documents(documents=docs)
# 打印切分结果
print(f'切分个数:{len(results)}')
for idx, chunk in enumerate(results):
print(f'第{idx+1}段,长度为:{len(chunk.page_content)}')
print(f'切分内容:\n{chunk.page_content}')
print("-*-" *30 + "\n")
运行结果:
# chunk_size=128, chunk_overlap=32
切分个数:12
第1段,长度为:50
切分内容:
大语言模型作为人工智能领域的重要技术之一,具有广泛的应用场景。以下是十个方面的应用场景及其详细描述:
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第2段,长度为:124
切分内容:
1. 机器翻译
描述:大语言模型通过训练可以学习不同语言之间的语法和语义规则,实现自动翻译。这种技术已广泛应用于跨国企业沟通、国际合作等领域,如谷歌翻译等产品。尽管在处理长句子和歧义消解等方面仍面临挑战,但随着技术的发展,其准确性和流畅度不断提升。
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第3段,长度为:131
切分内容:
2. 智能客服与聊天机器人
描述:大语言模型被用于开发智能客服助手和聊天机器人,能够理解用户的问题并提供相应的解决方案或转达给相关部门。这不仅提高了客服效率,还提升了用户体验。例如,通过自然语言处理技术,智能客服助手可以分析用户情感状态,及时发现问题并优化服务。
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第4段,长度为:125
切分内容:
3. 文本生成与创作
描述:大语言模型能够生成符合语法规则的文章、新闻、小说等文本内容。通过学习大量文本数据,模型可以生成具有创造性和相关性的内容,广泛应用于新闻报道、广告营销等领域。此外,它还能根据给定主题或关键词生成文章,为创作者提供灵感和辅助。
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第5段,长度为:106
...
切分内容:
综上所述,大语言模型在多个领域都具有广泛的应用前景和巨大的价值潜力。随着技术的不断进步和完善,我们有理由相信大语言模型将在未来的人工智能领域发挥更加重要的作用。
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
# 如果改为chunk_size=512, chunk_overlap=32
切分个数:3
第1段,长度为:436
切分内容:
大语言模型作为人工智能领域的重要技术之一,具有广泛的应用场景。以下是十个方面的应用场景及其详细描述:
1. 机器翻译
描述:大语言模型通过训练可以学习不同语言之间的语法和语义规则,实现自动翻译。这种技术已广泛应用于跨国企业沟通、国际合作等领域,如谷歌翻译等产品。尽管在处理长句子和歧义消解等方面仍面临挑战,但随着技术的发展,其准确性和流畅度不断提升。
2. 智能客服与聊天机器人
描述:大语言模型被用于开发智能客服助手和聊天机器人,能够理解用户的问题并提供相应的解决方案或转达给相关部门。这不仅提高了客服效率,还提升了用户体验。例如,通过自然语言处理技术,智能客服助手可以分析用户情感状态,及时发现问题并优化服务。
3. 文本生成与创作
描述:大语言模型能够生成符合语法规则的文章、新闻、小说等文本内容。通过学习大量文本数据,模型可以生成具有创造性和相关性的内容,广泛应用于新闻报道、广告营销等领域。此外,它还能根据给定主题或关键词生成文章,为创作者提供灵感和辅助。
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第2段,长度为:443
切分内容:
4. 情感分析
描述:大语言模型通过分析文本中的情感倾向和情感表达,帮助企业了解客户反馈和情感状态,从而制定更精准的营销策略或优化客户服务。这种技术还可用于社交媒体监控,实时分析公众对某一主题或事件的情绪和反应。
5. 自动问答系统
描述:通过学习大量问题和答案,大语言模型能够自动生成符合语法规则的问题和答案。这种自动问答系统可应用于智能助手、搜索引擎等领域,为用户提供高效、准确的信息服务。结合知识图谱技术,问答系统的知识检索和推理能力得到进一步增强。
6. 自动摘要与总结
描述:大语言模型能够自动对文本进行摘要和总结,提取关键信息,帮助用户快速了解文本主旨和重点。这种技术在学术论文、新闻报道等领域具有重要应用价值,提高了信息获取的效率。
...
综上所述,大语言模型在多个领域都具有广泛的应用前景和巨大的价值潜力。随着技术的不断进步和完善,我们有理由相信大语言模型将在未来的人工智能领域发挥更加重要的作用。
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
递归方式切分
RecursiveCharacterTextSplitter函数说明
class langchain_text_splitters.character.RecursiveCharacterTextSplitter(
separators: Optional[List[str]] = None,
keep_separator: bool = True,
is_separator_regex: bool = False,
**kwargs: Any
)
说明:
- separators:用于指定切分文本时使用的分隔符列表。可以包括换行符、句号、逗号等。
- keep_separator:指定在切分后是否保留分隔符。如果设置为 True,切分后的文本片段将包含分隔符。
- is_separator_regex:指定 separators 是否为正则表达式。如果设置为 True,则 separators 将被视为正则表达式。
示例
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_loader = TextLoader(file_path="testfiles/测试文件.txt", encoding="utf8")
docs = text_loader.load()
separators=["\n", ".", "。", "!", "!", "?", "?", ";", ";", "……", "…", "、", ",", ",", " "]
# 创建 RecursiveCharacterTextSplitter 实例
splitter = RecursiveCharacterTextSplitter(
separators=separators,
keep_separator=True,
is_separator_regex=False,
chunk_size=128,
chunk_overlap=32
)
results = splitter.split_documents(documents=docs)
# 打印切分结果
print(f'切分个数:{len(results)}')
for idx, chunk in enumerate(results):
print(f'第{idx+1}段,长度为:{len(chunk.page_content)}')
print(f'切分内容:\n{chunk.page_content}')
print("-*-" *30 + "\n")
运行结果:
切分个数:13
第1段,长度为:59
切分内容:
大语言模型作为人工智能领域的重要技术之一,具有广泛的应用场景。以下是十个方面的应用场景及其详细描述:
1. 机器翻译
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第2段,长度为:124
切分内容:
1. 机器翻译
描述:大语言模型通过训练可以学习不同语言之间的语法和语义规则,实现自动翻译。这种技术已广泛应用于跨国企业沟通、国际合作等领域,如谷歌翻译等产品。尽管在处理长句子和歧义消解等方面仍面临挑战,但随着技术的发展,其准确性和流畅度不断提升。
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第3段,长度为:13
切分内容:
2. 智能客服与聊天机器人
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第4段,长度为:117
切分内容:
描述:大语言模型被用于开发智能客服助手和聊天机器人,能够理解用户的问题并提供相应的解决方案或转达给相关部门。这不仅提高了客服效率,还提升了用户体验。例如,通过自然语言处理技术,智能客服助手可以分析用户情感状态,及时发现问题并优化服务。
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第5段,长度为:125
...
