







目录
一、语言模型
二、数学基础
三、N-Gram
# 1、原理
# 2、数据平滑
# 3、应用
# 4、缺点
四、神经语言模型
五、工具
# 语言模型
语言模型(Language Model,LM),语言模型是一个基于概率的判别模型,它的输入是一句话(单词的顺序序列),输出是这句话出现的概率,即这些单词的联合概率。主要的应用场景:
1️⃣ 人们基于一定的语料库,可以利用N-Gram来预计或者评估一个句子是否合理;
![]()
2️⃣ 通过输入的前N个词预言下一个词(常见于输入法,这种类型的LM被称为自回归语言模型(Autoregression, AT);
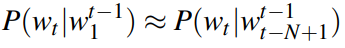

3️⃣ 用来评估两个字符串之间的差异程度。这是模糊匹配中常用的一种手段(此应用比较少见
📍 统计语言模型产生的初衷是为了解决语音识别问题。在语音识别中,计算机需要知道一个文字序列是否能构成一个大家理解而且有意义的句子,然后显示或者打印给使用者——《数学之美》
# 数学基础
1️⃣ 联合概率
P(A,B) :表示的是A,B同时发生的概率.
1.1 当A,B相互独立时,也就是交集为空的时候,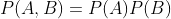
1.2 当A,B相关联的时候,或者说存在交集的时候,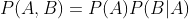
即 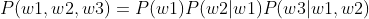 (链式法则
(链式法则
一般形式为: 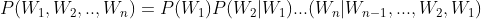
抽象为: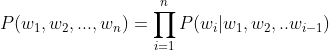
2️⃣ 条件概率
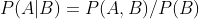
我们将其扩展到一般形式:
# N-Gram
N-Gram(N元模型)是自然语言处理中一个非常重要的概念。N-gram模型也是一种语言模型,是一种生成式模型。
假定文本中的每个词  和前面 N-1 个词有关,而与更前面的词无关。这种假设被称为N-1阶马尔可夫假设,对应的语言模型称为N元模型。习惯上,1-gram叫unigram,2-gram称为bigram(也被称为一阶马尔可夫链),3-gram是trigram(也被称为二阶马尔可夫链)。还有four-gram、five-gram等,不过大于n>5的应用很少见。常用的是 Bi-gram (N = 2) 和 Tri-gram (N = 3),一般已经够用了。
和前面 N-1 个词有关,而与更前面的词无关。这种假设被称为N-1阶马尔可夫假设,对应的语言模型称为N元模型。习惯上,1-gram叫unigram,2-gram称为bigram(也被称为一阶马尔可夫链),3-gram是trigram(也被称为二阶马尔可夫链)。还有four-gram、five-gram等,不过大于n>5的应用很少见。常用的是 Bi-gram (N = 2) 和 Tri-gram (N = 3),一般已经够用了。
用于构建语言模型的文本称为训练语料(training corpus)。语言模型的语料的标签就是它的上下文,这就决定了人们几乎可以无限制地利用大规模的语料来训练语言模型,使其学习到丰富的语义知识,而不需要耗费大量资源进行标注(属于self-supervised)。在相关论文中也通常会提及所使用的语料,比如BERT使用了BooksCorpus (800M words) (Zhu et al., 2015) 和English Wikipedia (2,500M words) 来训练语言模型 [来源]
📌 对于n元语法模型,使用的训练语料的规模一般要有几百万个词。语料库的选取也十分重要,如果训练语料和模型应用的领域相脱节,那么模型的效果通常要大打折扣。
📍 为什么N一般取值都很小呢?
1️⃣ N元模型的空间复杂度几乎是N的指数函数,即
,V是语言词典的词汇量;
2️⃣ 使用N元模型的时间复杂度也几乎是一个指数函数,即
。当N从1到2,再从2到3时,模型的效果上升显著;而当模型从3到4时,效果的提升就不是很显著了,而资源的耗费却增加的非常快。[更多详情请参阅吴军《数学之美》相关章节]
题外话:基于计数的LM的缺点,主要就是由它的N-gram的N不能太大又不能太小的限制造成的。如果能有一个结构,可以处理任意长度的输入,而不是要固定一长度的话,那就可以解决这个问题了。在这样的启发下,RNN被提出了。

