






前言
通过前几章的学习,我们已经掌握连接一个第三方大模型,使用LangChain与大模型建立交互,并且通过Prompt进行提问,得到相应的回答。本章我们将开始了解RAG(检索增强生成)技术,了解RAG的技术原理以及基本使用方法。
RAG概述
产生背景
随着信息量的急剧增加,单纯依靠模型内置的知识进行生成已无法满足需求,比如:
- 大模型的公共知识都是陈旧的!
- 部分私有的知识大模型没有学习过…
RAG(检索增强生成)技术的出现是为了应对传统生成模型在处理大规模知识时的局限性,其结合了信息检索与生成模型的优势,能够在生成过程中动态地从外部知识库中检索相关信息,从而提高生成内容的准确性和丰富性。
私有知识注入方式有两种:
- 方法一:(学习式)知识注入:模型微调(fine-tuning)
- 方法二:(外挂式)知识注入:RAG system
技术原理
RAG 的核心思想是:将信息检索与文本生成结合起来。
RAG的本质
RAG(Retrieval Augmented Generation),其大量借鉴了推荐系统的一些基本思想。
- R:Retrieval 检索
- A:Augmentated 增强
- G:Generation 生成
RAG的使用工作流程
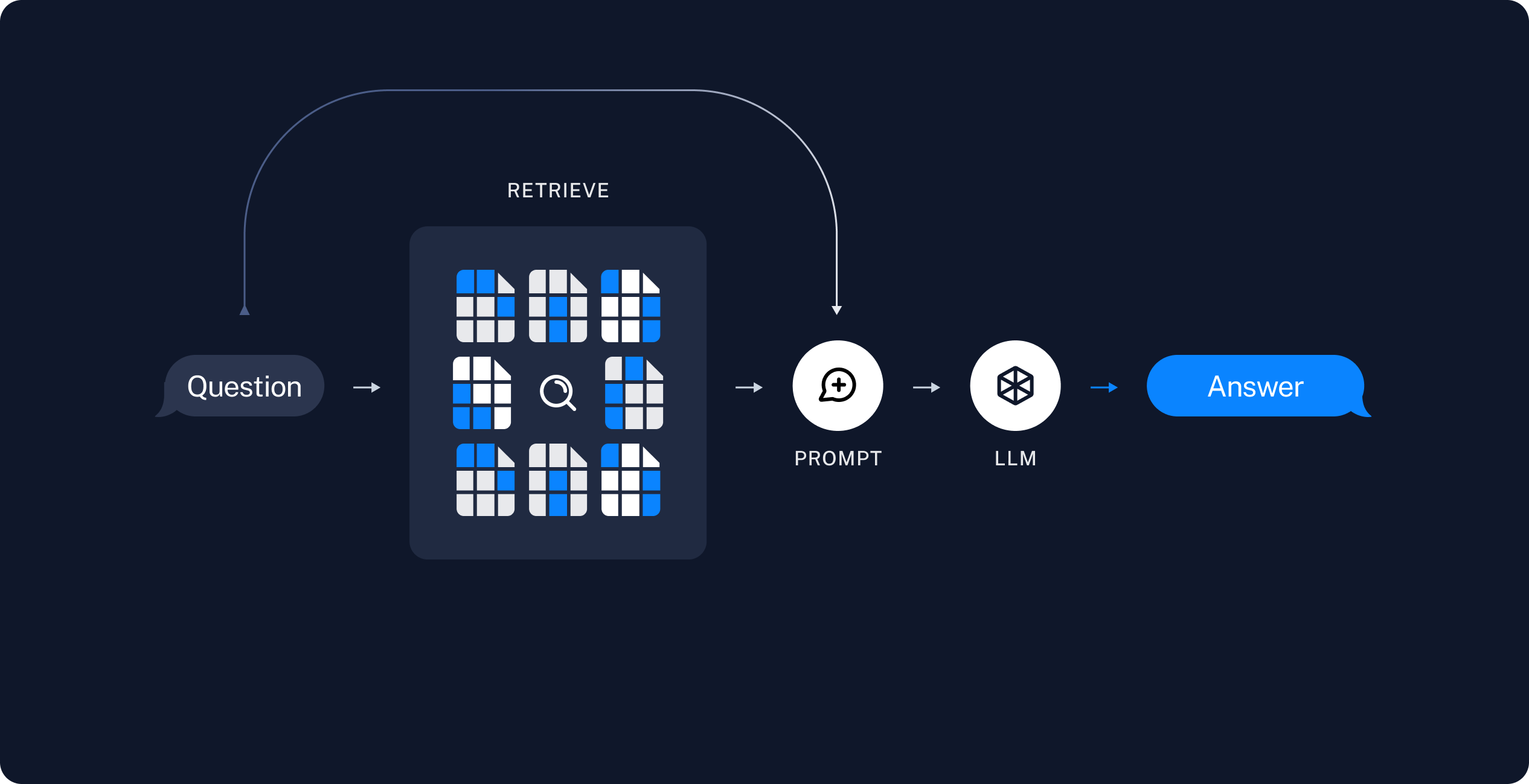
- 用户提出问题:
用户输入查询(query),例如一个问题或请求。 - 问题交给检索器:
系统将用户的查询发送给检索模块(retriever)。 - 检索相关上下文:
检索器根据向量化比对,从知识库中找到与查询相关的上下文信息(context)。 - 聚合查询和上下文:
将用户的查询与检索到的上下文信息结合,通过提示(prompt)进行聚合,形成新的输入:query+context。 - 交给大模型处理:
将聚合后的结果输入到大型语言模型(LLM)。 - 生成答案:
大模型参考上下文信息,生成对用户查询的回答(answer)。