切分内容:
综上所述,大语言模型在多个领域都具有广泛的应用前景和巨大的价值潜力。随着技术的不断进步和完善,我们有理由相信大语言模型将在未来的人工智能领域发挥更加重要的作用。
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
对比CharacterTextSplitter的执行结果,RecursiveCharacterTextSplitter在切分长文本时,可以切分出更小的文本片段,并且可以保留分隔符。
按照Token切分
TokenTextSplitter函数说明
class langchain_text_splitters.base.TokenTextSplitter(
encoding_name: str = 'gpt2',
model_name: Optional[str] = None,
allowed_special: Union[Literal['all'], AbstractSet[str]] = {},
disallowed_special: Union[Literal['all'], Collection[str]] = 'all',
**kwargs: Any
)
说明:
- model_name(可选):可选参数,用于指定特定的语言模型名称。
- allowed_special:指定被允许的特殊令牌集合。
- disallowed_special:指定不允许的特殊令牌集合。
- 使用前需要安装依赖:
pip install tiktoken。 - encoding_name:指定用于令牌化文本的编码名称。该选项通过以下代码可以得到常见选项:
import tiktoken
tiktoken.list_encoding_names()
# 运行结果:
# ['gpt2', 'r50k_base', 'p50k_base', 'p50k_edit', 'cl100k_base', 'o200k_base']
gpt2:这是 OpenAI 的GPT-2模型使用的编码,基于Byte Pair Encoding (BPE)。它适用于大多数基于 GPT-2 的任务,能够有效处理英语文本。r50k_base:这是针对OpenAI的模型(如GPT-3)的一种编码,使用了50,000个最常见的子词单位。它是一种更为精简的编码方式,适用于对文本进行更细粒度的切分。p50k_base:基于BPE的编码,使用50,000个子词单位。该编码主要用于处理更复杂的文本生成和理解任务,适合与GPT-3及相关模型的配合使用。p50k_edit:这是p50k_base的一种变体,专门优化用于文本编辑任务。这种编码关注于文本的修改和调整,适合需要对文本进行细微编辑的应用场景。cl100k_base:这是针对更大规模模型(如GPT-4)的一种编码,使用了100,000个子词单位。它能够处理更复杂和多样化的文本,适合高性能的文本生成和理解任务。o200k_base:这是一个更高级的编码,使用了200,000个子词单位,旨在处理极为复杂的文本任务。它适合需要处理大量信息或多样化文本的应用,能够提供更高的灵活性和精度。
以上选项内容由ChatGPT辅助生成,如有错误,请及时反馈。
示例
import tiktoken
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import TokenTextSplitter
text_loader = TextLoader(file_path="testfiles/测试文件.txt", encoding="utf8")
docs = text_loader.load()
splitter = TokenTextSplitter(encoding_name="o200k_base",
chunk_size=128,
chunk_overlap=64)
results = splitter.split_documents(documents=docs)
# 打印切分结果
print(f'切分个数:{len(results)}')
for idx, chunk in enumerate(results):
print(f'第{idx+1}段,长度为:{len(chunk.page_content)}')
print(f'切分内容:\n{chunk.page_content}')
print("-*-" *30 + "\n")
运行结果:
切分个数:13
第1段,长度为:185
切分内容:
大语言模型作为人工智能领域的重要技术之一,具有广泛的应用场景。以下是十个方面的应用场景及其详细描述:
1. 机器翻译
描述:大语言模型通过训练可以学习不同语言之间的语法和语义规则,实现自动翻译。这种技术已广泛应用于跨国企业沟通、国际合作等领域,如谷歌翻译等产品。尽管在处理长句子和歧义消解等方面仍面临挑战,但随着技术的发展,其准确性和流畅度不断提升。
2. 智能客服
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第2段,长度为:198
切分内容:
种技术已广泛应用于跨国企业沟通、国际合作等领域,如谷歌翻译等产品。尽管在处理长句子和歧义消解等方面仍面临挑战,但随着技术的发展,其准确性和流畅度不断提升。
2. 智能客服与聊天机器人
描述:大语言模型被用于开发智能客服助手和聊天机器人,能够理解用户的问题并提供相应的解决方案或转达给相关部门。这不仅提高了客服效率,还提升了用户体验。例如,通过自然语言处理技术,智能客服助手可以分析用户情感状态,
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第3段,长度为:215
切分内容:
与聊天机器人
描述:大语言模型被用于开发智能客服助手和聊天机器人,能够理解用户的问题并提供相应的解决方案或转达给相关部门。这不仅提高了客服效率,还提升了用户体验。例如,通过自然语言处理技术,智能客服助手可以分析用户情感状态,及时发现问题并优化服务。
3. 文本生成与创作
...