# 1、原理
N-Gram基于一个假设:第n个词出现与前n-1个词相关,而与其他任何词不相关。整个句子出现的概率就等于各个词出现的概率乘积。各个词的概率可以通过语料中统计计算得到。
N-gram的第一个特点是某个词的出现依赖于其他若干个词,第二个特点是我们获得的信息越多,预测越准确。
假设句子S是有词序列w1,w2,w3...wn组成,用公式表示N-Gram语言模型如下(每一个单词wi都要依赖于从第一个单词w1到它之前一个单词wi−1的影响):
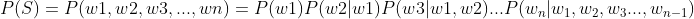
不过这个衡量方法有两个缺陷:
- 1️⃣参数空间过大:概率
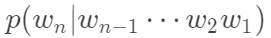 涉及到n个变量,每个变量的可能性都是字典大小。
涉及到n个变量,每个变量的可能性都是字典大小。
- 2️⃣ 数据稀疏严重:词同时出现的情况可能没有,组合阶数高时尤其明显。
⭐ 为了解决第一个问题,我们引入马尔科夫假设(Markov Assumption):一个词的出现仅与它之前的若干个词有关。
![]()

那么,如何计算其中的每一项条件概率 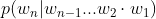 呢?答案是**似然估计**,实际就是数频数。
呢?答案是**似然估计**,实际就是数频数。
📌 根据大数定理,只要统计量足够,相对频度就等于概率。
📌 通常用相对频率作为概率的估计值。这种估计概率值的方法称为最大似然估计。
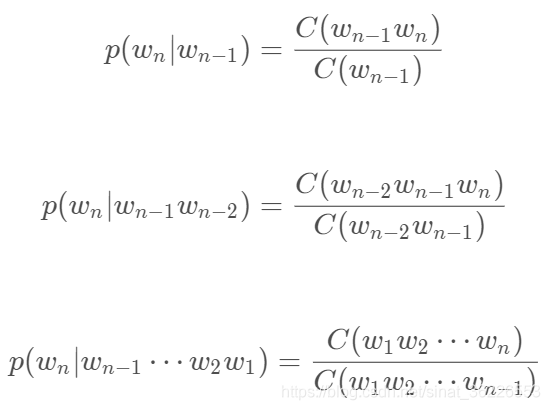
⭐ 为了解决第二个问题,我们通常会使用平滑法(如:拉普拉斯平滑、add-k 平滑) 或者回退法(backoff)。
# 2、数据平滑
N-gram的N越大,模型 Perplexity 越小,表示模型效果越好。这在直观意义上是说得通的,毕竟依赖的词越多,我们获得的信息量越多,对未来的预测就越准确。然而,语言是有极强的创造性的,当N变大时,更容易出现这样的状况:某些n-gram从未出现过,这就是稀疏问题。
N-gram最大的问题就是稀疏问题(Sparsity)。例如,在bi-gram中,若词库中有2万个词,那么两两组合就有近4亿个组合。其中的很多组合在语料库中都没有出现,根据极大似然估计得到的组合概率将会是0,从而整个句子的概率就会为0。最后的结果是,我们的模型只能计算零星的几个句子的概率,而大部分的句子算得的概率是0,这显然是不合理的。
通常有两种解决办法:
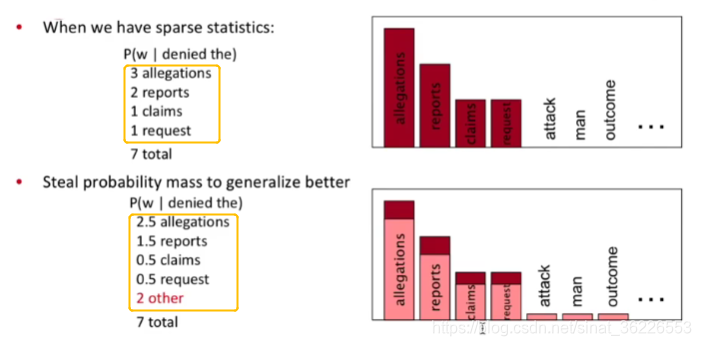
一、数据平滑(data Smoothing),数据平滑的目的有两个:一个是使所有的N-gram概率之和为1,使所有的n-gram概率都不为0。它的本质,是重新分配整个概率空间,使已经出现过的n-gram的概率降低,补充给未曾出现过的n-gram。“平滑”处理的基本思想是“劫富济贫”,即提高低概率(如零概率),降低高概率,尽量使概率分布趋于均匀。
① 古德-图灵估计的原理:对于没有看见的事件,我们不能认为它发生的概率就是零,因此我们从概率的总量中,分配一个很小的比例给予这些没有看见的事件,因此需要将所有看见的事件概率调小一点。至于小多少,要根据“越是不可信的统计折扣越多”的方法进行。
② Zipf 定律:一般来说,出现一次的词的数量要比出现两次的多,出现两次的比出现三次的多。

