







知识点
压缩感知
如果信号在某一个正交空间具有稀疏性(即可压缩性),就能以较低的频率(远低于奈奎斯特采样频率)采样该信号,并可能以高概率精确的重建该信号。
简单来说:可以用一个随机感知矩阵去降维一个高维信号,得到的低维信号可以完全保持高维信号的特性。
随机投影
目的:降维
通过矩阵R(n*m维)将高维图像空间的x(m维)投影到低维空间v(n维)表示为:
v=Rx (n<<m)
但是降维不能只是降低维度,还要最大可能的保留高维度的信息。最理想的情况,我们当然希望低维的v可以完全的保留高维的x的信息,或者说保持原始空间中各样本x的距离关系,这样在低维空间进行分类才有意义。Johnso-Lindenstrauss指出如果将向量空间中两个点能够投影到一个随机选取的合适的高维度的子空间中,则能够以高概率保留两点之间的距离关系,这里的合适的高纬度要比原先的维度要低,而且Baraniuk在论文中证明了满足Johnso-Lindenstrauss推论的随机矩阵同时满足压缩感知的restricted isometry property(RIP)条件,所以如果随机矩阵R满足Johnso-Lindenstrauss推论,并且x是诸如语音或者图像这种可压缩的信号的话,就能以最小误差从低维的v中高概率的重构出高维的x。
论文分析
在线跟踪算法存在的问题
- 这些自适应的外观模型是数据相关的,但在刚开始时,没有足够的数据供在线学习算法学习。
- 在线跟踪算法经常遇到的漂移问题。由于是机器学习,所以有些样本会被分类错误,这些错误累积,会导致跟踪算法准确度降低。
解决方案
提出了一种简单高效地基于压缩感知的跟踪算法。首先提取前景目标和背景图像,利用符合压缩感知RIP条件的随机感知矩对多尺度图像特征进行降维,作为在线学习更新分类器的正样本和负样本,然后在降维后的特征上采用简单的朴素贝叶斯分类器去分类下一帧图像的目标待测图像片。
下面将进行具体分析。
流程
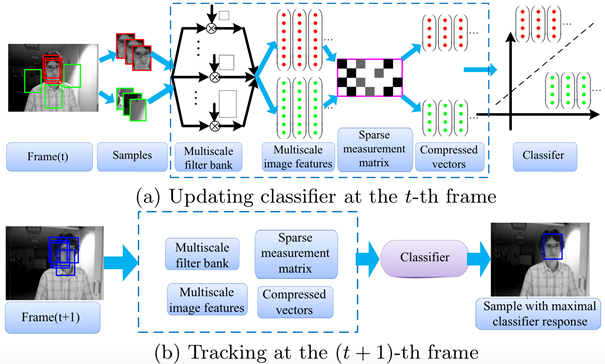
在第t帧更新分类器
在t帧的时候,以t-1帧的目标的位置为中心,r为半径,采样得到若干张目标(正样本)和背景(负样本)的图像片,然后对他们进行多尺度变换,再通过一个稀疏测量矩阵对多尺度图像特征进行降维,得到低纬度特征。然后通过降维后的特征(包括目标和背景,属二分类问题)去训练朴素贝叶斯分类器。
在第t+1帧跟踪目标
在t+1帧的时候,在上一帧跟踪到的目标位置的周围(满足Dγ={z|||l(z)−lt−1||<γ)采样n个扫描窗口(避免去扫描整幅图像),得到每个图像片的特征向量v。通过同样的稀疏测量矩阵对其降维,提取特征,然后用第t帧训练好的朴素贝叶斯分类器进行分类,分类分数最大的窗口就认为是目标窗口。
算法详解
随机稀疏观测矩阵的选择
问题:一个典型的满足RIP条件的随机测量矩阵是随机高斯矩阵(random Gaussian matrix)R,(R中的每个值rij服从N(0,1)),但是该矩阵有个缺点即一般是稠密的(dense),这样会导致在存取和计算时开销太大而难以接受。
解决思路:
找到一个非常稀疏的随机测量矩阵,如下所示:

当s=2 或3时该矩阵满足Johnso-Lindenstrauss推论,而s=3时矩阵是非常稀疏的,因为矩阵中1-1/3=2/3的概率都是0,故减少了2/3的计算开销,设定s=O(m)(m为压缩信号x的维度),这样对于R中的每一行只需要计算c=s(c<=4)个元素,所以矩阵的计算复杂度变为O(cn)。同时保存矩阵时只需要考虑非零元素,故空间复杂度也减少很多。
图中显示了从某帧中的正样本和负样本提取出的三个不同特征(低维空间下)的概率分布。红色和蓝色阶梯线分别代表正样本和负样本的直方图。而红色和蓝色的曲线表示通过我们的增量更新模型得到的相应的分布估计。图说明了在投影空间,通过上式描述的在线更新的高斯分布模型是特征的一个良好估计。
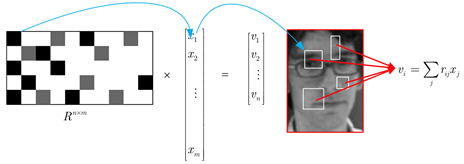
图中,矩阵R中,黑色、灰色和白色分别代表矩阵元素为负数、正数和零。蓝色箭头表示测量矩阵R的一行的一个非零元素感知x中的一个元素,等价于一个方形窗口滤波器和输入图像某一固定位置的灰度卷积。
为了实现尺度不变性,对每一个样本z∊Rw*h,通过将其与一系列多尺度的矩形滤波器{h1,1,…,hw,h}进行卷积,每一种尺度的矩形滤波器定义如下:
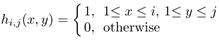
式中,i和j分别是矩形滤波器的宽和高。然后将滤波后的的图像矩阵展成一个w*h维的列向量。再将这些列向量连接成一个非常高维((w*h)2维)的多尺度图像特征向量x=(x1,…,xm)T。维数一般在10的6次方到10次方之间。
通过采用上面的稀疏随机矩阵R将x投影到低维空间的v。这个随机矩阵R只需要在程序启动时计算一次,然后在跟踪过程中保持不变。通过积分图可以高效的计算v。
分类器构建和更新:
对每个样本z(m维向量),它的低维表示是v(n维向量,n远小于m)。假定v中的各元素是独立分布的。可以通过朴素贝叶斯分类器建模。

其中,y∊{0,1}代表样本标签,y=0表示负样本,y=1表示正样本,假设两个类的先验概率相等。p(y=1)=p(y=0)=0.5。Diaconisand Freedman证明了高维随机向量的随机投影几乎都是高斯分布的。因此,假定在分类器H(v)中的条件概率满足

并且可以用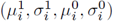
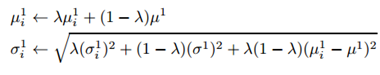
式中,学习速率λ>0,均值和方差初始化如下:
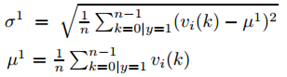
上式可以由最大化似然估计得到。















 5522
5522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