综上所述,大语言模型在多个领域都具有广泛的应用前景和巨大的价值潜力。随着技术的不断进步和完善,我们有理由相信大语言模型将在未来的人工智能领域发挥更加重要的作用。
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
如果将encoding_name设置为’gpt2’,则切分结果如下:
切分个数:43
第1段,长度为:65
切分内容:
大语言模型作为人工智能领域的重要技术之一,具有广泛的应用场景。以下是十个方面的应用场景及其详细描述:
1. 机器翻译
描述:大�
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第2段,长度为:62
切分内容:
�下是十个方面的应用场景及其详细描述:
1. 机器翻译
描述:大语言模型通过训练可以学习不同语言之间的语法和语义规则,实现
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第3段,长度为:58
切分内容:
�言模型通过训练可以学习不同语言之间的语法和语义规则,实现自动翻译。这种技术已广泛应用于跨国企业沟通、国际合作等领�
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
通过对比,可以看到o200k_base的效果要优于gpt2。
按照markdown标题切分
示例
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import MarkdownTextSplitter
text_loader = TextLoader(file_path="testfiles/测试文件.md", encoding="utf8")
docs = text_loader.load()
# 创建 MarkdownTextSplitter 实例
splitter = MarkdownTextSplitter(chunk_size=128, chunk_overlap=64)
results = splitter.split_documents(documents=docs)
# 打印切分结果
print(f'切分个数:{len(results)}')
for idx, chunk in enumerate(results):
print(f'第{idx+1}段,长度为:{len(chunk.page_content)}')
print(f'切分内容:\n{chunk.page_content}')
print("-*-" *30 + "\n")
运行结果:
切分个数:196
第1段,长度为:126
切分内容:
## 前言
本章我们将通过 LLaMA-Factory 具体实践大模型训练的三个阶段,包括:预训练、监督微调和偏好纠正。
## 大模型训练回顾

## 训练目标
通过实践大模型的三个训练阶段,训练一个医疗大模型
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第2段,长度为:123
切分内容:
## 训练过程实施
### 准备训练框架
`LLaMA Factory`是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过Web UI界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架,GitHub星标超过2万。
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
第3段,长度为:118
切分内容:
#### 运行环境要求
- 硬件:
- GPU:推荐使用24GB显存的显卡或者更高配置
...
## 参考资料
[Github:LLaMA-Factory的README文件](https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README.md)
-*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*--*-
对于Markdown文本,使用MarkdownTextSplitter进行切分,切分效果比较好。
向量化(EMBED)
考虑到RAG系统一般都有私有化部署的需求(因为数据涉密),所以对应的向量化的方式有两种:本地化 和 在线化。
本地化
在开源项目QAnything中,其提供了一种使用本地模型的方法,其大致步骤是:
- 在本地保存了一个向量化模型。
- 在调用向量化模型时,使用本地的模型.
embedding_client = EmbeddingClient(
server_url=LOCAL_EMBED_SERVICE_URL,
model_name=LOCAL_EMBED_MODEL_NAME,
model_version='1',
resp_wait_s=120,
tokenizer_path='qanything_kernel/connector/embedding/embedding_model_0630')
由于示例代码的集成度较高,剥离核心代码执行成本较大,所以此处并未实践,只是引用相关的信息。
在线化
使用HuggingFaceEmbeddings