二、回退(backoff)和 插值(interpolation):当我们没有足够的数据使用高阶n元模型时,我们会“退回”到低阶n元模型,如:我们无法计算P(C | A,B),我们仍然可以依赖于bigram概率P(C | B),甚至是unigram概率P(C),然后通过插值(如:线性插值)混合各种n元模型,赋予它们不同的权重来估计P(C | A, B):
![]()
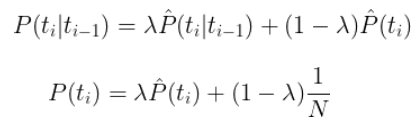
# 3、应用
1️⃣ 评估句子是否合理
# Example 1:对于一元模型(1-gram),每个词都是独立分布的,也就是对于P(A,B,C) 其中A,B,C互相之间没有交集. 所以P(A,B,C) = P(A)P(B)P(C)
比如语句:“猫跳上椅子” ,分词后得到:“猫/跳上/椅子”
P("猫","跳上","椅子") = P("猫")P(“跳上”)P("椅子");假设其中各个词的数量数语料库中统计的数量如下表所示(语料库词汇量为M):

依据这些数据就可以求出P(A,B,C),也就是这个句子的合理的概率:
# Example 2:对于二元模型,每个词都与它左边的最近的一个词有关联,也就是对于P(A,B,C) = P(A)P(B|A)P(C|B)
比如语句:“猫,跳上,椅子” ,P(A="猫",B="跳上",C="椅子") = P("猫")P(“跳上”|“猫”)P("椅子"|“跳上”);其中各个词的数量数语料库中统计的数量
依据这些图表一和图表二就可以求出P(A,B,C),也就是这个句子的合理的概率:
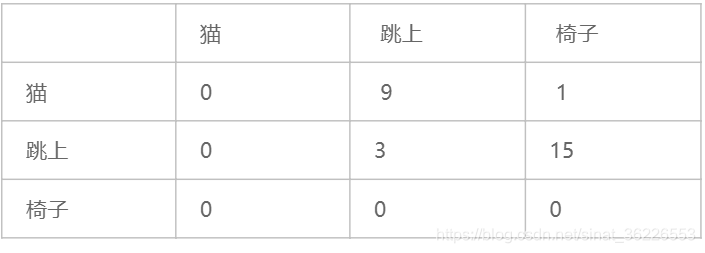
# Example 评估:对于一个训练好的模型,我们需要评估模型的好坏。评估一个模型的最佳方法是将其嵌入到应用程序中,并衡量应用程序的改进程度,这种方法叫外部评估(extrinsic evaluation),然而这种方法很消耗资源;另一种常用的叫内部评估(intrinsic evaluation),即把数据集分为训练集和测试集,评估测试集的结果。内部评估模型的指标称为复杂度perplexity (有时缩写成PP),一般有两种方法定义它,一是用下述的公式计算,二是计算任何单词后面可能出现的下一个单词的数量(一个模型的复杂度越小,每个位置的词就越确定,模型越好)。
第一种方法计算复杂度:
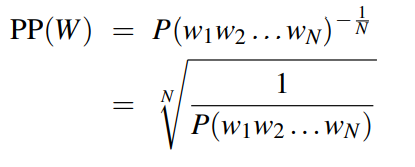
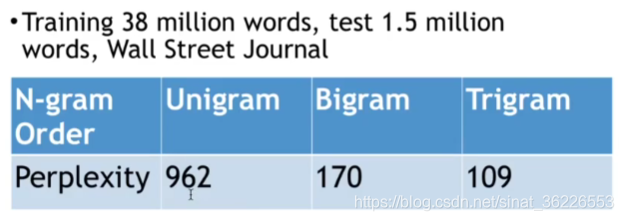
我们以上面的一元模型和二元模型来为例,进行评估计算.