输入/输出概述:
- 输入:
query - 处理:
query-->retriever-->context - 输出:
query+context-->LLM-->answer
RAG的知识库构建流程
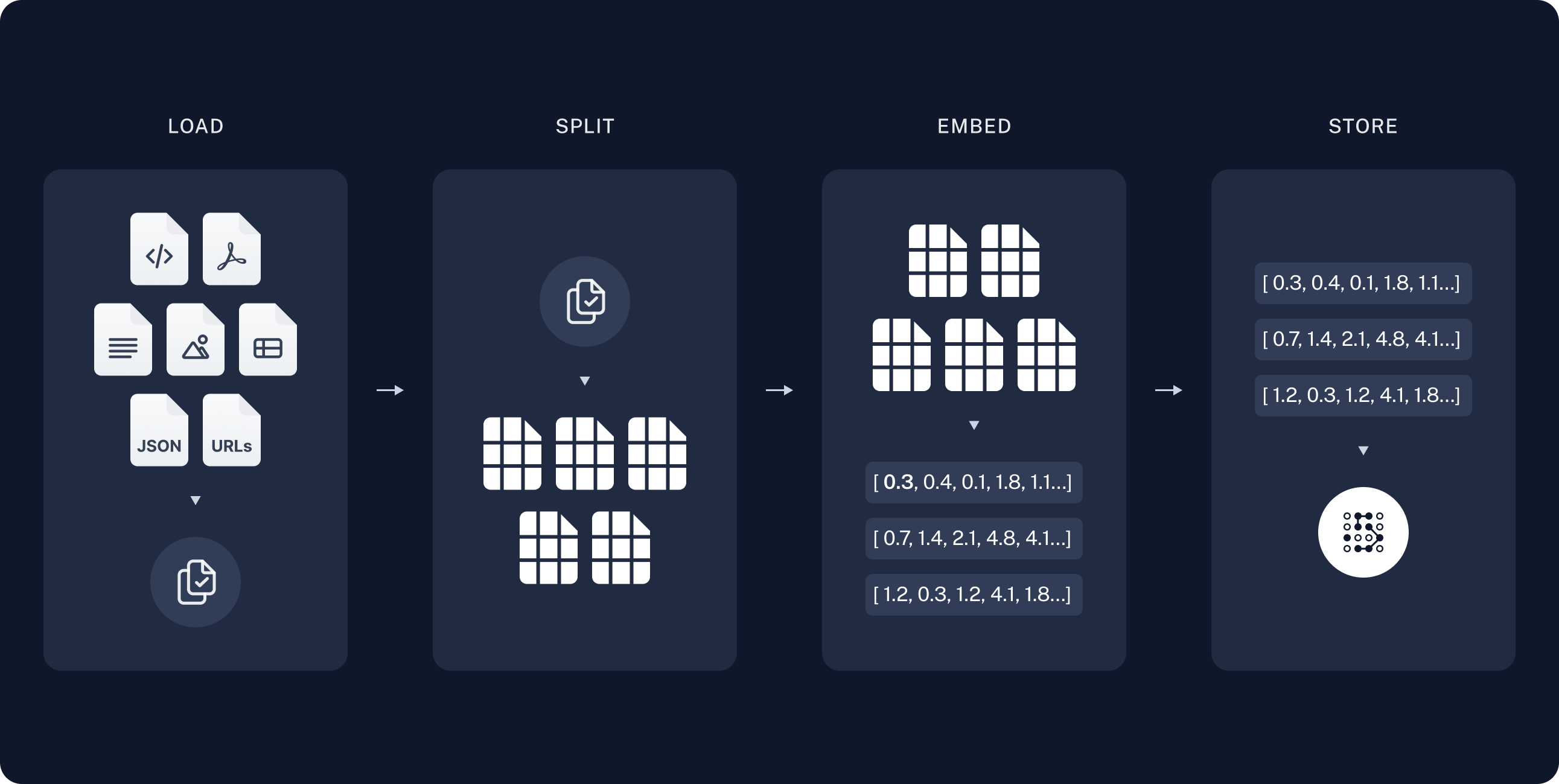
- LOAD:整理知识语料
- 输入格式:支持多种格式,包括 PDF、Word、文本文件、CSV、PPT、SQL 等。
- 文本抽取:从输入文件中抽取文本内容,去除所有图表、音频、视频等多媒体元素,确保只保留纯文本。
- SPLIT:文本分段
- 分段逻辑:将文本划分为语义相对独立的段落,以便于后续处理。
- 向量化要求:确保每个段落符合向量化模型的实际需求,避免过长或过短的文本段落。
- EMBED:向量化
- 向量化模型:使用特定的向量化模型(如
bge-large-zh-v1.5或BAAI)将文本段落转换为向量表示。 - 维度:生成的向量通常为
1024维度,便于后续的相似度计算和检索。
- 向量化模型:使用特定的向量化模型(如
- STORE: 存储至向量数据库
- 向量库:
Chroma是一个开源的向量数据库,支持向量检索和向量相似度计算。 - 数据库架构:采用
CS(Client-Server)架构,以支持高效的检索和查询,一般需要搭建集群。
- 向量库:
所需物料概述:
- 向量数据库
- 向量化模型
- 大语言模型
- 大量知识语料
使用方法
安装依赖
pip install bs4
pip install langchain_chroma
关于Langchain其他组件的安装(如:langchain_community等),非本章内容重点,所以不做赘述。
具体使用
第一步:连接大模型
from utils import get_ernie_models
from utils import get_qwen_models
llm, chat, embed = get_qwen_models()
