 Redis跳跃表详解:数据结构与API解析
Redis跳跃表详解:数据结构与API解析








 本文详细介绍了Redis中的跳跃表(skiplist)数据结构,包括其组成部分、Redis的修改和优化,如允许重复score值、添加tail指针等。同时,列举并解析了跳跃表的相关API,如zslCreate、zslInsert、zslDelete等,这些操作在对数期望时间复杂度内完成。
本文详细介绍了Redis中的跳跃表(skiplist)数据结构,包括其组成部分、Redis的修改和优化,如允许重复score值、添加tail指针等。同时,列举并解析了跳跃表的相关API,如zslCreate、zslInsert、zslDelete等,这些操作在对数期望时间复杂度内完成。
本文所引用的源码全部来自Redis2.8.2版本。
Redis中skiplist数据结构与API相关文件是:redis.h与t_zset.c。
http://blog.csdn.net/acceptedxukai/article/details/8923174 这是我之前写的关于skiplist最传统的实现,功能远不如Redis中跳表的强大,但是代码简短,比较容易理解。
转载请注明,文章来自:http://blog.csdn.net/acceptedxukai/article/details/17333673
一、跳跃表简介
跳跃表是一种随机化数据结构,基于并联的链表,其效率可以比拟平衡二叉树,查找、删除、插入等操作都可以在对数期望时间内完成,对比平衡树,跳跃表的实现要简单直观很多。
以下是一个跳跃表的例图(来自维基百科):
从图中可以看出跳跃表主要有以下几个部分构成:
1、 表头head:负责维护跳跃表的节点指针
2、 节点node:实际保存元素值,每个节点有一层或多层
3、 层level:保存着指向该层下一个节点的指针
4、 表尾tail:全部由null组成
跳跃表的遍历总是从高层开始,然后随着元素值范围的缩小,慢慢降低到低层。
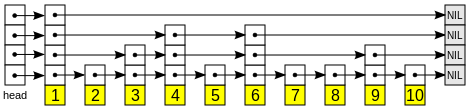
二、Redis中跳跃表的数据结构
Redis作者为了适合自己功能的需要,对原来的跳跃表进行了一下修改:
1、 允许重复的score值:多个不同的元素(member)的score值可以相同
2、 进行元素对比的时候,不仅要检查score值,还需要检查member:当score值相等时,需要比较member域进行比较。
3、 结构保存一个tail指针:跳跃表的表尾指针
4、 每个节点都有一个高度为1层的前驱指针,用于从底层表尾向表头方向遍历
跳跃表数据结构如下(redis.h):
typedef struct zskiplistNode {
robj *obj; //节点数据
double score;
struct zskiplistNode*backward; //前驱
struct zskiplistLevel {
struct zskiplistNode*forward;//后继
unsigned int span;//该层跨越的节点数量
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode*header, *tail;
unsigned long length;//节点的数目
int level;//目前表的最大层数
} zskiplist;数据结构中可能span这个参数最不好理解了,下面简单解释一下:
参照上面跳跃表的例图,head节点的span所有level的值都将是1;node 1在level 0 span值为1,因为跨越1个元素都将走到下一个节点2,在level 1 span值为2,因为需要跨越2个元素(node 2,node 3)才能到达下一个节点3。
关于span的解释可以详看: http://stackoverflow.com/questions/10458572/what-does-the-skiplistnode-variable-span-mean-in-redis-h
三、简单列出跳跃表的API,他们的作用以及算法复杂度
约定O(N)表示对于元素个数的表达,O(L)表示对于跳表层数的表达
| 函数名 |
作用 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2806
2806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