单词序列的条件概率越高,复杂度越低。因此,对于语言模型,最小化复杂度等价于最大化测试集概率。
可以看出二元模型比一元模型的复杂度值要小,而复杂度值越小说明模型越好。
![]()
第二种方法计算复杂度:
2️⃣ 评估两个字符串之间的差异程度
以非重复的N-Gram分词为基础来定义 N-Gram距离这一概念,可以用下面的公式来表述:
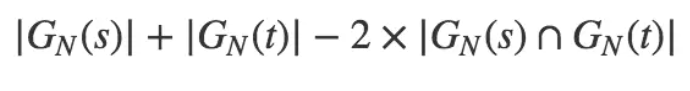
此处,|GN(s)| 是字符串 s 的 N-Gram集合,N 值一般取2或者3。以 N = 2 为例对字符串Gorbachev和Gorbechyov进行分段,可得如下结果(我们用下画线标出了其中的公共子串)
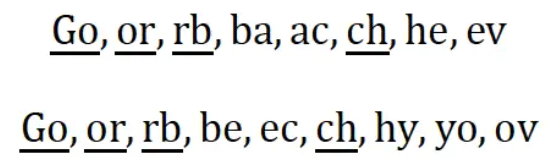
结合上面的公式,即可算得两个字符串之间的距离是8 + 9 − 2 × 4 = 9。显然,字符串之间的距离越小,它们就越接近。当两个字符串完全相等的时候,它们之间的距离就是0。
3️⃣ 其他应用
输入法、分词算法、语音识别、机器翻译等
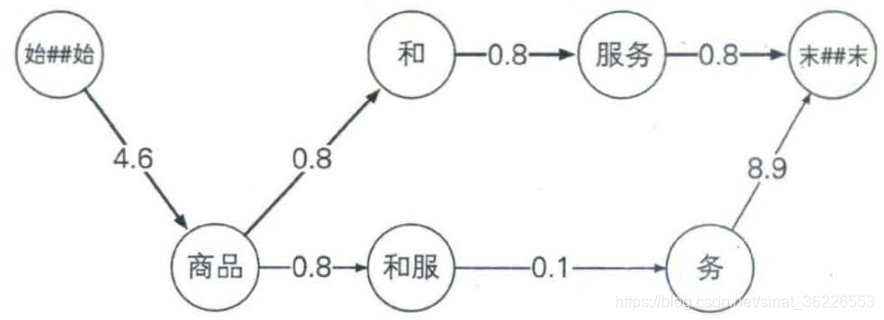
# 用N—gram模型进行中文分词
基本思想是:首先根据词典(可以是从训练语料中抽取出来的词典,也可以是外部词典)对句子进行简单匹配,找出所有可能的词典词。将它们和所有单个字作为结点,构造n元切分词图,利用n-gram求出所有可能分词路径的权值,利用动态规划思想求得最佳分词路径。
链接:语言模型与应用
# 4、缺点
1️⃣ 数据稀疏性 👉 改进办法:smoothing / backoff / 引入神经网络语言模型...
2️⃣ n越大,需要计算、统计的参数越多,占用的内存空间越大 👉 改进办法:引入马尔可夫假设,限制n的大小
3️⃣ 无法共享具有相同语义的词汇/前缀中的信息 👉 改进办法:引入词嵌入,由字符表示转向向量表示

