







利用单目视觉实现对目标的位姿估算,比较经典的算法有POSIT和正交迭代OI算法。这些算法大多是利用几何特征的先验信息(几何特征点在物体坐标系下的绝对位置),通过建立这些特征点在物体坐标系下与实际图像上对应特征的映射关系,求解出f(x)的非线性最小二乘解来逼近得到最终的位姿矩阵T。其中,f(x)的目标函数为:
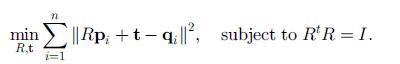
E. Marchand于2002年提出了基于虚拟视觉伺服(vitural visual servoing,VVS)的位姿估算框架。第一次见到这个框架是在2013年IROS上的一篇文章上看到:High Speed/Accuracy Visual Servoing based on Virtual Visual Servoingwith Stereo Cameras。但是现在想想,由于当时对视觉伺服技术一直是以实际的机器人平台进行研究的,没有对视觉伺服的仿真有太多了解,因此并没有深刻的理解这种位姿估算方法。直到接触到了peter corke的机器视觉工具箱后,才算彻底的搞明白VVS框架及如何在实际的位姿估算中使用VVS。
一. 预备知识
为了具体了解VVS框架,首先回顾一下视觉伺服的基本原理。这里主要考虑手眼系统下的IBVS(基于图像的视觉伺服框架),并且视觉特征以特征点为例。
简单来说,视觉伺服IBVS就是观测当前图像上的特征点与期望状态下图像上对应特征点之间的误差e,通过图像雅克比矩阵L计算出此时摄像机(机器人末端执行器)的运动参数v:
![[v=-L \cdot e]](https://img-blog.csdn.net/20160418222329935)
在实际的应用中,当计算出运动参数v后控制机器人带动摄像机运动,此时图像上的特征点像素位置也随之发生变化,利用新的特征点再次计算运动参数v…通过多次迭代这一过程,最终当前图像上的特征点与期望状态下图像上对应特征点完全重合,机器人运动到期望姿态。
二. 利用VVS实现位姿估算
为了便于理解,这里首先给出利用VVS估算位姿的前提条件(已知信息):
1. 当前需要求取位姿的摄像机图像,记为image
2. 一个给定的参考状态下目标与摄像机的相对位姿T,参考状态即为s
3. 目标(特征)对应的3D模型信息(在后面的扩展部分中,模型信息并不是必要的)
对应于视觉伺服任务中,VVS就是利用视觉伺服控制技术逐渐迭代地修改一个“虚拟”的摄像机的位姿,使得这个摄像机从给定的参考状态s逐渐运动到最终状态s*,并且在这个最终状态s*下,目标(特征)对应的3D模型信息在投影到“虚拟”摄像机的图像上时与当前需要求取位姿的实际的图像特征能够完全吻合。
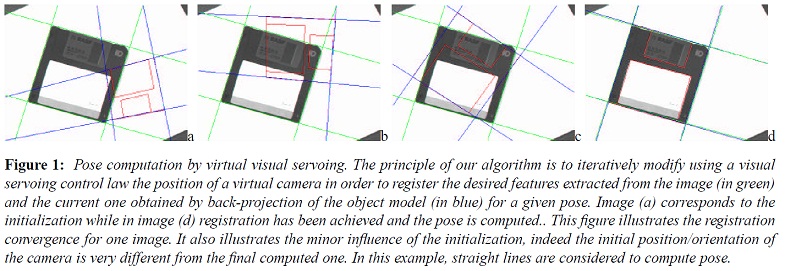
下图给出了作者的一个实例,绿线为当前实际的目标特征,蓝色直线为目标模型经过投影后在“虚拟”的摄像机图像上的特征,最终两个特征完全重合,此时“虚拟”的摄像机与实际的摄像机也完全重合,因此,“虚拟”的摄像机此时与目标的相对位姿即为所求。
这一过程一开始看起来有点绕,并且需要目标模型啊投影啊什么的,很容易让人发憷。实际上当理解了VVS进行位姿估算的核心思想后,它的代码是相当简洁的。下面以一个具体的伪代码进行说明:
给定空间中4个点的三维位置信息P(物体坐标系下),摄像机内参K,参考状态下目标与摄像机的相对位姿T。当前需要求取位姿的图像中,其对应4个点的特征为s,要求取的位姿为T*,VVS的流程如下:

三. VVS框架的扩展
在第二部分中,我们假定了已知目标的3D信息,因而可以在摄像机的坐标系下将目标特征投影到“虚拟”摄像机的图像上。实际上,在更多的应用场合中我们不知道目标的3D信息,因而,VVS的原作者提出了对这类场景的VVS扩展方法。
在无模型场景下,以特征点作为视觉输入特征,在利用VVS对摄像机的运动参数更新后,求解摄像机的姿态变化,得到新的姿态。由于此时目标模型未知,因此不能利用模型投影的方式得到新的“虚拟”图像特征。作者根据极线几何约束和基础矩阵,针对纯平面的场景或摄像机发生纯旋转运动的情况,利用单应性矩阵H来更新这些图像特征(这也是为什么说作者只利用2D图像特征和图像本身固有的几何约束性质)。 图像特征更新前后p1和p2与矩阵H的关系满足:
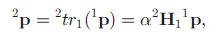
其中,单应性矩阵通过更新得到的位姿矩阵T求得:
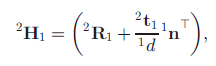
在这样一些估算投影特征的场景下,为了更好的克服图像上特征误差的影响,可以采用在两幅图像上同时定义VVS的目标函数,通过同时极小化前向投影误差和后向投影误差实现对两幅图像间位姿变化的逼近。最终,根据更新后的图像特征,进入下一次VVS迭代。
此外,作者在论文的后半部分还扩展了摄像机内参数未知的情况,也能实现对目标的位姿估算。
更为具体的情况可以参见原作论文。
四. VVS的优点
1. 由于VVS的核心思想来源于视觉伺服技术,因此视觉伺服领域中的图像特征都适用(点、直线、圆、圆柱、面积、轮廓等),而这些特征在传统的位姿估算方法中可能计算非常繁琐;
2. 利用VVS进行位姿估算,对目标的特征可以进行多种组合:如直线+圆,点+直线等。如果组合了多个视觉特征,在对视频进行持续的位姿估算时,即使某一帧的几个特征没有被检测出来,利用剩余的视觉特征同样能够实现对位姿的估算。
参考:
1. Virtual visual servoing: Aframework for real-time augmented reality
2. A New Formulation for NonLinear Camera Calibration Using Virtual Visual Servoing
3. 作者所在雷恩大学的IRISA课题组https://team.inria.fr/lagadic/welcome.html
4. Peter Corke的主页http://www.petercorke.com/Home.html
5. Model-free augmented reality byvirtual visual servoing
6. High Speed Accuracy VisualServoing based on Virtual Visual Servoing with Stereo Cameras














 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