LangChain社区提供了HuggingFaceEmbeddings,该类可以加载HuggingFace的预训练模型,并使用该模型进行向量化。
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
# 加载文本
text_loader = TextLoader(file_path="testfiles/测试文件.txt", encoding="utf8")
docs = text_loader.load()
# 切分文本
spliter = RecursiveCharacterTextSplitter(chunk_size=128, chunk_overlap=64)
docs = spliter.split_documents(documents=docs)
# 初始化 HuggingFaceEmbeddings
embedding_function = HuggingFaceEmbeddings(model_name="bert-base-chinese")
# 创建向量数据库
store = Chroma(embedding_function=embedding_function, persist_directory="chroma_data")
# 将文档添加到数据库中
store.add_documents(documents=docs)
# 进行相似性搜索
store.similarity_search(query="小米估值多少?", k=2)
说明:
- 使用前需要安装依赖
pip install sentence-transformers
运行结果:
[Document(metadata={'source': 'testfiles/测试文件.txt'}, page_content='1. 机器翻译\n描述:大语言模型通过训练可以学习不同语言之间的语法和语义规则,实现自动翻译。这种技术已广泛应用于跨国企业沟通、国际合作等领域,如谷歌翻译等产品。尽管在处理长句子和歧义消解等方面仍面临挑战,但随着技术的发展,其准确性和流畅度不断提升。'),
Document(metadata={'source': 'testfiles/测试文件.txt'}, page_content='1. 机器翻译\n描述:大语言模型通过训练可以学习不同语言之间的语法和语义规则,实现自动翻译。这种技术已广泛应用于跨国企业沟通、国际合作等领域,如谷歌翻译等产品。尽管在处理长句子和歧义消解等方面仍面临挑战,但随着技术的发展,其准确性和流畅度不断提升。')]
使用QianfanEmbeddings
由于Qwen的API有样本为6个的限制,所以此处试用百度千帆大模型的向量化API。
# util.py
def get_ernie_models():
"""
加载文心系列大模型
"""
# LLM 大语言模型(单轮对话版)
from langchain_community.llms import QianfanLLMEndpoint
# Chat 聊天版大模型(支持多轮对话)
from langchain_community.chat_models import QianfanChatEndpoint
# Embeddings 嵌入模型
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
llm = QianfanLLMEndpoint(model="ERNIE-Bot-turbo", temperature=0.1, top_p=0.2)
chat = QianfanChatEndpoint(model="ERNIE-Lite-8K", top_p=0.2, temperature=0.1)
embed = QianfanEmbeddingsEndpoint(model="bge-large-zh")
return llm, chat, embed
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from utils import get_ernie_models
# 连接大模型
llm_ernie, chat_ernie, embed_ernie = get_ernie_models()
# 加载文本
text_loader = TextLoader(file_path="testfiles/测试文件.txt", encoding="utf8")
docs = text_loader.load()
# 切分文本
spliter = RecursiveCharacterTextSplitter(chunk_size=128, chunk_overlap=64)
docs = spliter.split_documents(documents=docs)
# 使用 ernie 模型创建向量数据库
store = Chroma.from_documents(documents=docs,
embedding=embed_ernie,
persist_directory="chroma_data2")
store.similarity_search(query="小米估值多少?", k=2)
运行结果:
[Document(metadata={'source': 'testfiles/测试文件.txt'}, page_content='2. 智能客服与聊天机器人'),