# 神经语言模型
语言模型不需要人工标注语料(属于自监督模型),所以语言模型能够从无限制的大规模语料中,学习到丰富的语义知识。
为了缓解n元模型估算概率时遇到的数据稀疏问题,研究者们提出了神经网络语言模型NNLM。
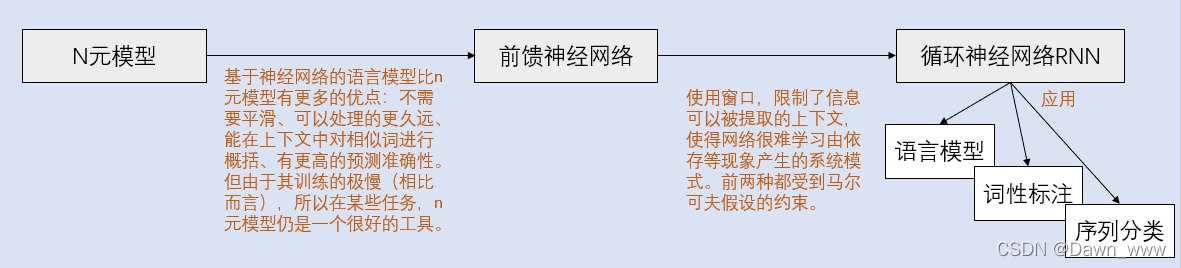
1️⃣Feed Forward Neural Language Model 代表性工作是Bengio等人在2003年提出的神经网络语言模型,该语言模型使用了一个三层前馈神经网络来进行建模。其中有趣的发现了第一层参数,用做词表示不仅低维紧密,而且能够蕴涵语义,也就为现在大家都用的词向量(例如word2vec)打下了基础 [来源]
参考文献:Yoshua Bengio, Rjean Ducharme, Pascal Vincent, and Christian Janvin. A neural probabilistic language model. Journal of Machine Learning Research, 3:1137–1155, 2003.
📌 Word2Vec是Google公司于2013年发布的一个开源词向量工具包。该项目的算法理论参考了Bengio 在2003年设计的神经网络语言模型。由于此神经网络模型使用了两次非线性变换(tanh、softmax),网络参数很多,训练缓慢,因此不适合大语料。Mikolov团队对其做了简化,实现了Word2Vec词向量模型。 ——《NLP汉语自然语言处理原理与实践》
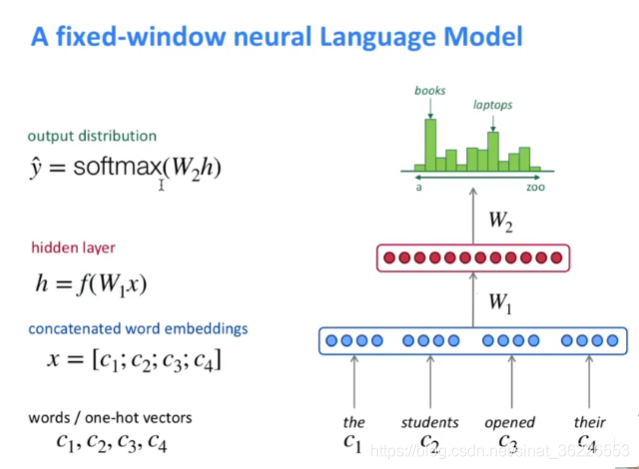
2️⃣ Mikolov 等人于 2010 年提出了 RNN 语言模型(RNNLM),理论上可以记忆无限个单词,可以看作"无穷元语法" (∞-gram)。
是否三元或者四元甚至更高阶的模型就能覆盖所有的语言现象呢?答案显然是否定的。因为自然语言中,上下文之间的相关性可能跨度非常大,甚至可以从一个段落跨到另一个段落。因此,即使模型的阶数再提高,对这种情况也无可奈何,这就是马尔可夫假设的局限性,这时就要采用其他一些长程的依赖性(Long DistanceDependency)来解决这个问题了。——《数学之美》
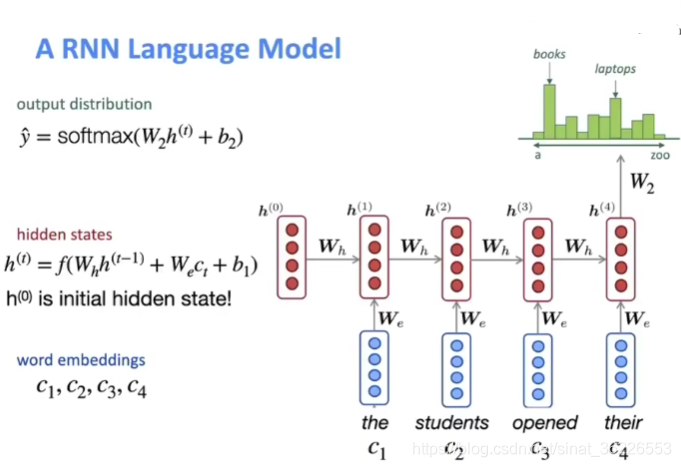
3️⃣ 2012 年,Sundermeyer 等人提出了长短期记忆循环神经网络语言模型(LSTM-RNNLM)用于解决学习长期依赖的问题。
图片截自:麻省大学《CS685 自然语言处理进阶》课程(2020) by Mohit Iyyer
# 工具

# 参考
2️⃣ 简单理解 n-gram
3️⃣ 语言模型(N-Gram)
4️⃣ N-gram的简单的介绍
5️⃣ N-Gram语言模型

















 2687
2687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









