







一、n-gram是什么
wikipedia上有关n-gram的定义:
n-gram是一种统计语言模型,用来根据前(n-1)个item来预测第n个item。在应用层面,这些item可以是音素(语音识别应用)、字符(输入法应用)、词(分词应用)或碱基对(基因信息)。一般来讲,可以从大规模文本或音频语料库生成n-gram模型。
习惯上,1-gram叫unigram,2-gram称为bigram,3-gram是trigram。还有four-gram、five-gram等,不过大于n>5的应用很少见。
二、n-gram的理论依据
n-gram语言模型的思想,可以追溯到信息论大师香农的研究工作,他提出一个问题:给定一串字母,如”for ex”,下一个最大可能性出现的字母是什么。从训练语料数据中,我们可以通过极大似然估计的方法,得到N个概率分布:是a的概率是0.4,是b的概率是0.0001,是c的概率是…,当然,别忘记约束条件:所有的N个概率分布的总和为1.
n-gram模型概率公式推导。根据条件概率和乘法公式:
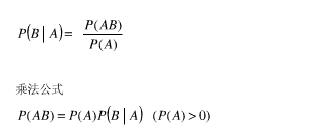
得到
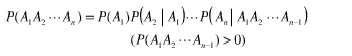
拿一个应用来讲,假设T是由词序列A1,A2,A3,…An组成的,那么P(T)=P(A1A2A3…An)=P(A1)P(A2|A1)P(A3|A1A2)…P(An|A1A2…An-1)
如果直接这么计算,是有很大困难的,需要引入马尔科夫假设,即:一个item的出现概率,只与其前m个items有关,当m=0时,就是unigram,m=1时,是bigram模型。
因此,P(T)可以求得,例如,当利用bigram模型时,P(T)=P(A1)P(A2|A1)P(A3|A2)…P(An|An-1)
而P(An|An-1)条件概率可以通过极大似然估计求得,等于Count(An-1,An)/Count(An-1)。
三、n-gram的数据长什么样
其实,说n-gram长什么样,是不严谨的。它只是一个语言模型,只要把需要的信息存储下来,至于什么格式都是依据应用来定。如,著名的google books Ngram Viewer,它的n-gram数据格式是这样的:
circumvallate 1978 335 91
circumvallate 1979 261 91代表了一个1-gram的数据片段,第一行的意思是,“circumvallate”这个单词在1978年出现335次,存在91本书中。这些元数据,除了频率335次是必须的,其他的元数据(例如,还有词性等)可以根据应用需求来定。下面是一个5-gram数据片段:
analysis is often described as 1991 1 1 1当然,也可以是其他形式,例如,HanLP的n-gram模型是bigram:
—@北冰洋 2
—@卢森堡 1
—@周日 1
—@因特网 1
—@地 1
—@地域 1
—@塔斯社 9
—@尚义 12
—@巴 1
—@巴勒斯坦 1
—@拉法耶特 3
—@拍卖 1
—@昆明 1每一行代表,两个相邻单词共同出现时的频率(相对于背后的语料库)。
四、n-gram有什么用
4.1 文化研究
n-gram模型看起来比较枯燥和冰冷,但实际上,google books ngram项目,催生了一门新学科(Culturomics)的成立,通过数字化的文本,来研究人类行为和文化趋势。可查看知乎上的详细介绍,。《可视化未来》这本书也有详细介绍。

还有TED上的视频《what_we_learned_from_5_million_books》,十分精彩。
4.2 分词算法
4.3 语音识别
4.4 输入法
大家每天都在使用的东西,请看:输入“tashiyanjiushengwude”,可能的输出有:
它实验救生无得
他实验就生物的
他是研究圣物的
他是研究生物的究竟哪个是输入者最想表达的意思,这背后的技术就要用到n-gram语言模型了。item就是每一个拼音对应的可能的字。还记得智能ABC吗?据说是运用n-gram的鼻祖了。
不过搜狗输入法后来居上,它采用更先进的云计算技术(n-gram模型的数据量可是相当之大,后面会说到)

4.5 机器翻译
五、n-gram的更多认识
做概率统计的都知道,语料库的规模越大,做出的n-gram对统计语言模型才更有用,例如,google books ngram项目,单独对中文的n-gram,从1551年到2009年,总体规模如下:
....
1999 1046431040 8988394 9256
2000 1105382616 10068214 10504
2001 1017707579 8508116 9426
2002 1053775627 9676792 11116
2003 1003400478 9095202 10624
2004 1082612881 9079834 11200
2005 1326794771 10754207 13749
2006 1175160606 9381530 12030
2007 826433846 6121305 7291
2008 752279725 5463702 6436
2009 442976761 2460245 2557
year n-gram count book page count book volumecount
26859461025 252919372 302652
总共才扫描了30万卷书,生成的n-gram(从unigram到5-gram)的个数就达到了268亿多个。英文的n-gram在4684多亿多:
....
1999 9997156197 48914071 91983
2000 11190986329 54799233 103405
2001 11349375656 55886251 104147
2002 12519922882 62335467 117207
2003 13632028136 68561620 127066
2004 14705541576 73346714 139616
2005 14425183957 72756812 138132
2006 15310495914 77883896 148342
2007 16206118071 82969746 155472
2008 19482936409 108811006 206272
year n-gram count book page count book volumecount
468491999592 2441898561 4541627
这个数量级的n-gram,无论是存储还是检索,对技术都是极大的挑战。
以上是google books n-gram的相关数据,在前些年,google还提供了基于web的1个T的n-gram,规模如下:
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663共950亿个句子,10000亿个token,还只是2006年一年的数据。
除了google,微软通过它的BING搜索,也开放了PB级别(1PB = 1PeraByte = 1024 TB = 1024 * 1024 * 1024 MB)的n-gram,这种数量级别的,只能放云存储上了。
参考资料:
斯坦福大学自然语言处理公开课














 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