Document(metadata={'source': 'testfiles/测试文件.txt'}, page_content='大语言模型作为人工智能领域的重要技术之一,具有广泛的应用场景。以下是十个方面的应用场景及其详细描述:')]
通过对比
- 使用QianfanEmbeddingsEndpoint向量化后,在相似性搜索时有两个内容返回;而使用HuggingFaceEmbeddings向量化后,在相似性搜索时只有第一个内容返回。
- 相似性搜索后的内容,看起来与我们Query查询的问题似乎不太相关,只是模型在向量层面计算是比较相似。
原理探寻
import numpy as np
from utils import get_ernie_models
llm_ernie, chat_ernie, embed_ernie = get_ernie_models()
query = np.array(embed_ernie.embed_query(text="小米估值多少?"))
doc1 = np.array(embed_ernie.embed_query(text="2. 智能客服与聊天机器人"))
doc2 = np.array(embed_ernie.embed_query(text="大语言模型作为人工智能领域的重要技术之一,具有广泛的应用场景。以下是十个方面的应用场景及其详细描述:"))
# 欧式距离
result1 = ((query - doc1) ** 2).sum()
print(f'query 和 doc1 的欧式距离为:{result1}')
result2 =((query - doc2) ** 2).sum()
print(f'query 和 doc2 的欧式距离为:{result2}')
# 相关系数
corr1 = 1 - result1 / 2 ** 0.5
print(f'query 和 doc1 的相关系数为:{corr1}')
corr2 = 1 - result2 / 2 ** 0.5
print(f'query 和 doc2 的相关系数为:{corr2}')
运行结果:
# query 和 doc1 的欧式距离为:0.6204636182956037
# query 和 doc2 的欧式距离为:0.8112505547683875
# query 和 doc1 的相关系数为:0.561265968023637
# query 和 doc2 的相关系数为:0.42635923148192456
对比如下代码执行结果:
# 相关性转换
store.similarity_search_with_relevance_scores(query="小米估值多少?", k=2)
运行结果:
[(Document(metadata={'source': 'testfiles/测试文件.txt'}, page_content='2. 智能客服与聊天机器人'),
0.5612658250623314),
(Document(metadata={'source': 'testfiles/测试文件.txt'}, page_content='大语言模型作为人工智能领域的重要技术之一,具有广泛的应用场景。以下是十个方面的应用场景及其详细描述:'),
0.4263594055624078)]
由上可以看到:
- 相似度计算:通过计算两个向量的欧式距离,可以得到两个向量之间的相似度,计算结果越小代表越接近。
- 相似度转换:通过计算两个向量的相关系数,可以得到两个向量之间的相似度,计算结果越大代表越相似。
- 欧式距离计算方法: d ( a , b ) = ∑ i = 1 n ( a i − b i ) 2 d(\mathbf{a}, \mathbf{b}) = \sqrt{\sum_{i=1}^{n} (a_i - b_i)^2} d(a,b)=∑i=1n(ai−bi)2
- 相关系数计算方法: r = 1 − d ( q u e r y , d o c ) 2 r = 1 - \frac{d(\mathbf{query}, \mathbf{doc})}{\sqrt{2}} r=1−2d(query,doc)
similarity_search即为相似度计算。similarity_search_with_relevance_scores即为相似度转换,它是smimilarity_search的扩展,可以返回相似度。
存储(STORE)
如上述示例,我们对数据进行向量化之后,下一步需要存储至向量数据库。目前市面上的向量数据库众多,主流的向量数据库对比如下所示:
| 向量数据库 | URL | GitHub Star | Language | Cloud |
|---|---|---|---|---|
| chroma | chroma | 7.4K | Python | ❌ |
| milvus | milvus | 21.5K | Go/Python/C++ | ✅ |
| pinecone | pinecone | ❌ | ❌ | ✅ |
| qdrant | qdrant | 11.8K | Rust | ✅ |
| typesense | typesense | 12.9K | C++ | ❌ |
| weaviate | weaviate | 6.9K | Go | ✅ |
