







 本文是吴恩达Coursera深度学习课程中关于深度卷积模型的笔记,涵盖LeNet、AlexNet、VGGNet、ResNet等经典网络结构,重点解析ResNet的残差块和性能优势,并提及1x1卷积、Inception Network、迁移学习和数据扩充在深度学习中的应用。
本文是吴恩达Coursera深度学习课程中关于深度卷积模型的笔记,涵盖LeNet、AlexNet、VGGNet、ResNet等经典网络结构,重点解析ResNet的残差块和性能优势,并提及1x1卷积、Inception Network、迁移学习和数据扩充在深度学习中的应用。
作者: 大树先生
博客: http://blog.csdn.net/koala_tree
知乎:https://www.zhihu.com/people/dashuxiansheng
GitHub:https://github.com/KoalaTree
2017 年 11 月 14 日
以下为在Coursera上吴恩达老师的 DeepLearning.ai 课程项目中,第四部分《卷积神经网络》第二周课程“深度卷积模型”关键点的笔记。本次笔记几乎涵盖了所有视频课程的内容。在阅读以下笔记的同时,强烈建议学习吴恩达老师的视频课程,视频请至 Coursera 或者 网易云课堂。
同时我在知乎上开设了关于机器学习深度学习的专栏收录下面的笔记,以方便大家在移动端的学习。欢迎关注我的知乎:大树先生。一起学习一起进步呀!_
卷积神经网络 — 深度卷积模型
1. 经典的卷积网络
介绍几种经典的卷积神经网络结构,分别是LeNet、AlexNet、VGGNet。
LeNet-5:
LeNet-5主要是针对灰度设计的,所以其输入较小,为 32 × 32 × 1 32\times32\times1 32×32×1,其结构如下:
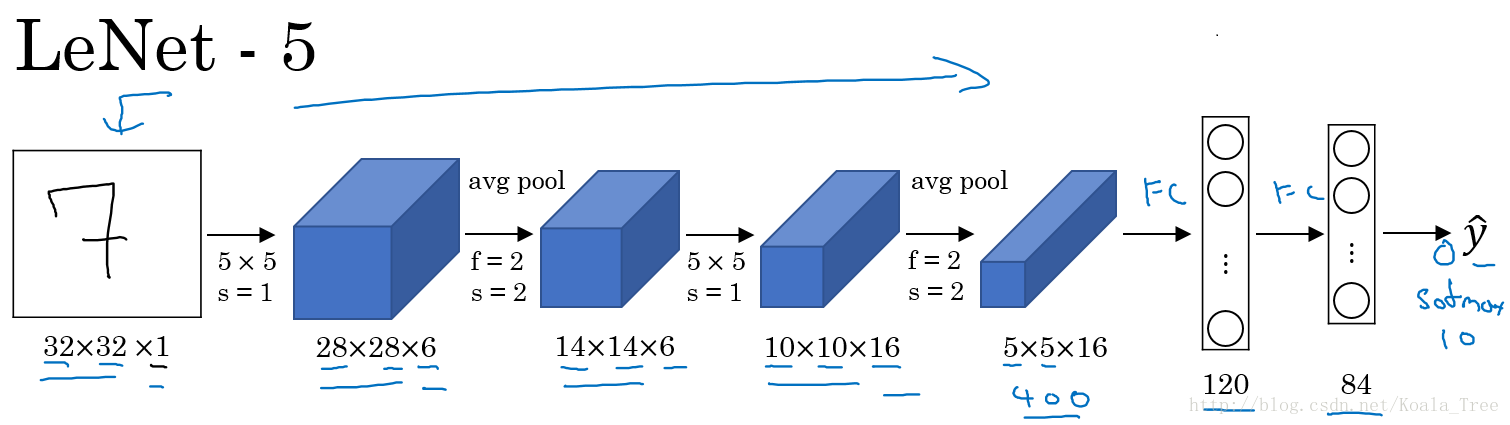
在LetNet中,存在的经典模式:
- 随着网络的深度增加,图像的大小在缩小,与此同时,通道的数量却在增加;
- 每个卷积层后面接一个池化层。
AlexNet:
AlexNet直接对彩色的大图片进行处理,其结构如下:
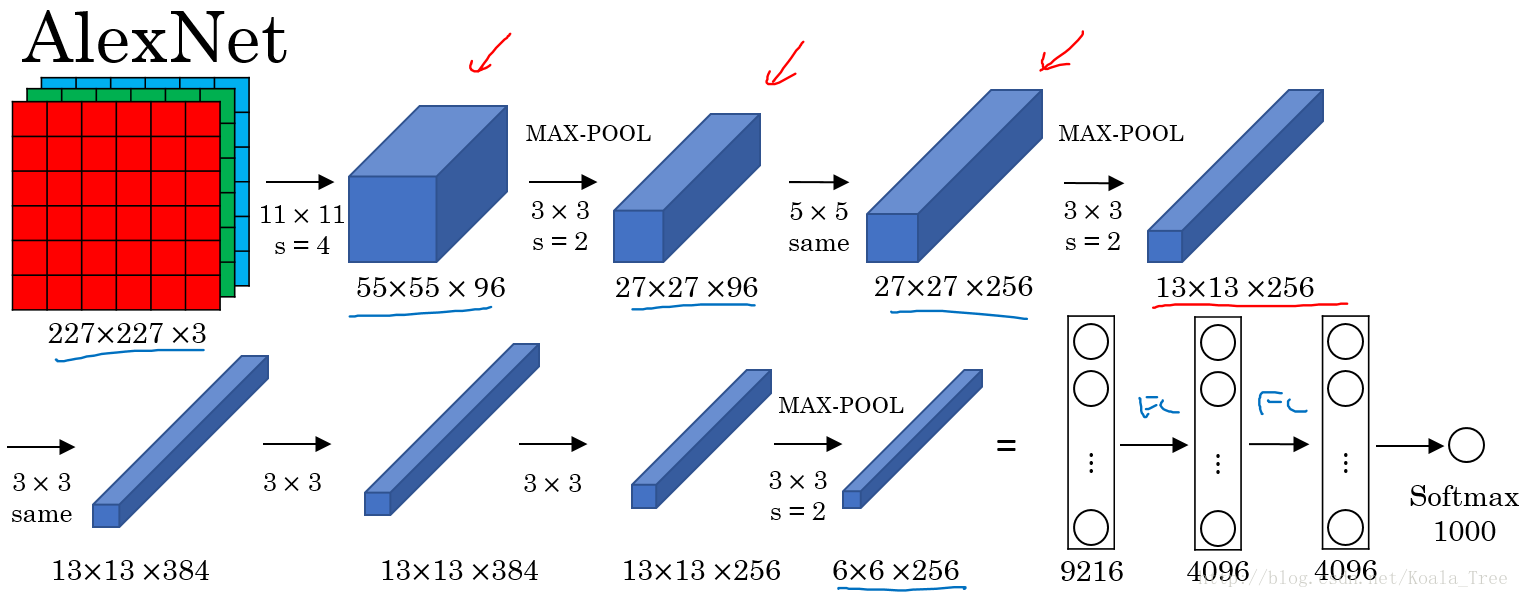
- 与LeNet相似,但网络结构更大,参数更多,表现更加出色;
- 使用了Relu;
- 使用了多个GPUs;
- LRN(后来发现用处不大,丢弃了)
AlexNet使得深度学习在计算机视觉方面受到极大的重视。
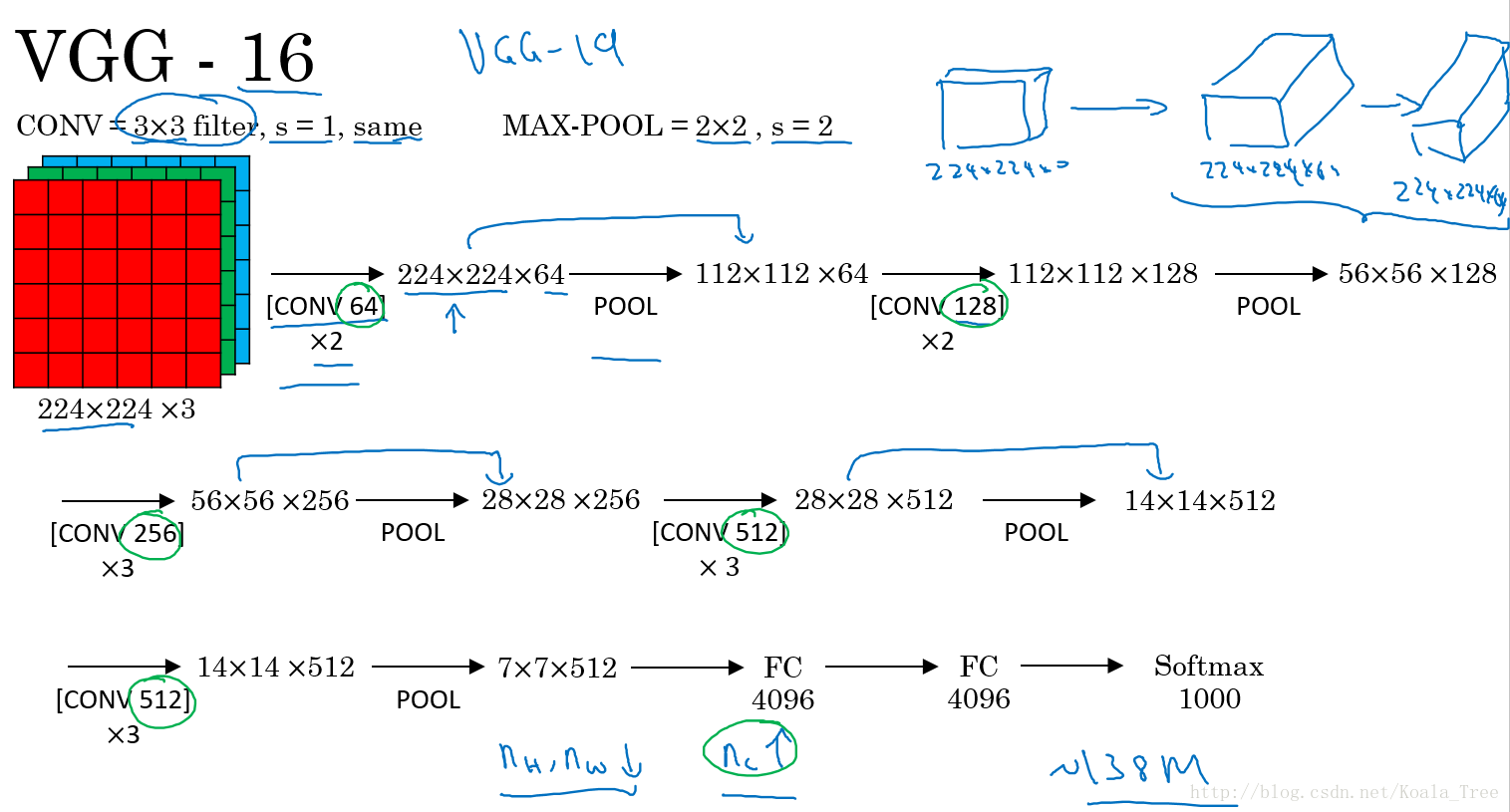
VGG-16:
VGG卷积层和池化层均具有相同的卷积核大小,都使用 3 × 3 , s t r i d e = 1 , S A M E 3\times3,stride=1, SAME 3×3,stride=1,SAME的卷积和 2 × 2 , s t r i d e = 2 2\times2, stride=2 2×2,stride=2 的池化。其结构如下:
2. ResNet
ResNet是由残差块所构建。
残差块:
下面是一个普通的神经网络块的传输:
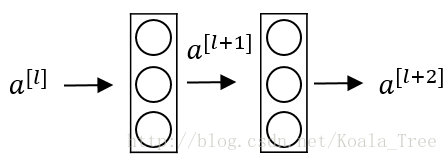
其前向传播的计算步骤为:
- Linear: z [ l + 1 ] = W [ l + 1 ] a [ l ] + b [ l + 1 ] z^{[l+1]} = W^{[l+1]}a^{[l]} + b^{[l+1]} z[l+1]=W[l+1]a[l]+b[l+1]
- Relu: a [ l + 1 ] = g ( z [ l + 1 ] ) a^{[l+1]} = g(z^{[l+1]}) a[l+1]=g(z[l+1])
- Linear: z [ l + 2 ] = W [ l + 2 ] a [ l + 1 ] + b [ l + 2 ] z^{[l+2]} = W^{[l+2]}a^{[l+1]} + b^{[l+2]} z[l+2]=W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