第二步:导入必要的库和包
# 解析 Web 页面的库(用面向对象的方式来封装 HTML 页面)
import bs4
# hub 生态中心
from langchain import hub
# 引入 Chroma 向量库
from langchain_chroma import Chroma
# 在线加载网页
from langchain_community.document_loaders import WebBaseLoader
# 输出解析器
from langchain_core.output_parsers import StrOutputParser
# 可执行的占位符
from langchain_core.runnables import RunnablePassthrough
# 文档切分器
from langchain_text_splitters import RecursiveCharacterTextSplitter
第三步:选择爬取的页面并加载数据
loader = WebBaseLoader(
web_paths=("https://17aitech.com/?p=14624",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("ast-breadcrumbs", "site-content", "md-post-toc")
)
),
)
# 加载数据
docs = loader.load()
补充说明:
- LangChain 官网提供的示例代码是一篇英文博客,查看效果不太直观,本例中的博客地址换成了我的博客文章。
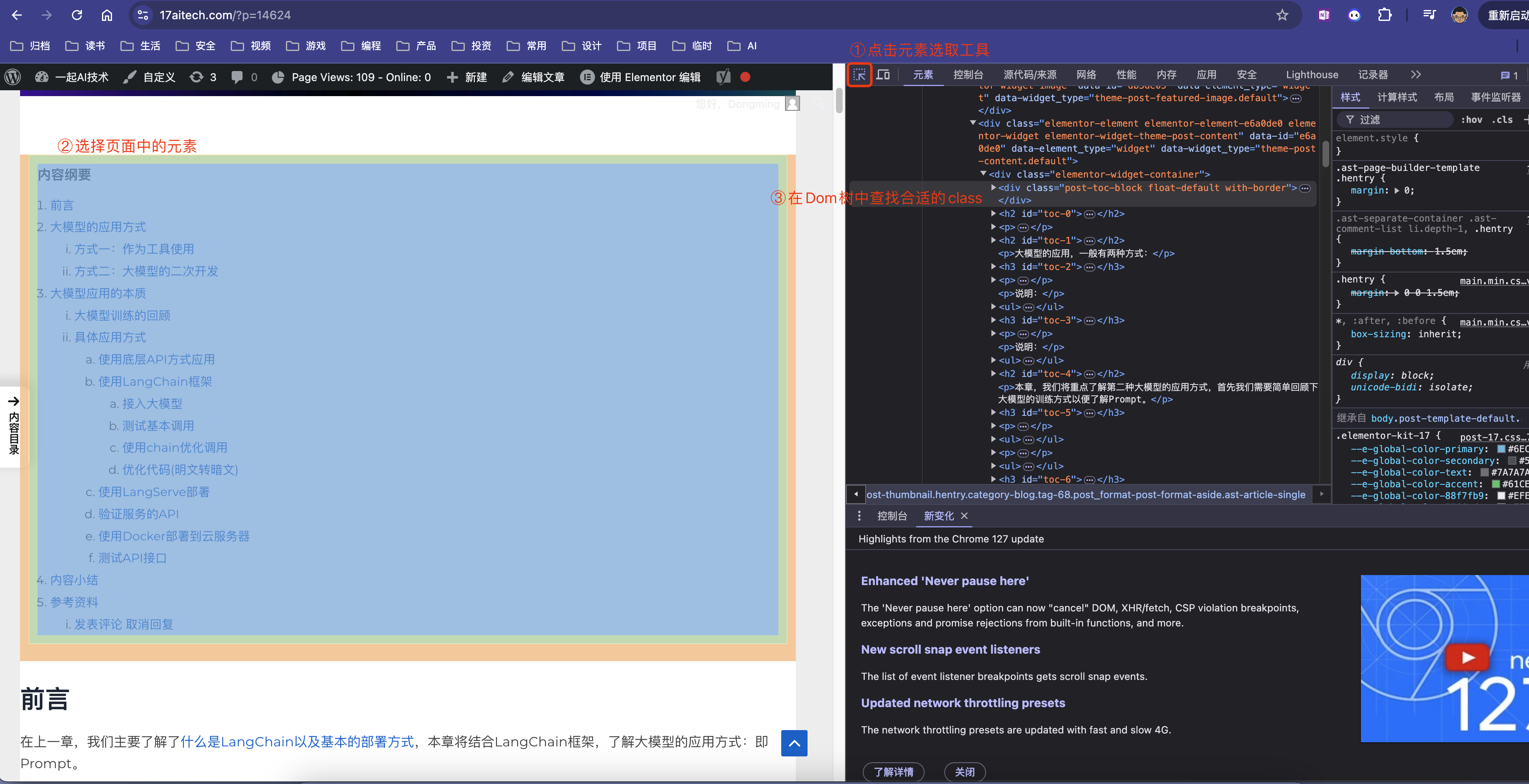
- 上述class的标签,可以通过浏览器的开发者工具找到,例如:
第四步:文本分割
# 递归式 字符级 文本 切分器
"""
chunk_size: 建议段落大小
"""