本例中,我们主要了解Chroma的使用。
Chroma简介
介绍:Chroma 是一个开源的向量数据库,专为处理和存储高维向量而设计,特别适用于机器学习和深度学习应用。
特性:
- 高效的向量存储:Chroma 提供高效的向量存储和检索功能,能够处理大规模数据集。
- 相似性搜索:支持快速的相似性搜索,允许用户根据查询向量找到最相似的向量。
- 灵活的Embedding支持:可以与多种Embedding模型集成。
- 持久化存储:支持将数据持久化存储,确保在重启后数据不会丢失。
- 开源和社区支持:Chroma 是开源项目,用户可以自由使用和修改,同时也享受社区的支持和贡献。
资料:
- 官网主页:https://www.trychroma.com/
- 官网文档:https://docs.trychroma.com/
- Github主页:https://github.com/chroma-core/
- Github项目:https://github.com/chroma-core/chroma/
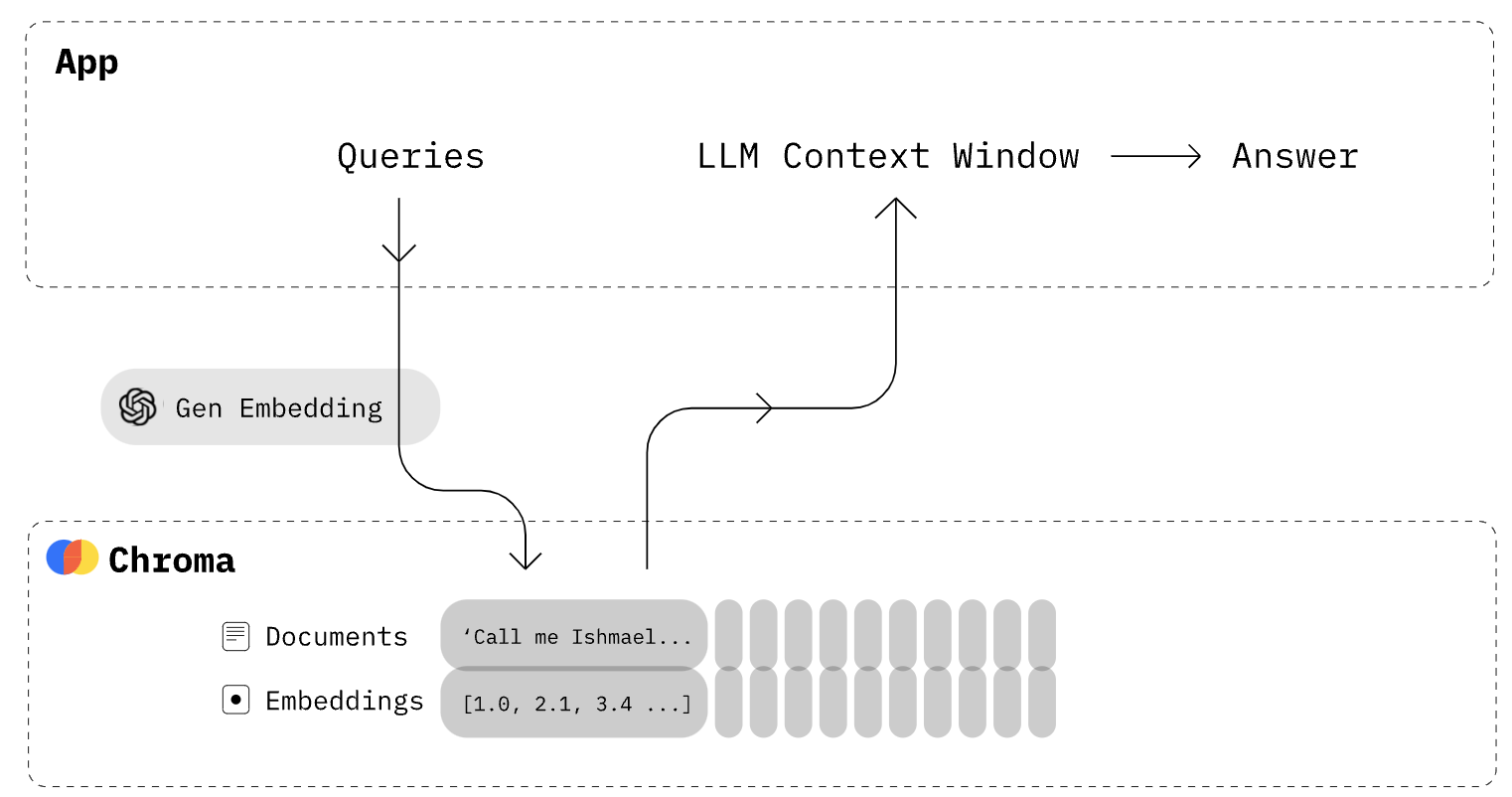
Chroma使用的几种方式
初次了解Chroma的使用时,我被五花八门的API搞得云里雾里,一会是Chromadb,一会是langchain_chroma…
因此,查询了部分资料之后,总结Chroma的使用方式大致是以下三种方式:
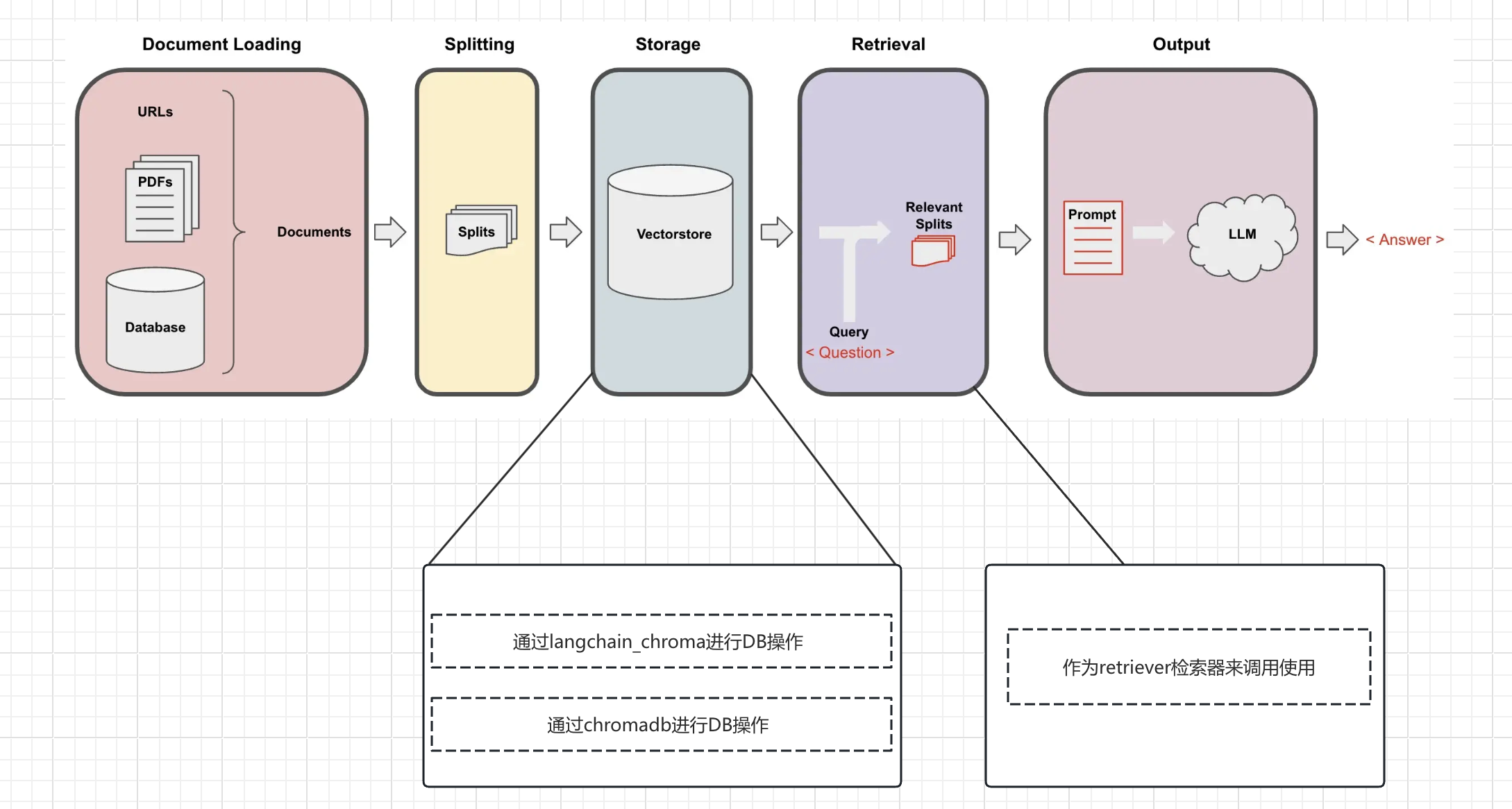
- 第一种方式:是使用Chromadb的源生API接口使用,包括常见的增删改查接口:
create_collection()、collection.add()、collection.query()… - 第二种方式:是通过Langchain的组合包使用Chroma,常见的是:
Chroma.from_documents()、similarity_search()、similarity_search_by_vector()… - 第三种方式:是通过Retriever检索器的方式使用Chroma。
通过Chromadb的源生接口使用Chroma
Chroma 可以以多种形式进行使用:
- 第一种:in-memory with ephemeral。短暂模式,数据保存在内存中,程序一旦结束数据就被销毁。
- 第二种:in-memory with persistance。持久化模式,数据保存在sqlite数据库中,程序结束数据仍然存在。
- 第三种:client/server模式。
本次实践中,主要尝试 持久化模式 和 Client/Server模式。
持久化模式
第一步:安装chroma库
pip install chromadb -i https://pypi.tuna.tsinghua.edu.cn/simple
第二步:创建Chromadb实例
import chromadb
from chromadb import Settings
chroma_client = chromadb.PersistentClient(path="chroma_db")
第三步:创建或获取被查询集合
# 方式一:创建一个新的集合
# collection = chroma_client.create_collection(name="my_collection")
# 方式二:对于已存在的集合,可以直接通过名称获取,如果集合不存在会报错。
# collection = chroma_client.get_collection(name="my_collection")
# 方式三:如果给定名称的集合已经存在则直接获取,否则创建。
collection = chroma_client.get_or_create_collection(name="my_collection")
第四步:添加数据到集合中
collection.add(
ids=["id1", "id2", "id3", "id4", "id5"],
documents=["浙江的省会是杭州", "河北的省会是石家庄", "山东的省会是济南", "杭州是个美丽的城市", "杭州位于浙江省"],
metadatas=[{"source": "myDoc"}, {"source": "myDoc"}, {"source": "myDoc"}, {"source": "myDoc"}, {"source": "myDoc"}],
)
第五步:查询集合中的数据
results = collection.query(
query_texts=["西湖在哪个省?"],
n_results=2,
)
说明:
- query_texts: 查询的文本
- n_results: 查询结果的数量
运行结果:
{'ids': [['id5', 'id1']],
'distances': [[0.669669112082433, 0.6793151914879495]],
'metadatas': [[{'source': 'myDoc'}, {'source': 'myDoc'}]],
'embeddings': None,
'documents': [['杭州位于浙江省', '浙江的省会是杭州']],
'uris': None,
'data': None,
