







1. 采用索引的动机
Heap file支持大规模顺序扫描数据.理论上来说,heap file的这个特性足以实现所有SQL中的查询操作。但是,实际上它的效率将会非常差。
在本篇文章中,我们讨论了一些简单的技巧,去提升数据扫描(record scan)以及数据查找(record search)的效率。共同的主题将是:
Create secondary data storage to minimize disk I/O for record scan and search.
创建二级数据存储(磁盘),尽量减少数据扫描以及数据查找的磁盘I/O。
2. Sequential file
Sequential file是heap file的一种,具有这些特性:
a) page中的所有record都是按照某一个key进行排序的,具有如下的性质:
∀P, ∀ri∈P, ri[K]≤ri+1[K]
其中:K是一个key,P表示heap file中的任意page,ri表示P中的任意一条记录
b) 对heap file中的任意page Pi 和Pi+1来说, Pi+1中的record关于K的value都比Pi 大:
∀Pi, ∀r∈Pi, ∀r′∈Pi+1, r≤r′
因此可以说, Sequential file是record按某个key K进行全排序的heap file.这样一来当我们查找某个record的时候,就可以根据key K进行二分查找.
回顾heap file的设计:
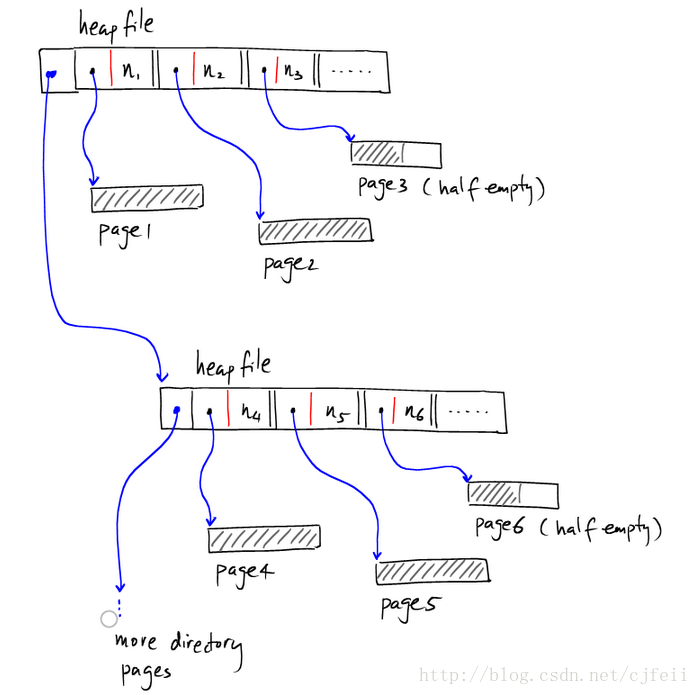
假如我们去寻找一条数据record r ,r[K]=v,我们可以将directory page加载到内存,对其中page pointer指向的pages进行二分查找。总共需要的磁盘I/O的数目在最坏的情况下是:
log2(Ndata pages)+(Ndirectory pages)
sequential file并没有解决在顺序扫描时效率低下的问题。
3. dense indexes(稠密索引或是全索引)
dense indexes是通过对每一个record在磁盘上持久保存一些额外的数据,用于提高查询的效率。
假设数据文件data file已经存在。
让K=(k1,k2,…,kn) 作为一个key。dense index file是一个sequential file,它里面的记录是用K和指向data file中对应record的指针组成:
rindex=(r[k1],r[k2],…,r[kn],address(r in Data File))
在dense index file中:
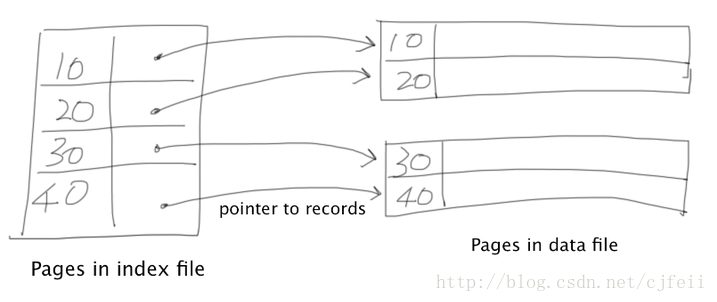
dense index file的主要动机是:和data file中的record相比,dense index file能显著减少record的大小。因此,每一个index page能包含更多的record。对index file进行顺序扫描能显著的减少磁盘I/O,因为和data file相比我们从磁盘获取的page数目减少了。
