







文章提出一个全新的叫做“Network In Network”(NIN)的深度网络结构,加强了模型对接受区域(receptive field)内部块的识别能力。经典的卷积层利用线性滤波器跟着一个非线性激活函数来扫描输入,文章建立了一个结构更复杂的微型神经网络来提取接受区域内的数据,并用多层感知机(更有效的函数逼近器)来实例化这个微型神经网络。通过微型网络来强化局部模型的表达能力,可以在分类层上将全局平均池化(global average pooling)作用在feature map上,这比传统的全连接层更容易解释且不容易过拟合。
CNN中的卷积核通常是一个广义线性模型(generalized linear model:GLM),不过GLM的抽象能力较低。抽象,就是得到对同一概念的不同变体保持不变的特征。GLM在潜在概念是线性可分的情况下能够很好的进行抽象,但是来自相同概念的数据存在于非线性的流行上的,往往需要高度非线性的函数才能对这些概念进行表示。所以,用更有效的非线性函数逼近器来替换GLM能够增强局部模型的抽象能力。
NIN中,用多层感知机实例化的微型网络作为通用的非线性函数逼近器来替换GLM,并且能够用BP来进行训练,将这个结构称为“mlpconv”(多层感知机池化层MLP)。网络结构如下图所示:
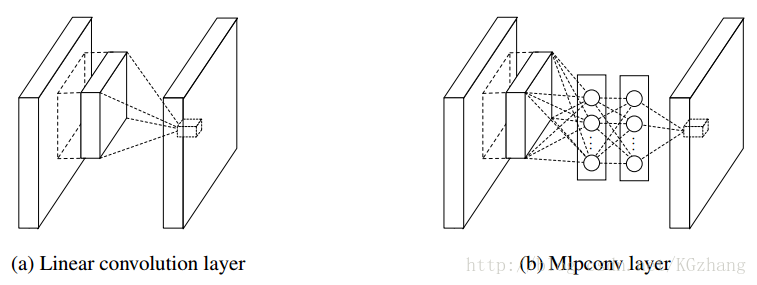
和线性卷积层一样,mlpconv(MLP)将局部感受野映射成一个特征向量作为输出,线性卷积层利用线性核,而MLP包含多个全连接层和非线性激活函数。NIN就是由多个MLP堆叠起来的。后面的分类,和传统CNN采用全连接层不一样,通过一个global average pooling(GAP)层对最后一个mlpconv layer输出的feature map做空间平均得到一个类别的置信度,然后将结果向量送入softmax layer进行分类。
在传统的CNN中,由于全连接层之间的作用就像一个黑匣子,难以解释来自object cost layer的类别级信息如何传播到先前的卷积层。而全局平均池化更容易解释(可将最后一层输出的特征图的空间平均值解释为相应类别的置信度!因为在采用了微神经网络后,让局部模型有更强的抽象能力,从而让全局平均池化能具有特征图与类别之间的一致性!);全连接层由于严重依赖dropout正则化容易发生过拟合,而全局平均池化本身就是一种结构性的规则项,不易过拟合。
dropout正则化:在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是将其权重保留下来(只是暂时不更新而已),因为下次样本输入时它又可以工作了。
hinton在训练阶段和测试阶段使用Dropout时做了如下操作:训练阶段对每个隐含节点的权值L2范数设置一个上限bound,当训练过程中如果该节点不满足bound约束,则用该bound值对权值进行一个规范化操作(即同时除以该L2范数值),说是这样可以让权值更新初始的时候有个大的学习率供衰减,并且可以搜索更多的权值空间;在模型的测试阶段,使用“mean network(均值网络)”来得到隐含层的输出,其实就是在网络前向传播到输出层前时隐含层节点的输出值都要减半(如果dropout的比例为50%)。
经典的卷积神经网络包含了可替换的卷积层和空间池化层。卷积层用线性滤波器对输入图像进行内积运算,在每个局部输出后面跟着一个非线性的激活函数(如rectifier,sigmoid,tanh等),得到的结果叫做特征图(feature map)。下面是ReLU计算feature map的公式:
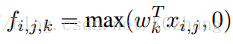
(i,j)是feature map中像素的位置,Xi,j表示以(i,j)为中心的输入块,k表示feature map的通道。
当潜在的数据空间是线性可分的时候,线性卷积能够对数据进行抽象,但要达到很好地抽象程度通常需要高度非线性的函数。单个线性卷积核只能学习到同一概念的不同变体,如果使用大量线性卷积核,那么网络的参数将异常地庞大。所以需要采用非线性卷积来替换线性卷积,文章采用在每个线性卷积层里面加入一个微型网络来对每个局部块计算更抽象的特征。
Network In Network:接下来分别介绍MLP卷积层和GAP层
MLP卷积层:
为了更好地近似出对潜在空间的抽象表示,需要利用更具表达能力的非线性函数近似器来对局部快进行特征提取。比线性模型更好的模型有Radial basis network(径向量网络),multilayer perception(多层感知机),文章采用MLP考虑到其如下的特性:
一、可利用反向传播进行训练,能够与CNN完美融合;
二、多层感知机本身就是一个深度模型,其特征可以再利用;
下面是mlpconv的计算公式:
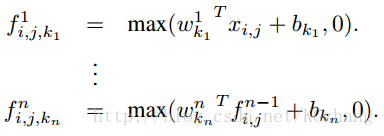
其中n就是多层感知机的个数,ReLU正则化被作为多层感知机的激活函数。
mplconv的网络结构定义如下:
# 前面是正常的卷积操作
# 这里是mlp conv, 可以看出就是一个1*1的卷积操作(等价于全连接操作)
layers {
bottom: "conv1"
top: "cccp1"
