







借鉴了很多别的东西 找不到出处了
引用
Lin M, Chen Q, Yan S. Network In Network[J]. Computer Science, 2013.
目录
Network in Network 是2013提出的一种在网络结构上非常具有创造性的文章,文中作者做了大量的对比实验,说明各种结构对精度的影响。
前言
以前的深度学习结构,往往是CNN+POOLing+FC之类的组合,接一个分类器。这样在CNN与FC进行结合的过程中,则把两部分过程独立来开,POOLing负责将维度,CNN负责提取特征,FC负责特征分类。
那么,由于卷积网络参数较少,因此深度卷积网络的参数其实大部分集中在了全连接层,那么这个时候,到底是卷积层对结果贡献大还是全连接层贡献大?本文提出的模型尝试赋予卷积层更强大的表征能力,同时去掉了全连接层,使用了平均池化层来代替全连接层进行分类,这样做的好处就是一方面减少了参数,另一方面避免了由全连接层导致的过拟合的问题,因为池化层本身就充当了避免过拟合的功能,从而也就不需要采用dropout了。
卷积层是一个线性层(激活函数的目的就使数据非线性),如果遇到特征是高度非线性的,那么此线性卷积就不足以表达了,传统的做法是通过多个特征图来增强卷积层的表达能力,但是这样做又会对下一个卷积层造成较大的压力,因为下一层要考虑如何组合这些特征图得到更高级的特征抽象。
而NIN则利用mlpconv和global average pooling将CNN和FC两部分有机的结合在一起,使得其可解释性更强。从而文章的创新点:
- 提出了mlpconv代替普通的卷积操作,从而来提升抽象能力
- 提出了global average pooling,从而将CNN与FC有机的结合在一起,使得整个网络结构的可解释性更加强,效果也更佳
创新点一:mlpconv (multilayer perceptron conv)
首先,普通的卷积操作都是通过一个线性变换,然后后面跟着一个非线性激励函数

其中,w∗x+bw∗x+b为线性变换,函数ff为非线性激励函数,例如sigmoid,tanh,ReLUsigmoid,tanh,ReLU等,但是这种抽象能力比较弱,指出这种表达能力只能正线性行可分的情况比较适应,换句话说,该结构的非线性表达能力较弱。


作者比较了传统的conv和mlpconv之间的区别:
- mlpconv在普通的卷积后面接了一个多层感知机MLP
- 在conv与MLP之间的连接采用的是global average pooling的方法:使得conv后的每一层特征通过全局平均产生一个元素,形成一个向量,然后在进行MLP,从而这样形成的特征层可以表示为分类目标的置信层(confidence map)
多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构,如下图:

conventional 的卷积层 可以认为是linear model , 为什么呢,因为 局部接收域上的每每一个tile 与 卷积核进行加权求和,然后接一个激活函数;它的 abstraction 的能力不够, 对处理线性可分的的 concept 也许是可以的,但是更复杂的 concepts 它有能力有点不够了,所以呢,需要引入 more potent 的非线性函数;
基于此,提出了 mlpcon 结构,它用多层的感知器(其实就是多层的全连接层)来替代单纯的卷积神经网络中的 加 权求和; mlpcon 指的是: multilayer perceptron + convolution;
两者的结构如下所示:其中下图的 Mlpconv 的有两层的隐含层;
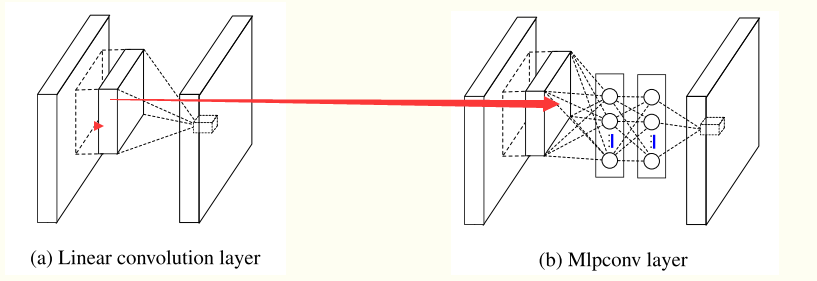
说明:在mlpconv中的每一层的后面都跟着一个 ReLU激活函数;用于加入更多的nonlinearity;
mlpconv 的细节:
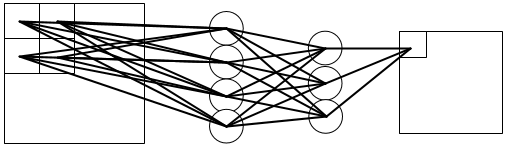
输入为一个feature map, 输出为一个feature map 时:
输入为多个feature map, 输出为一个feature map 时:
输入为多个feature map, 输出为多个feature map 时:
发现了什么 ?
在 卷积神经网络中,无论是输入还是输出,不同的 feature map 之间的卷积核是不相同的;
在mlpconv中,不同的 feature map 之间的开头与能结尾之间的权值不一样,而在 隐含层之间的权值是共享的;
另外:
全连接层之间可以看作一特殊的卷积层,其中卷积核的大小为 1*1, feature maps的 个数即为全连接层中的每一层的units的数目;
所以呢,假设上面的第三个图中的输入为2*(4 *4), 输出为2 * (3*3)时:
第一层的卷积核大小为2*2, 步长为1, 输入为2*(4 *4), 输出为 4*(3*3);
第二层的卷积核大小为1*1, 步长为1, 输入为4*(3 *3), 输出为 3*(3*3);
第三层的卷积核大小为1*1, 步长为1, 输入为3*(3 *3), 输出为 2*(3*3);
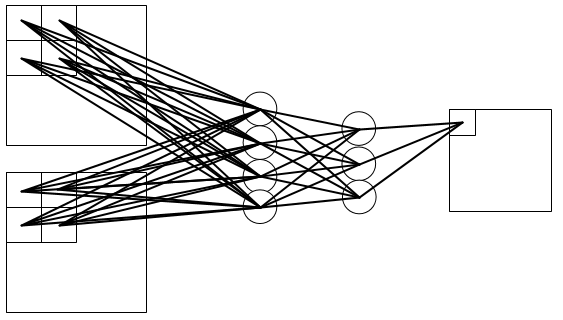
![image[49]](http://images2015.cnblogs.com/blog/961754/201706/961754-20170610113108825-1609536528.png)
创新点二:global average pooling
一般的卷积神经网络,又CNN+FC构成,FC负责分类,最终的分类目标有多少类,则最后的输出多少维的向量,对应类别信息。但是,在CNN最后的特征层到FC是一个全联接,导致这部分的参数占据了整个网络参数的大部分,而且全联接很容易导致过拟合(overfitting)。
作者提供了一种全新的从特征层到最终的分类目标–global average pooling。该方法使得最终的特征层的深度等于最终的分类目标的种类数,然后后面紧跟一个全局平均池化,从而可以将特征层转化为一个分类向量,和最终的分类结果产生了直接的联系。
- 该方法大大的减少了模型的参数,由于该连接方式没有参数,从而没有计算,大大减少了计算量,提高了计算速度
- 该方法有效避免过拟合
- 可解释性非常强,可以讲最终的feature map看作最终分类目标的confidence map

从上图中,可以看出最终的特征层与分类目标之间具有很强的相关性。
卷积神经网络最后的全连接层可以说作为了一个分类器,或者作为了一个 feature clustering. 它把卷积层学习到的特征进行最后的分类; intuitively, 根本不了解它是怎么工作的, 它就像一个黑盒子一样,并且它也引入了很多的参数,会出现 overfitting 现象; (我认为其实最后的 全接层就是一个分类器)
本文,remove掉了 全连接层, 使用 global average pooling 来代替; 举个例子更容易说明白: 假设分类的任务有100 classes, 所以设置网络的最后的 feature maps 的个数为 100, 把每一个feature map 看作成 对应每一类的 概率的相关值 ,然后对每一个 feature map 求平均值(即 global average pooling), 得到了 100维的向量, 把它直接给 softmax层,进行分类;(其实100个数中最大值对应的类别即为预测值, 之所以再送给 softmax层是为了求 loss,用于训练时求梯度)
网络的整体结构:
(原 paper 中的图)

(该图来自:http://blog.csdn.net/hjimce/article/details/50458190 ,加入了相关的参数。我怎么找到这个图呢???? 难道 楼主自己 根据 caffe 中的 .prototxt 文件的加上的??)
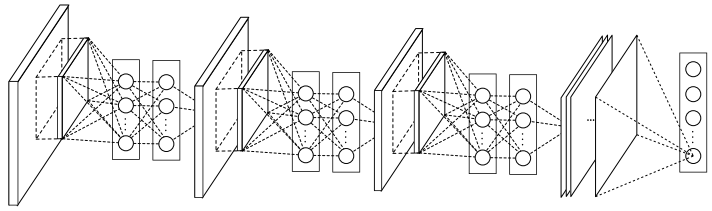
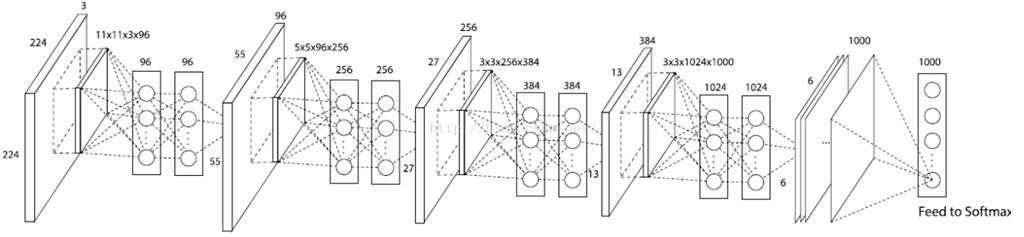