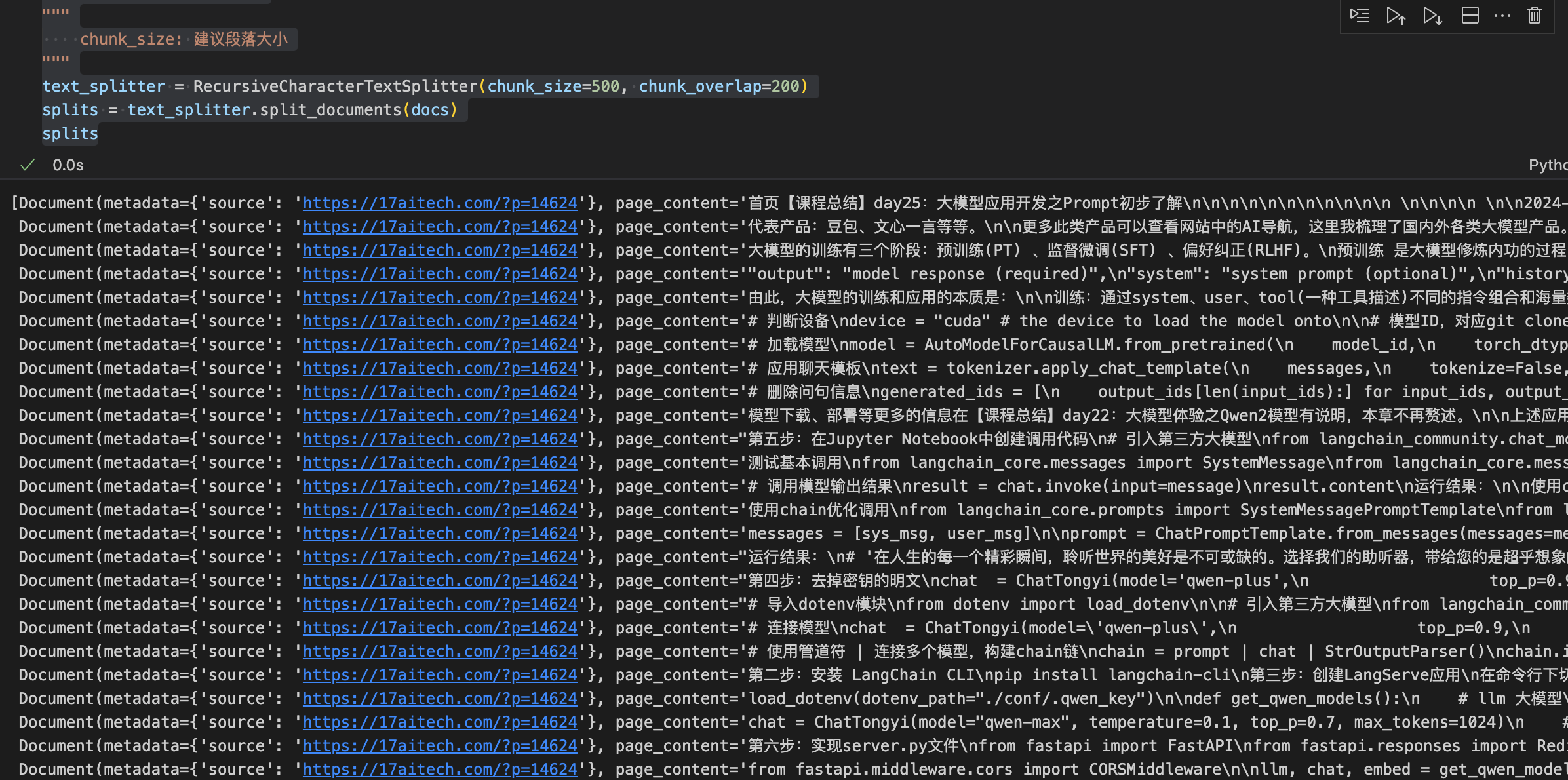
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
splits
运行效果:
第五步:向量化并入库
batch_size = 6 # 每次处理的样本数量
vectorstore = Chroma(embedding_function=embed) # 初始化 Chroma 向量数据库并提供嵌入函数
# 分批入库
for i in range(0, len(splits), batch_size):
batch = splits[i:i + batch_size] # 获取当前批次的样本
vectorstore.add_documents(documents=batch) # 入库
由于阿里提供的embed接口,一次只能处理6个样本,所以需要分批入库。
第六步:RAG系统搭建
# 把向量操作封装为一个基本检索器
retriever = vectorstore.as_retriever()
第七步:构造RAG系统的Prompt(核心部分)
from langchain_core.prompts import ChatPromptTemplate
# RAG系统经典的 Prompt (A 增强的过程)
prompt = ChatPromptTemplate.from_messages([
("human", """You are an assistant for question-answering tasks. Use the following pieces
of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:""")
])
第八步:构建RAG链
def format_docs(docs):
"""
将检索到的文档列表格式化为一个大字符串。
参数:
docs (list): 包含文档对象的列表,每个文档对象应具有 `page_content` 属性。