'included': ['metadatas', 'documents', 'distances']}
Client/Server模式
第一步:启动Chroma服务端
chroma run --path my_chroma
说明:
- –path:指定Chroma服务端存储数据的路径。
- –host:可以指定Chroma服务端监听的IP地址,默认localhost
- –port:可以指定Chroma服务端监听的端口号,默认8000
第二步:创建Chromadb实例
import chromadb
from chromadb import Client
from chromadb import Settings
# 配置连接信息
setting = Settings(chroma_server_host="localhost",
chroma_server_http_port=8000)
chroma_client = Client(settings=setting)
第三步:创建或获取被查询集合
collection = chroma_client.get_or_create_collection(name="my_collection")
第四步:添加数据到集合中
collection.add(
ids=["id1", "id2", "id3", "id4", "id5"],
documents=["浙江的省会是杭州", "河北的省会是石家庄", "山东的省会是济南", "杭州是个美丽的城市", "杭州位于浙江省"],
metadatas=[{"source": "myDoc"}, {"source": "myDoc"}, {"source": "myDoc"}, {"source": "myDoc"}, {"source": "myDoc"}],
)
第五步:查询集合中的数据
results = collection.query(
query_texts=["西湖在哪个省?"],
n_results=2,
)
results
运行结果:
{'ids': [['id5', 'id1']],
'distances': [[0.6696690917015076, 0.6793153882026672]],
'metadatas': [[{'source': 'myDoc'}, {'source': 'myDoc'}]],
'embeddings': None,
'documents': [['杭州位于浙江省', '浙江的省会是杭州']],
'uris': None,
'data': None,
'included': ['metadatas', 'documents', 'distances']}
对比 本地持久化 和 Client/Server模式,两者的使用过程基本一致,只是在Client实例化时略有不同。
- 本地持久化模型:
chroma_client = chromadb.PersistentClient(path="chroma_db") - Client/Server模式:首先配置
Settings连接信息,然后调用chroma_client = Client(settings=setting)
查看chromadb的源码,可以看到其内部实现了DB常见的各类增删改查操作:
备注:实际项目产品开发中,知识库需要通过上述的chromadb实现知识库的管理(增删改查)。
通过Langchain的组合包使用Chroma
除了上述chromadb的方式,也可以使用Langchain_chroma的方式使用Chroma,两者的使用场景区别是:
chromadb:
- 自定义应用:当开发者需要构建特定的应用,且对数据库的操作有较高的灵活性需求时,可以使用
chromadb。 - 数据分析:需要对存储的数据进行复杂查询和分析时,使用底层接口可以更好地满足需求。
- 高性能需求:在需要优化性能的情况下,开发者可以通过底层接口进行更细致的调整。
langchain_chroma:
- 快速原型开发:当开发者希望快速构建原型或 MVP(最小可行产品)时,
langchain_chroma提供了便捷的接口。 - NLP检索:提供更高层次的抽象,适用于检索类任务,如文档检索、语义搜索等。
具体使用方法:
from langchain.text_splitter import CharacterTextSplitter
from langchain_chroma import Chroma
from langchain.document_loaders import PyMuPDFLoader
from chromadb import Settings
from utils import get_ernie_models
from utils import get_qwen_models
# 连接大模型
llm_qwen, chat_qwen, embed_qwen = get_qwen_models()
llm_ernie, chat_ernie, embed_ernie = get_ernie_models()
# 加载文档
pdf_loader = PyMuPDFLoader("testfiles/西游记.pdf")
documents = pdf_loader.load()
# 切分文档
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=32)