4. sparse index(稀疏索引)
Sparse index结合sequential file和dense index file的优点,通过保存部分key K作为它的record,能很好的支持二分查找快速查找record,并且能进一步减少所需的磁盘I/O。
想要利用sparse index file,data file必须是一个sequential file,也就是说data file中的record必须按K进行排序。
Sparse index只保存key值和data file中每个page的第一条record的地址:
(r[k1],r[k2],…,r[kn],address(P))
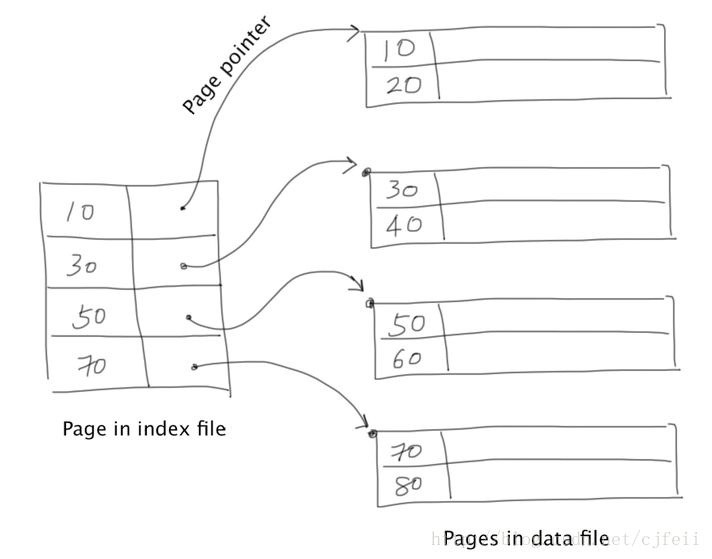
这样就减少了sparse index中的index page的数目。在sparse index中查找record r[K]=v,我们需要这样:
a)首先在sparse index中找到这样的一个record r:
r∗=argmaxrr[K]≤v
可以利用二分查找(上面的公式表示要在sparse index找最接近v并且不大于v的那条记录)。
b)在r∗所在的page中查找{r:r[K]=v}。
假设:为简单起见,我们只查找第一个满足条件的record
5. multilevel sparse index: tree index(多极稀疏索引)
Sparse index要求data file中的record必须是排好序的(比如sequential file),查询一条record需要:
log2(Nindex pages)+1
次磁盘I/O。
其中:log2(Nindex pages)是查询定位index page需要加载的page数目,1是表示需要加载1个data page。
通过观察可以发现,其实sparse index也是一个sequential file,那么就使得更进一步提高性能成为可能。所以,我们可以给sparse index再加一个sparse index(这就是多级稀疏索引)。
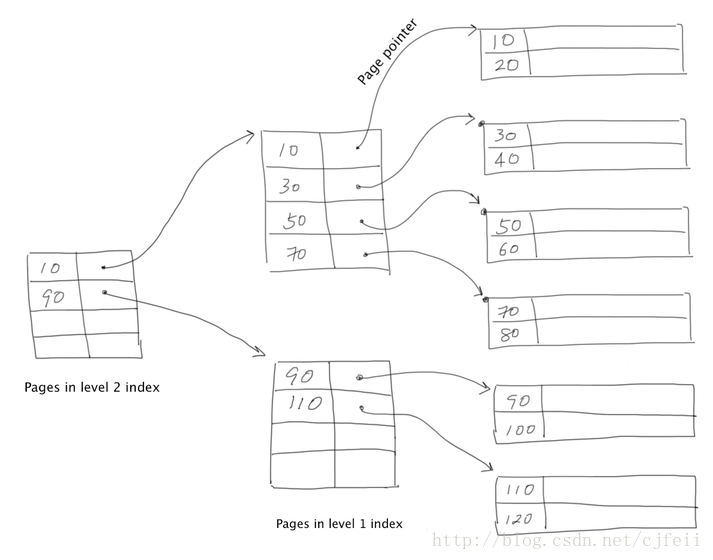
假设:D是data file,I1是一级sparse index,I2是二级sparse index。ND, NI1, NI2是对文件中的page数目。
它们应该是这种关系:
ND>NI1>NI2
查找record需要的磁盘I/O开销是:
log2(NI2)+2
其中,log2(NI2)是在I2中定位需要加载的page数目,在I1中只需要加载一个page,在D中也是只需加载一个page。
6. indexed sequential access method(ISAM) 索引顺序访问方法
