







Apache Storm 简介
Apache Storm 的前身是 Twitter Storm 平台,目前已经归于 Apache 基金会管辖。Apache Storm 是一个免费开源的分布式实时计算系统。简化了流数据的可靠处理,像 Hadoop 一样实现实时批处理。Storm 很简单,可用于任意编程语言。Apache Storm 采用 Clojure 开发。Storm 有很多应用场景,包括实时数据分析、联机学习、持续计算、分布式 RPC、ETL 等。Storm 速度非常快,一个测试在单节点上实现每秒一百万的组处理。
1、Storm集群架构
Storm集群采用主从架构方式,主节点是Nimbus,从节点是Supervisor,有关调度相关的信息存储到ZooKeeper集群中,架构如下图所示: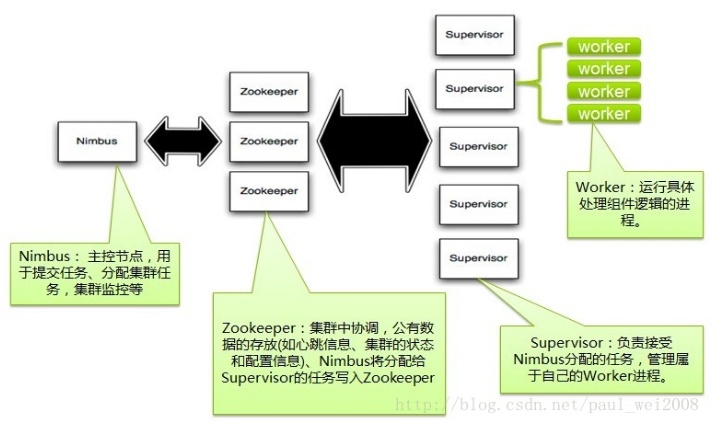
Nimbus
Storm集群的Master节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点,去运行Topology对应的组件(Spout/Bolt)的Task。
Supervisor
Storm集群的从节点,负责管理运行在Supervisor节点上的每一个Worker进程的启动和终止。通过Storm的配置文件中的supervisor.slots.ports配置项,可以指定在一个Supervisor上最大允许多少个Slot,每个Slot通过端口号来唯一标识,一个端口号对应一个Worker进程(如果该Worker进程被启动)。
ZooKeeper
用来协调Nimbus和Supervisor,如果Supervisor因故障出现问题而无法运行Topology,Nimbus会第一时间感知到,并重新分配Topology到其它可用的Supervisor上运行。
2、运行组件
Strom在运行中可分为spout与bolt两个组件,其中,数据源从spout开始,数据以tuple的方式发送到bolt,多个bolt可以串连起来,一个bolt也可以接入多个spot/bolt.运行时原理如下图
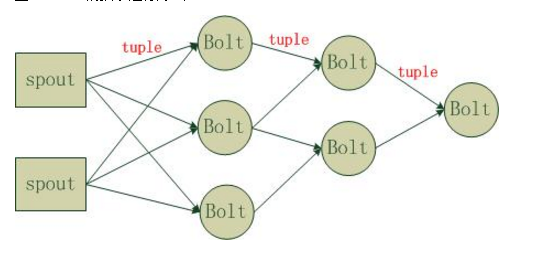
其中,各组件定义如下
Spout: 数据源,源源不断的发送元组数据 Tuple
Tuple: 元组数据的抽象接口,可以是任何类型的数据。但是必须要可序列化。
Stream: Tuple的集合。一个 Stream内的 Tuple拥有相同的源。
Bolt: 消费Tuple的节点。消费后可能会排出新的 Tuple到该 Stream上,也可能会排到到其他 Stream,也或者根本不排。可并发。
Topology: 将 Spout、 Bolt整合起来的拓扑图。定义了 Spout和 Bolt的结合关系、并发数量、配置等等。
3、Topology具体运行
在上面Spout和Bolt组成一个Topology,然后通过命令将这个Topology打包成jar包,启动相关命令启动应用就可以了,一个Storm在集群上运行一个Topology时,主要通过以下3个实体来完成Topology的执行工作:
(1). Worker(进程)
(2). Executor(线程)
(3). Task
下图简要描述了这3者之间的关系:
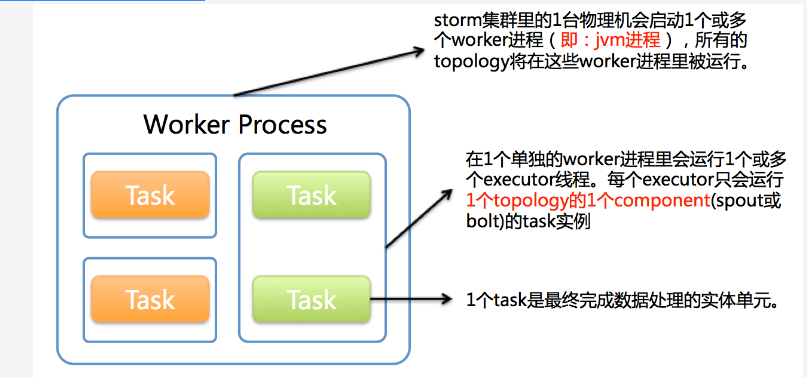
1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
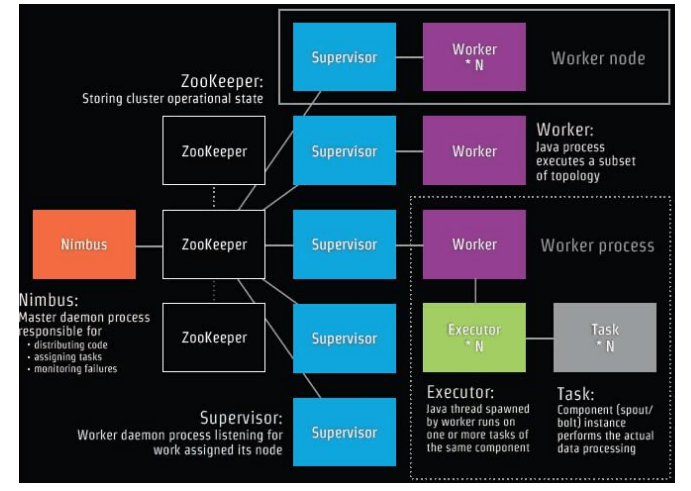
总体的Topology处理流程图为:
4、Stream Groupings
