







论文地址:A-Fast-RCNN
Caffe代码:adversarial-frcnn
前言
近期为了学术汇报,阅读了这篇CVPR 2017论文,该论文将对抗学习的思路应用在目标检测中,通过对抗网络生成遮挡和变形图片样本来训练检测网络,取得了一定的效果。现将论文大意做了翻译和理解,不一定完全对。
摘要
如何使得物体检测器能够应对被遮挡或者变形的图像?我们目前的解决方法是使用数据驱动的策略——收集一个足够大的数据集,能覆盖不同的情况,并希望通过训练能够让分类器学会把它们识别为同一个物体。但是数据集真的能够覆盖所有的情况吗?我们认为像分类、遮挡与变形这样的特性也符合长尾理论。一些遮挡与变形非常罕见,几乎永远不会发生,但我们希望训练出的模型是能够应付所有情况的。本文中,我们提出了一种新的解决方案。使用一种对抗网络来自动生成遮挡和变形的样本。对抗学习的目标是生成检测器难以识别的样本。在我们的框架中,原始检测器与它的对手共同进行学习。实验表明,我们的方法与 Fast-RCNN 相比,在 VOC07 上mAP 提升了 2.3%,在 VOC2012 上 mAP 提升了 2.6%。
介绍
在目标检测任务中,我们常常要求模型能够适应不同的光照条件、遮挡、形变等。标准的做法是使用一个包含各种不同情况的大规模数据集,例如COCO数据集就有10000多个不同遮挡形变情形的汽车样本。我们希望通过足够多的不同场景样本,检测器能学到更好的鲁棒不变性,这也是卷积神经网络能成功用于目标检测任务的重要原因。
然而并没有这么简单,作者认为遮挡和形变的情况也遵循长尾理论,就是说一些遮挡和形变的情况很罕见,几乎不会出现在大规模数据集中,例如图1的一些情况。那么如何学习这些罕见的遮挡和形变呢?使用更大的数据集是一个办法,但是也很难突破长尾理论的限制。

通过对抗学习来生成这种困难正样本在理论上是可行的,但具体方案还要分析。比如方案一:直接学习这些罕见的遮挡形变样本,通过尾部分布生成以假乱真的样本图片,结论是不可行,太过复杂,效果还难说。方案二:生成各种可能的遮挡和形变样本,结论是情况太多,根本不可能完备。作者提出的方案是,不直接生成新的图片,二是在原有图片上“人为”添加遮挡和形变,也算是生成了困难的正样本,让检测器难以进行分类判断。
也就是训练一个生成网络:它在卷积特征图空间上进行操作,通过遮罩特征图的一部分实现空间遮挡,通过操控特征响应来实现空间变形,以这种方式生成困难正样本。Fast R-CNN作为判别网络,是很难对这些样本作出判断的,当然生成网络想要骗过判别网络也很困难。二者在学习中共同提升,最终就提升了检测器的性能。关键问题就是如何在卷积特征空间中创建对抗样本。
相关工作
作者在文中总结,针对目标检测问题,目前学术界主要从三个思路进行探索:
一是设计更好的网络架构来提升性能,主要是使用更深的网络结构,例如 ResNet,Inception-ResNet ,ResNetXt ;
二是结合上下文推理,充分利用各个卷积层的特征;
三是充分利用训练数据来提升性能,例如hard example mining。
本文的工作就属于第三条思路,充分利用现有数据,作者强调工作重点是以更好的方式利用数据,而不是试图筛选数据来寻找困难样本,当然,核心是利用对抗学习生成很难的样本,拿给Fast R-CNN检测,以提升其检测鲁棒性。
用于目标检测的对抗学习
作者的对抗网络是在空间上受到限制:只管遮挡和形变。在数学上,检测器(Fast R-CNN)的损失函数可以如下表示,它是softmax loss和bbox loss的求和。
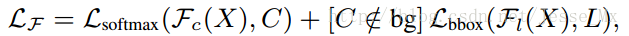
其中, X 是候选目标,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