网络结构

论文中给出的结构如上图,作者将mlpconv作为一个最小单元,然后多个mlpconv叠加在一起,然后生成一个n(分类目标数量)层的特征层,最后通过global average pooling生成一个输出向量(n维,每一特征层生成一维)。
详细的结构可以参考下图:
【来源】

效果分析
首先作者在不同的数据集上进行了对比,发现该方法具有很好的效果:


在cifar10数据集上,可以达到state-of-the-art的效果,而在cifar100,SVHN, MINST上面也达到了很好的效果


作者最后也进一步试验,强调了global average pooling和fc相似,都具有扮演着线性变换的作用,将特征图转化为特征向量,但前者相比较fc的方法效果更好

结论
文中的观点:通过实验说明了 global average pooling 也可以起到很好的 regular的作用。
另外,一个比较有趣地地方就是:在 可视化最后一层 feature maps时,它的激活区域与原始图片中目标所在的区域竟然相似;amazing!
文中大量用到了文献:Maxout networks. (引用:Goodfellow I J, Warde-Farley D, Mirza M, et al. Maxout networks[J]. arXiv preprint arXiv:1302.4389, 2013.)
文中也说明了 NIN比 maxout networks 更 non-linearity;
后续很有必要看一下 文献 maxout networks 这个paper, 它具有很好的价值;
import tensorflow as tf
def cnn_plus_relu(conv1_filter_name,conv1_filter_shape):
assert type(conv1_filter_name) == 'str',"%s need the type of str,not %s"\
%(conv1_filter_name,type(conv1_filter_name))
assert len(conv1_filter_shape) == 4, "shape contrained w,h,channel,batch_size "
conv_filter = tf.get_variable(conv1_filter_name,shape=conv1_filter_shape) # [w,h,channel,batch_size]
def nin_cell(input):
conv1_filter = tf.get_variable('conv1_filter', shape=[5, 5, 3, 192])
conv1 = tf.nn.relu(tf.nn.conv2d(input, conv1_filter))
mlpconv1_filter = tf.get_variable('mlpconv1_filter', shape=[1, 1, 192, 160])
mlpconv1 = tf.nn.relu(tf.nn.conv2d(conv1, mlpconv1_filter))
mlpconv2_filter = tf.get_variable('mlpconv2_filter', shape=[1, 1, 160, 96])
mlpconv2 = tf.nn.relu(tf.nn.conv2d(mlpconv1, mlpconv2_filter))
max_pool1 = tf.nn.max_pool(mlpconv2, ksize = [1,3,3,1], strides=[1,2,2,1])
conv2_filter = tf.get_variable('conv2_filter', shape=[5, 5, 96, 192])
conv2 = tf.nn.relu(tf.nn.conv2d(max_pool1, conv2_filter))
mlpconv3_filter = tf.get_variable('mlpconv3_filter', shape=[1, 1, 192, 192])
mlpconv3 = tf.nn.relu(tf.nn.conv2d(conv2, mlpconv3_filter))
mlpconv4_filter = tf.get_variable('mlpconv4_filter', shape=[1, 1, 192, 192])
mlpconv4 = tf.nn.relu(tf.nn.conv2d(mlpconv3, mlpconv4_filter))
max_pool2 = tf.nn.max_pool(mlpconv4, ksize = [1,3,3,1], strides=[1,2,2,1])
conv3_filter = tf.get_variable('conv3_filter', shape=[3, 3, 192, 192])
conv3 = tf.nn.relu(tf.nn.conv2d(max_pool2, conv3_filter))
mlpconv4_filter = tf.get_variable('mlpconv4_filter', shape=[1, 1, 192, 192])
mlpconv4 = tf.nn.relu(tf.nn.conv2d(conv3, mlpconv4_filter))
mlpconv5_filter = tf.get_variable('mlpconv5_filter', shape=[1, 1, 192, 10])
mlpconv5 = tf.nn.relu(tf.nn.conv2d(mlpconv4, mlpconv5_filter))
global_avg_pool = tf.nn.avg_pool(mlpconv5, ksize=[1,8,8,1])
return global_avg_pool
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