Storm中最重要的抽象,应该就是Stream grouping了,它能够控制Spot/Bolt对应的Task以什么样的方式来分发Tuple,将Tuple发射到目的Spot/Bolt对应的Task
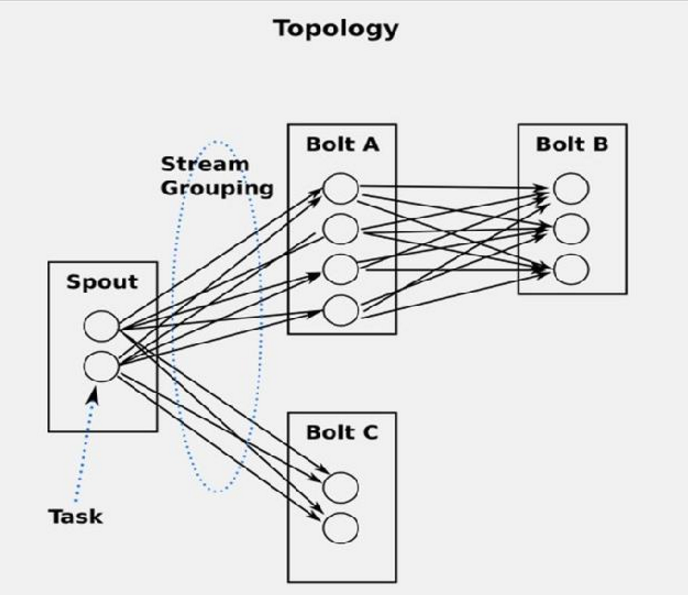
目前,Storm Streaming Grouping支持如下几种类型:
Shuffle Grouping :随机分组,尽量均匀分布到下游Bolt中
将流分组定义为混排。这种混排分组意味着来自Spout的输入将混排,或随机分发给此Bolt中的任务。shuffle grouping对各个task的tuple分配的比较均匀。
Fields Grouping :按字段分组,按数据中field值进行分组;相同field值的Tuple被发送到相同的Task
这种grouping机制保证相同field值的tuple会去同一个task,这对于WordCount来说非常关键,如果同一个单词不去同一个task,那么统计出来的单词次数就不对了。“if the stream is grouped by the “user-id” field, tuples with the same “user-id” will always go to the same task”. —— 小示例
All grouping :广播
广播发送, 对于每一个tuple将会复制到每一个bolt中处理。
Global grouping :全局分组,Tuple被分配到一个Bolt中的一个Task,实现事务性的Topology。
Stream中的所有的tuple都会发送给同一个bolt任务处理,所有的tuple将会发送给拥有最小task_id的bolt任务处理。
None grouping :不分组
不关注并行处理负载均衡策略时使用该方式,目前等同于shuffle grouping,另外storm将会把bolt任务和他的上游提供数据的任务安排在同一个线程下。
Direct grouping :直接分组 指定分组
由tuple的发射单元直接决定tuple将发射给那个bolt,一般情况下是由接收tuple的bolt决定接收哪个bolt发射的Tuple。这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的taskid (OutputCollector.emit方法也会返回taskid)。
另外,Storm还提供了用户自定义Streaming Grouping接口,如果上述Streaming Grouping都无法满足实际业务需求,也可以自己实现,只需要实现backtype.storm.grouping.CustomStreamGrouping接口,该接口重定义了如下方法:
List chooseTasks(int taskId, List values)
上面几种Streaming Group的内置实现中,最常用的应该是Shuffle Grouping、Fields Grouping、Direct Grouping这三种,使用其它的也能满足特定的应用需求。
5、可靠性
(1)、spout的可靠性spout会记录它所发射出去的tuple,当下游任意一个bolt处理失败时spout能够重新发射该tuple。在spout的nextTuple()发送一个tuple时,为实现可靠消息处理需要给每个spout发出的tuple带上唯一ID,并将该ID作为参数传递给SpoutOutputCollector的emit()方法:collector.emit(new Values("value1","value2"), tupleID);
实际上Values extends ArrayList<Object>