docs = text_splitter.split_documents(documents)
# 配置连接信息
client = chromadb.HttpClient(host='localhost', port=8000)
chroma_db = Chroma(
embedding_function=embed_qwen,
client=client
)
batch_size = 6 # 每次处理的样本数量
# 分批入库
for i in range(0, len(docs), batch_size):
batch = docs[i:i + batch_size] # 获取当前批次的样本
chroma_db.add_documents(documents=batch) # 入库
# 查询
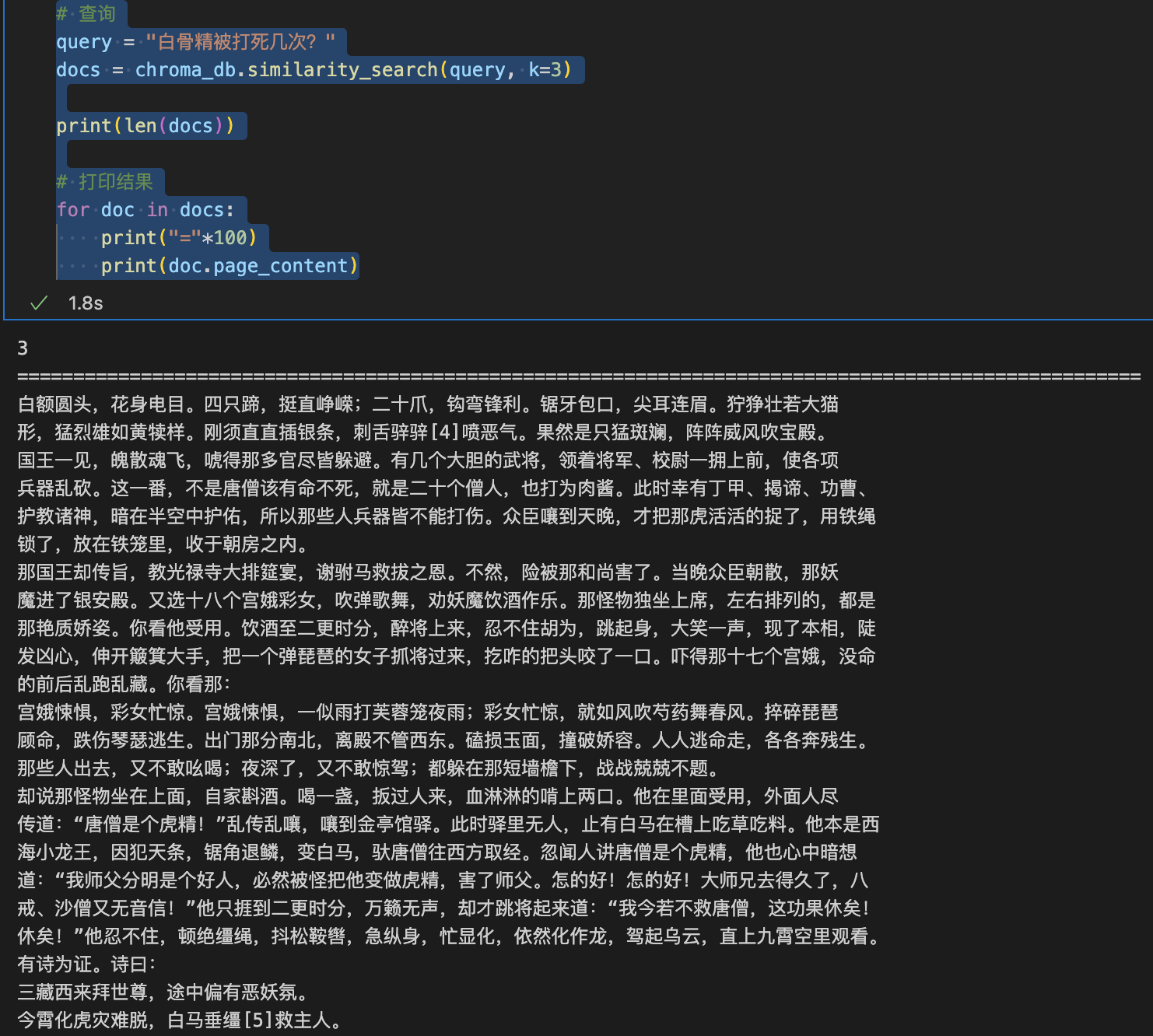
query = "白骨精被打死几次?"
docs = chroma_db.similarity_search(query, k=3)
print(len(docs))
# 打印结果
for doc in docs:
print("="*100)
print(doc.page_content)
运行结果:
说明:
- 在langchain_chroma中,通过client_settings参数,可以l连接Chroma服务端。
- 在Chroma中,通过add_documents方法,可以批量入库;不过对于西游记这样的小说来说,入库时间比较长,约5分钟。
西游记可以从夸克网盘:西游记下载
通过Retriever检索器的方式使用Chroma
在实际项目开发中,一般需要将Chroma的向量库作为检索器(Retriever)与模型组成chain链,以实现问答系统的问答能力。
使用方法
在上述Langchain_chroma的代码基础上,增加以下代码:
retriever = chroma_db.as_retriever(search_type="similarity_score_threshold",
search_kwargs={"k": 4, "score_threshold": 0.1})
retriever.invoke(input="白骨精被打死几次?")
运行结果:

函数说明:
1、as_retriever:
功能:as_retriever 方法将 Chroma 数据库转换为一个检索器(retriever),使其能够根据给定的查询进行文档检索。这个检索器可以使用不同的搜索类型和参数来优化检索结果。
参数
search_type: 指定检索的类型。常见的选项包括:"similarity_score_threshold":根据相似度分数进行检索,只有超过指定阈值的结果才会被返回。
search_kwargs: 包含与搜索相关的额外参数。常用参数包括:k: 指定要返回的最相关文档的数量。例如,k=4 表示返回前 4 个相关文档。score_threshold:设置相似度分数的阈值。只有相似度分数高于该阈值的文档才会被返回。例如,score_threshold=0.1 表示返回分数大于 0.1 的文档。
2、invoke:
功能:invoke 方法用于执行实际的检索操作,根据提供的输入查询返回相关的文档。
参数:
input:要查询的输入文本。
内容小结
- RAG的建库的整体流程为:文档读取(LOAD) -> 文档切分(SPLIT) -> 向量化(EMBED) -> 存储(STORE)
- 在文档读取(LOAD)时:
- langchain_community.document_loaders有多个加载器,可以加载多种格式的文件,如PDF、EXCEL、PPT、WORD、MARKDOWN、HTML等。
- 在文档切分(SPLIT)时:
- 有字符级切分、递归方式切分、Token方式切分等,一般情况可以使用递归RecursiveCharacterTextSplitter切分。
- 使用TokenTextSplitter切分时,注意选择对应的encoding_name,如:‘o200k_base’。
- 对于Markdown文档,可以使用MarkdownTextSplitter。
- 在向量化(EMBED)时:
- 有在线化和本地化,对于数据敏感有本地化部署的情况下,需要考虑使用本地模型进行向量化的方案。
- 在线的向量化有HuggingFaceEmbeddings和第三方模型(如:QianfanEmbeddings)
- 在技术原理层面,计算
知识与查询相似度一般使用的是欧式距离。
- 在存储(STORE)时:
- 可供选择的向量数据库有多种,其中较为常用的是Chroma。
- Chroma支持多种运行方式:短暂模式、持久化模式和Client/Server模式。
- 使用chromadb的原生接口,可以进行增删改查等操作,适用于知识的管理。
- 使用langchain_chroma,可以快速原型开发,适用于检索类任务。
- 使用retriever,可以将Chroma的向量库作为检索器(Retriever),与模型组成chain链,实现问答系统的问答能力。















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