name: "cccp1"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
# 接着接一个激活函数
layers {
bottom: "cccp1"
top: "cccp1"
name: "relu1"
type: RELU
}
# 在来一个用1*1的卷积完成的全连接操作
layers {
bottom: "cccp1"
top: "cccp2"
name: "cccp2"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}
# 接对应的激活函数
layers {
bottom: "cccp2"
top: "cccp2"
name: "relu2"
type: RELU
}
# 以上完成了两次非线性映射, 也就是 MLP 操作
layers {
bottom: "cccp2"
top: "pool0"
name: "pool0"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layers {
bottom: "pool0"
top: "conv2"
name: "conv2"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.05
}
bias_filler {
type: "constant"
value: 0
}
}
}Global Average Pooling层:
传统CNN利用低层的卷积来提取特征,最后一个卷积层输出的feature map被向量化然后送入到全连接层,其后面跟着一个softmax logistic regression层。利用卷积加池化层作为特征提取器,用全连接层连接分类函数做分类。
linear convolution + pooling + full-connection + softmax logistic regressionNIN 中提出了 global average pooling 来替代全连接层,其目的就是为最后一个mlpconv层的每个关联类别建立一个统一的feature map,也就是最后一层的整个feature map 上面做average pooling。可将最后一层输出的特征图的空间平均值解释为相应类别的置信度!因为在采用了微神经网络后,让局部模型有更强的抽象能力,从而让全局平均池化能具有特征图与类别之间的一致性。例如,最后一层conv feature map 是7×77×7,那么,pooling 的 kernel 大小就是 7×77×7。这样做的结果是完全不需要训练参数,而且还可以防止 overfitting。在实践中,需要注意的是把最后一层的conv kernel 个数设置为输出的类别数就可以了。例如在ImageNet中设置为1000。
与全连接相比,global average pooling具有如下几个优点:
一、通过加强特征图与类别的一致性,让卷积结构更简单(最后一层输出的特征图的空间平均值可以解释为相应类别的置信度);
二、不需要进行参数优化,也就避免了过拟合的发生;
三、对空间信息进行了求和,因而对输入的空间变换更具鲁棒性。
global average pooling层的网络结构定义如下:
layers {
bottom: "cccp7"
top: "cccp8"
name: "cccp8-1024"
type: CONVOLUTION
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
# 注意设置最后一个feature map 的输出个数等于类别数
num_output: 1000
kernel_size: 1
stride: 1
weight_filler {
type: "gaussian"
mean: 0
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layers {
bottom: "cccp8"
top: "cccp8"
name: "relu12"
type: RELU
}
# Global Average Pooling
layers {
bottom: "cccp8"
top: "pool4"
name: "pool4"
type: POOLING
pooling_param {
# 使用average pooling
pool: AVE
# kernel size 等于 feature map 的大小
kernel_size: 6
stride: 1
}
}Network In Network网络结构:
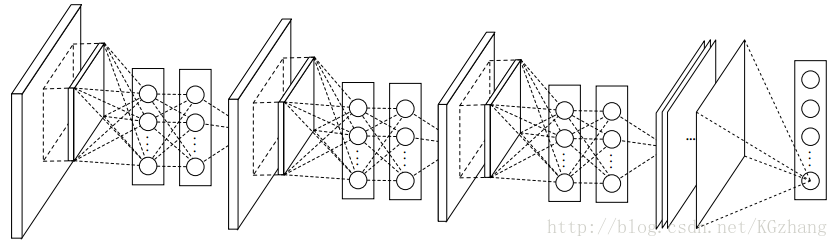
网络结构为:三层MLPconv+空间最大池化+下采样+全局平均池化,除最后一个MLPconv层外,其余层使用dropout进行正则化。
整个NIN网络架构由多个mlpconv层堆叠起来,后面接着全局平均池化和目标损失层。每个mlpconv层里面都包含一个3层的感知机模型,NIN网络结构的层数和微型网络个数都可以根据具体的任务进行调整。














 1085
1085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









