







 本文探讨了logistic regression在处理概率输出时为何不适合使用MSE损失函数,并介绍了如何通过交叉熵损失函数解决这一问题。同时,文章还涉及softmax回归,说明在实际应用中通常将softmax层与回归层结合,并采用log-likelihood作为损失函数。
本文探讨了logistic regression在处理概率输出时为何不适合使用MSE损失函数,并介绍了如何通过交叉熵损失函数解决这一问题。同时,文章还涉及softmax回归,说明在实际应用中通常将softmax层与回归层结合,并采用log-likelihood作为损失函数。
我们有logistic regression可以将实数域的输入映射为0到1的概率输出,能够有很好的意义。但是如果用平常的MSE(最小均方误差)就会有问题。我们来剖析这个问题:
logistic与MSE
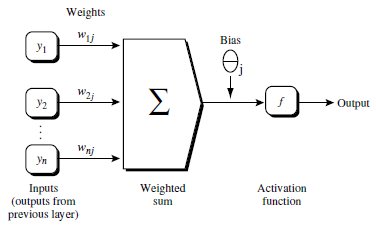
现在有一个目标:输入0,输出1。
为了方便起见,我们现在只考虑有一个神经元
我们给定初始的权重w=0.6,b=0.9来看学习趋势,这里学习率 η=0.15,初始预测值为0.82
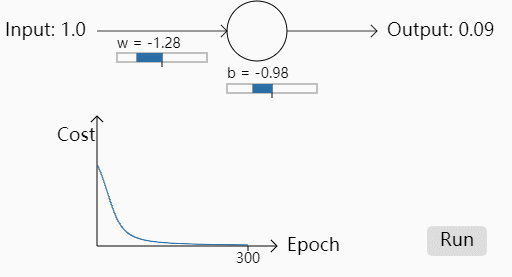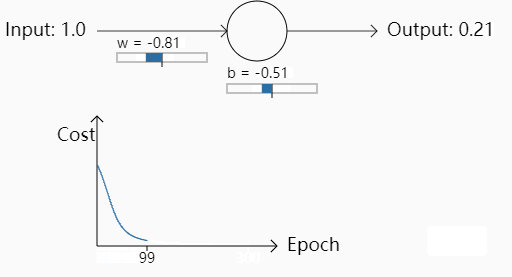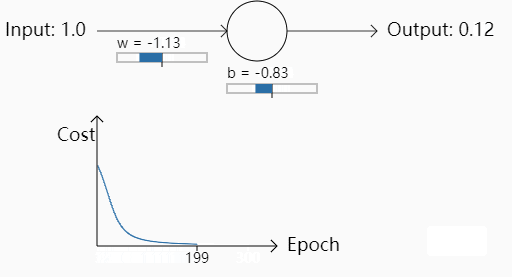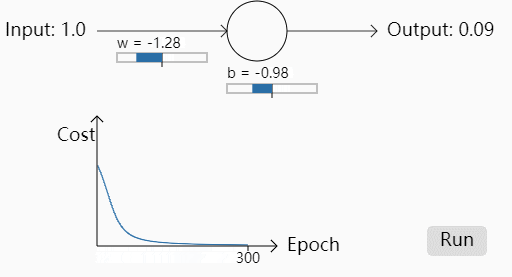
可以看到Cost一开始随着训练轮数的增加下降的还是蛮快的,之后平缓,符合人们的直觉。
我们再次改变权重令,w=2.0,b=2.0,初始预测值为0.98
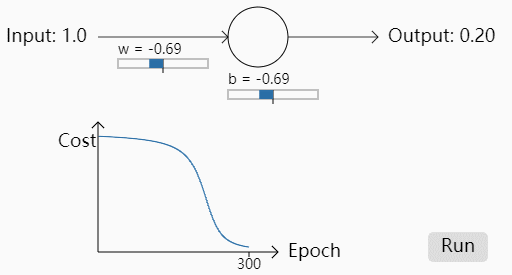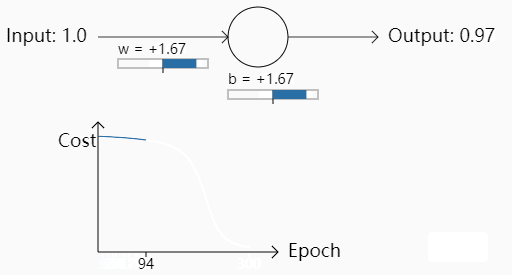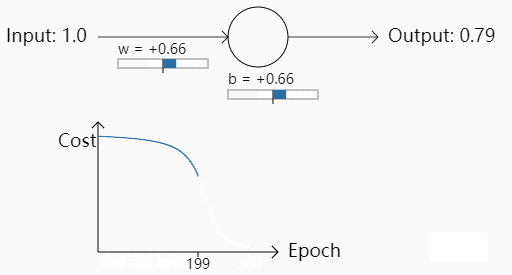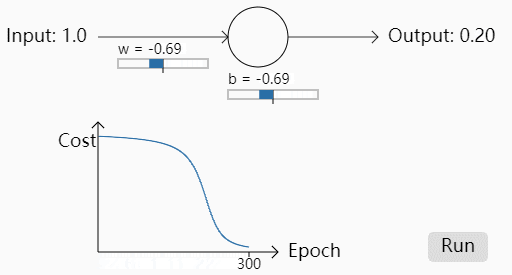
可以看出一开始的Cost几乎是不下降的,也就是说学习得特别缓慢。为什么会出现这种情况呢,初始的权重不同为什么会导致学习速率的不同呢?我们来看logistic regression+MSE到底哪里有欠缺。
首先来看MSE的形式:
C(ω,b)=12n∑x||y(x)−a||2
由于我们的简化,现在只有一个神经元则,变成:
C(ω,b)=12||y−a||2
其中 a=σ(z),z=ωx+b
分别对 ω , b 求偏导:
∂C∂b
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