保障过程中,每个bolt每收到一个tuple,都要向上游应答或报错,在tuple树上的所有bolt都确认应答,spout才会隐式调用ack()方法表明这条消息(一条完整的流)已经处理完毕,将会对编号ID的消息应答确认;处理报错、超时则会调用fail()方法。
(2)、bolt的可靠性
bolt的可靠消息处理机制包含两个步骤:
a、当发射衍生的tuple,需要锚定读入的tuple
b、当处理消息时,需要应答或报错
可以通过OutputCollector中emit()的一个重载函数锚定或tuple:collector.emit(tuple, new Values(word)); 并且需要调用一次this.collector.ack(tuple)应答。
6、高性能并行计算引擎Storm和Spark比较
Spark基于这样的理念,把计算过程传递给数据要比把数据传递给计算过程要更富效率。每个节点存储(或缓存)它的数据集,然后任务被提交给节点。每次输入是一次性将所有数据分部到各机器节点读入,通过内存计算将结果RDD临时保存内存中。一次跑批将所有的任务根据惰性RDD的区别来拆解不现的stage,下一个的stage的输入为上一个stage的输出。这一过程全部都是在内存中完成。(内存不足也可以硬盘)所以这是把过程传递给数据。这和Hadoop map/reduce非常相似,除了积极使用内存来避免I/O操作,以使得迭代算法(前一步计算输出是下一步计算的输入)性能更高。而Storm的架构和Spark截然相反。Storm是一个分布式流计算引擎。每个节点实现一个基本的计算过程,而数据项在互相连接的网络节点中流进流出。和Spark相反,这个是把数据传递给过程。Strom任务提交后组成一个Topology,会一直不断的取数据进行处理,如果没有执行停止命令,任务不会停止。而Spak可以当成是一次性的(spark streaming不是一次性的)任务。数据处理完后任务就结束。
两个框架都用于处理大量数据的并行计算。
Storm在动态处理大量生成的“小数据块”上要更好(比如在Twitter数据流上实时计算一些汇聚功能或分析)。
Spark工作于现有的数据全集(如Hadoop数据)已经被导入Spark集群,Spark基于in-memory管理可以进行快讯扫描,并最小化迭代算法的全局I/O操作。
不过Spark流模块(Streaming Module)倒是和Storm相类似(都是流计算引擎),尽管并非完全一样。
Spark流模块先汇聚批量数据然后进行数据块分发(视作不可变数据进行处理),而Storm是只要接收到数据就实时处理并分发。
不确定哪种方式在数据吞吐量上要具优势,不过Storm计算时间延迟要小。
总结下,Spark和Storm设计相反,而Spark Steaming才和Storm类似,前者有数据平滑窗口(sliding window),而后者需要自己去维护这个窗口。
参考文章:
http://blog.csdn.net/paul_wei2008/article/details/20830329
https://yq.aliyun.com/articles/27677
http://www.sxt.cn/u/756/blog/4641
http://www.cnblogs.com/yufengof/p/storm-worker-executor-task.html
http://blog.csdn.net/u012721013/article/details/53424638














 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