返回:
str: 一个由文档内容组成的大字符串,文档之间用两个换行符分隔。
"""
return "\n\n".join(doc.page_content for doc in docs)
# RAG 链
rag_chain = (
{"context": retriever | format_docs,
"question": RunnablePassthrough()}
| prompt
| chat
| StrOutputParser()
)
第九步:提问问题,测试RAG系统
rag_chain.invoke(input="Prompt初步了解文章中,作者示例中的Langserve接口的IP地址是多少?")
运行结果:

通过查看文章【课程总结】day25:大模型应用开发之Prompt初步了解中测试API接口章节,其中我部署到云服务器的IP地址的确为上述地址。
内容小结
- RAG系统是一种基于大语言模型的问答系统,通过向量检索和向量化技术,实现对海量知识资源的高效检索和问答。
- RAG的知识库构建流程为:整理知识语料(
LOAD)-> 文本分段(SPLIT)-> 向量化(EMBED) -> 存储至向量数据库(STORE)。 - RAG的使用流程为:用户提出问题(
query) -> 问题交给检索器(retriever)-> 检索相关上下文(context) -> 聚合查询和上下文(query+context) -> 交给大模型处理(LLM) -> 生成答案(answer) - RAG的核心部分:即通过构建一个
Prompt,该Prompt包含{question}用户提出的问题 和{context}向量库中检索到的上下文,然后交给大模型,让大模型根据上下文给出Answer。















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