6.1 Multilevel sparse index的局限性
Multilevel sparse index能连续的应用。随着index level的增加,每层index page的数目会递减,直到最高层会只有一个index page。
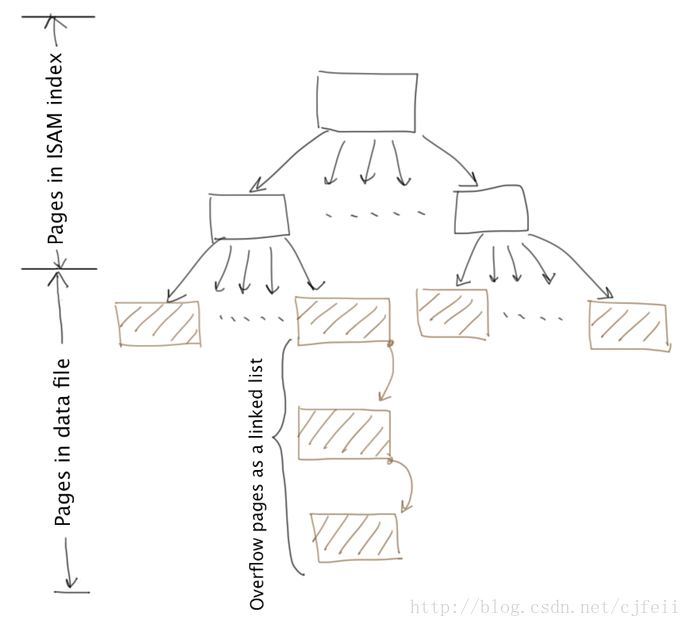
伴随着Multilevel sparse index有很高的查询效率这个优点的同时,不幸的是它不能很好的支持record的insert(插入)和update(修改)。回想一下,我们清楚的知道sparse index只能在有序的sequential file上加索引。因此,任何insert和update操作必须维护record的有序性。Heap file也是仅支持有效率的append(追加)record,但是不支持record的有序性。
6.2 ISAM
ISAM虽然是一种基于Multilevel sparse index的索引技术,但是它克服了Multilevel sparse index存在的一些局限性。它支持快速的insert和update。
ISAM的不同之处是,data file中的每一个data page都可以有任意数目的overflow page(溢出页)。当我们insert一个record r:
a)首先定位这样一个data page Pi:Pi[0][K]≤r[K]<Pi+1[0][K]。
b)如果Pi中有空余空间,那么就将r insert到Pi。
c)如果Pi有overflow page Q,并且Q有空余空间,那么就将r insert到Q。
d)如果Pi的overflow page全部都满了,那么就创建一个新的overflow page,将r insert进去。
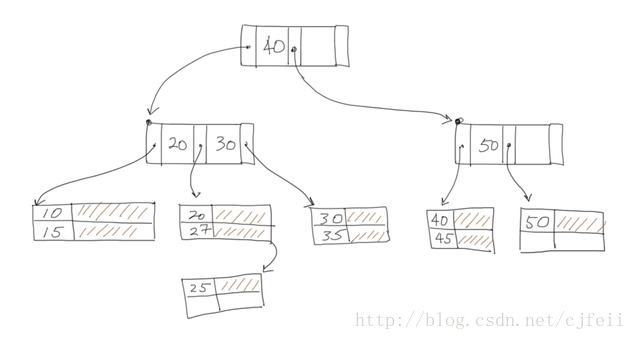
注:图中record(25, ...)就是我们刚insert进去的。当时在20和30之间的那个page没有空余空间保存数据。因此,ISAM必须在那个page之后追加创建一个新的overflow page并链接之。可以这样说,record(25, ...)导致了新的overflow page的生成。
6.3 ISAM的局限性
ISAM放宽了record的有序性。于是就导致,获取record的最坏的性能是:
log2(Nindex page)+max(Noverflow page)
ISAM有着这种局限性的原因是:在record修改(包括update,insert)的时候multilevel sparse index 一直是静态的。
我们将讨论另外一种索引结构——B+tree,通过动态的调整树的平衡的方法来处理ISAM的性能退化。














 6650
6650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









