







一、Storm简介
Storm是一个免费并开源的分布式实时计算系统。利用Storm可以很容易做到可靠地处理无限的数据流,像Hadoop批量处理大数据一样,Storm可以实时处理数据。
Storm 很简单,可用于任意编程语言。Apache Storm 采用 Clojure 开发。Storm 有很多应用场景,包括实时数据分析、联机学习、持续计算、分布式 RPC、ETL 等。
Hadoop(大数据分析领域无可争辩的王者)专注于批处理。这种模型对许多情形(比如为网页建立索引)已经足够,但还存在其他一些使用模型,它们需要来自高度动态的来源的实时信息。为了解决这个问题,就得借助 Nathan Marz 推出的 storm(现在已经被Apache孵化)storm 不处理静态数据,但它处理连续的流数据。
storm特点:
- 编程简单:开发人员只需要关注应用逻辑,而且跟Hadoop类似,Storm提供的编程原语也很简单
- 高性能,低延迟:可以应用于广告搜索引擎这种要求对广告主的操作进行实时响应的场景。
- 分布式:可以轻松应对数据量大,单机搞不定的场景
- 可扩展: 随着业务发展,数据量和计算量越来越大,系统可水平扩展
- 容错:单个节点挂了不影响应用
- 消息不丢失:保证消息处理
1.Storm用于实时计算,Hadoop用于离线计算。
2. Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批。
3. Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。
4. Storm与Hadoop的编程模型相似
| 结构 | Hadoop | Storm |
|---|---|---|
| 主节点 | JobTracker | Nimbus |
| 从节点 | TaskTracker | Supervisor |
| 应用程序 | Job | Topology |
| 工作进程名称 | Child | Worker |
| 计算模型 | Map / Reduce | Spout / Bolt |
二、Storm集群架构
Storm集群采用主从架构方式,主节点是Nimbus,从节点是Supervisor,有关调度相关的信息存储到ZooKeeper集群中,架构如下图所示:
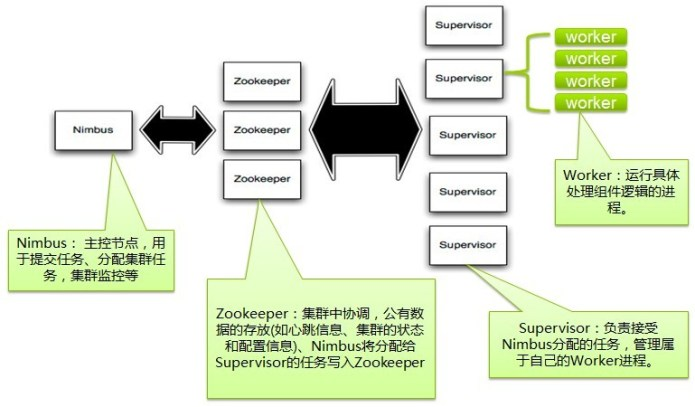
Nimbus
Storm集群的Master节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点,去运行Topology对应的组件(Spout/Bolt)的Task。
Supervisor
Storm集群的从节
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 473
473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









